Quick Start 2024: Stable Diffusion for Superior AI Imagery

Intrigued by how AI models breathe life into static text, transforming them into vivid visuals? Meet "Stable Diffusion," an innovative AI model making waves in image generation. This guide takes you on a journey through the inner workings of Stable Diffusion and introduces AI tools that utilize this model to create stunning images. Ready to unlock the potential of AI in image creation? Let's get started!
1. Introduction to Stable Diffusion Model
Introduction
The Stable Diffusion model, an advanced deep generative neural network, was conceptualized and brought into existence by a collaborative effort from the CompVis Group at Ludwig Maximilian University of Munich, Runway, and Stability AI. This model, released in 2022, operates under the principles of diffusion models, a class of models used in deep learning to generate new data that resembles the provided training data.
The core concept that drives this model is diffusion, akin to its namesake process in physics, which involves the spreading or dispersion of particles. In the context of Stable Diffusion, the image undergoes diffusion: transforming from an initial state to a final state through a series of small, incremental changes. The model, therefore, begins with a target image, applies random noise or perturbations, and gradually evolves the image from its original state to a final state, producing high-quality, photorealistic images conditioned on text inputs.
Stability AI, acknowledged for making Stable Diffusion an open-source image generator in August 2022, uses it as a competitor against existing image generators such as OpenAI's Dall-E and MidJourney. The unique selling point of Stable Diffusion in this competition is its status as an open-source model. Its code and model weights are publicly available, making it easily accessible to anyone equipped with basic GPU consumer hardware, given it has a minimum of 8 GB VRAM.
Key features
The deployment of Stable Diffusion involved a cross-disciplinary effort from the legal, ethics, and technology teams at HuggingFace and the engineers at CoreWeave. Key features include:
i) The model is available under a Creative ML OpenRAIL-M license, a flexible license permitting both commercial and non-commercial uses. The license highlights the ethical and legal responsibilities associated with the model's usefulness.
ii) The model also includes an AI-based Safety Classifier as part of its package. This classifier understands concepts in generated images and prevents the production of potentially unwanted outputs. It allows user-driven parameter adjustments to fine-tune the model's performance.
The model's training data comes from the 2b English language label subset of LAION 5b, a substantial internet crawl created by the German charity LAION.
Hence, Stable Diffusion can foster creativity in generating impressive visual imagery.
2. Capabilities of Stable Diffusion
Stable Diffusion exhibits a range of robust capabilities, mainly hinging on its adeptness at handling text prompts.
Image Generation:
Stable Diffusion is proficient in crafting brand-new images from scratch. The model can generate images according to textual cues, including which components to incorporate or exclude.
Guided Image Synthesis:
Beyond creating images, Stable Diffusion can also re-sketch existing images to incorporate new elements dictated by a text prompt.
For example, you can upload a picture of the sky with a text instruction: "Add some clouds and birds to this picture." This feature, also known as "guided image synthesis," is supported by the model's diffusion denoising mechanism.
Image Alteration:
Stable Diffusion can partially modify existing images by applying inpainting and outpainting techniques. This is executed in response to text prompts. To use this functionality, you need a user interface that supports such functionality and several open-source implementations that are readily available. The good news is that some AI image creators have already implemented this, allowing users to edit the images that have been generated.
Overall, Stable Diffusion goes beyond simply generating images, demonstrating a versatile capacity to synthesize, alter, and recreate images based on user-guided textual prompts.
3. How Stable Diffusion Model Works in Image Creation
The Stable Diffusion model works by starting with a target image and then applying a series of random perturbations or 'noise' to it. This noise is carefully calibrated so that it spreads or 'diffuses' across the image in a controlled manner. Over time, these random perturbations cause the image to evolve or 'diffuse' from its initial state to a final state that is a plausible sample from the data distribution. The process is reversed during sampling: starting with noise and progressively removing it to generate the final image.
"Stable" means that the model's diffusion process is stable so that the image generation results do not appear chaotic and distorted. The amount and nature of the noise applied at each step must be carefully controlled to achieve this.
You can apply Stable Diffusion Model in two ways:
AI Image Creators that use Stable Diffusion Model: Several AI image generators online use Stable Diffusion Model. You usually input some prompts or initial images, and the AI will apply the diffusion process to generate a new image. Some platforms require a subscription or payment to access, while others are free to use.
Downloading Stable Diffusion on Your Computer: Another way is to install stable diffusion directly on your computer. This method involves many steps. Also, rather than using the image generator directly, you may need to train the model on an image dataset before using it to generate images. Training is typically done by feeding the model many images for it to learn the patterns and mechanisms. The time required for training is variable, but it usually takes a long time and requires high computer functions and configurations.
Next, we will introduce these two methods in detail.
4. Noteworthy AI Image Creators that Used Stable Diffusion Model
Stable Diffusion Online
Stable Diffusion Online is a versatile tool that allows users to generate images from textual descriptions, available through a standalone application and various websites. It offers a simple and convenient way to create stunning art using Stable Diffusion.
Features
Ease of use: Users can generate images with a simple prompt with its user-friendly interface.
Fast generation: Enabled with GPU, Stable Diffusion Online can quickly generate results from a given prompt.
Privacy-focused: The platform promises not to collect or store personal information, text, or images.
Unrestricted input: There are no limitations on the kind of text prompt users can enter.
Prompt Database: The new Prompt Database feature allows users to search through over 9 million stable diffusion prompts globally, facilitating better prompt creation.
Steps to Use
Use your browser to navigate to the Stable Diffusion Online site (https://stablediffusionweb.com/) and click 'Get started for free'.
'Enter your prompt' and click the 'Generate image' button.
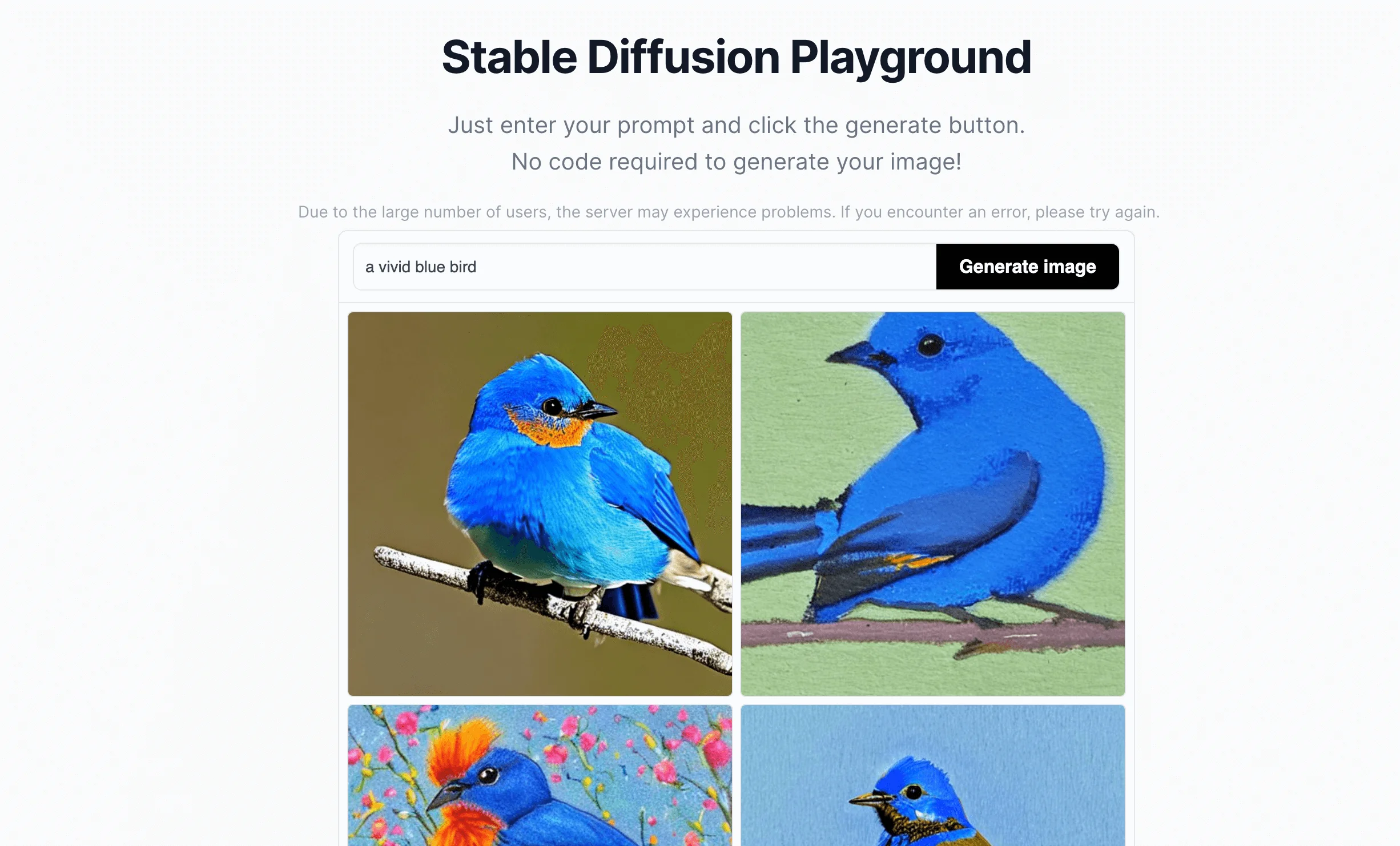
Then, you will get four images based on your prompts. You can click on any image to view it in a larger size.
If unsatisfied with the generated images, generate them again. You can also use the “Advanced options” to adjust the output in detail.
Hugging Face Stable Diffusion
Hugging Face offers an interface for the latest Stable Diffusion 2.1 model from StabilityAI. Cooperate with the developer of Stable Diffusion Online, it is also an easy-to-use platform for generating images from text prompts.
Features
Simplified interface: The tool provides a minimalist and user-friendly interface for image generation.
Solid Technical Support: Use the latest Stable Diffusion powered by StabilityAI to provide users with reliable and up-to-date technical support.
Advanced settings: The tool offers an advanced setting option - Guidance Scale, which allows users to control the influence of the text prompt on the generated image.
Steps to Use
The steps are pretty similar to the last one. Go to the Hugging Face Stable Diffusion page at https://huggingface.co/spaces/stabilityai/stable-diffusion.
Enter your prompt; you can specify text in the 'Negative prompt' field for elements you want to exclude from the image. Then click “Generate image”.

View the generated images, click on a specific one to enlarge it, and right-click to save or copy it. You can also share it with the community.
Easy Diffusion
Easy Diffusion is a simple and accessible way to install and use Stable Diffusion on your computer. It requires no dependencies or technical knowledge and offers a powerful and user-friendly web interface for free.
Features
Easy installation: Download the software and run the simple installer to get started.
Creating images: Generate beautiful images from your text prompts, or use existing images to guide the AI.
Active community: Join the active Discord community to explore the endless possibilities of AI-generated images.
Supports text-to-image and image-to-image tasks: Use multiple samplers, try out in-painting, use a simple drawing tool, and take advantage of face correction and upscaling features.
Customization and advanced features: Use custom models, UI plugins, and merge models, among other features.
Steps to Use
System Requirements
Windows 10/11, Linux or Mac.
An NVIDIA graphics card, preferably with 4GB or more of VRAM or an M1 or M2 Mac. But if you don’t have a compatible graphics card, you can still use it with a “Use CPU” setting. It’ll be very slow, but it should still work.
8GB of RAM and 20GB of disk space.
You do not need anything else. You do not need WSL, Docker or Conda. The installer will take care of it.
Here are the steps:
Download the Easy Diffusion by visiting https://stable-diffusion-ui.github.io/, If you have problems with the installation, visit the official guide at https://stable-diffusion-ui.github.io/docs/installation/
After installing the software, navigate to http://localhost:9000 on your browser (Chrome, Edge, or Firefox recommended).
Now you can enter your prompts and negative prompts, then click 'Make Image'.
Tips:
It can process multiple jobs sequentially, so you can enter more than one prompt.
Face Correction or Upscaling can enhance the image further.
You can refine the generated images by using them as the input images for the next generation task.
Clipdrop:
Stable Diffusion XL (SDXL) by Stability AI, the latest advancement in AI image generation, is available through ClipDrop. ClipDrop is an ecosystem of apps, plugins, and resources for creators powered by AI. It allows users to generate images from text and offers various image editing features. Moreover, it offers many prompts as examples, which can help users familiar with the tool quickly.
Features
Ease of use: Clipdrop Stable Diffusion XL provides an intuitive interface for users.
API available: The ClipDrop API allows developers to integrate Stable Diffusion capabilities into their applications.
Enhanced image generation: It features text-to-image generation using the Stable Diffusion XL (SDXL) AI, ensuring higher quality results.
Versatile image editing features: Users can use editing features such as cropping, resizing, filtering, and more to modify the generated images.
Multiplatform: ClipDrop Stable Diffusion XL is available on the web, Android, iOS, and desktop.
Steps to Use
Navigate to the ClipDrop Stable Diffusion XL page: https://clipdrop.co/stable-diffusion.
Enter your prompt, then click on the 'Generate' button.
Then you will get four images.
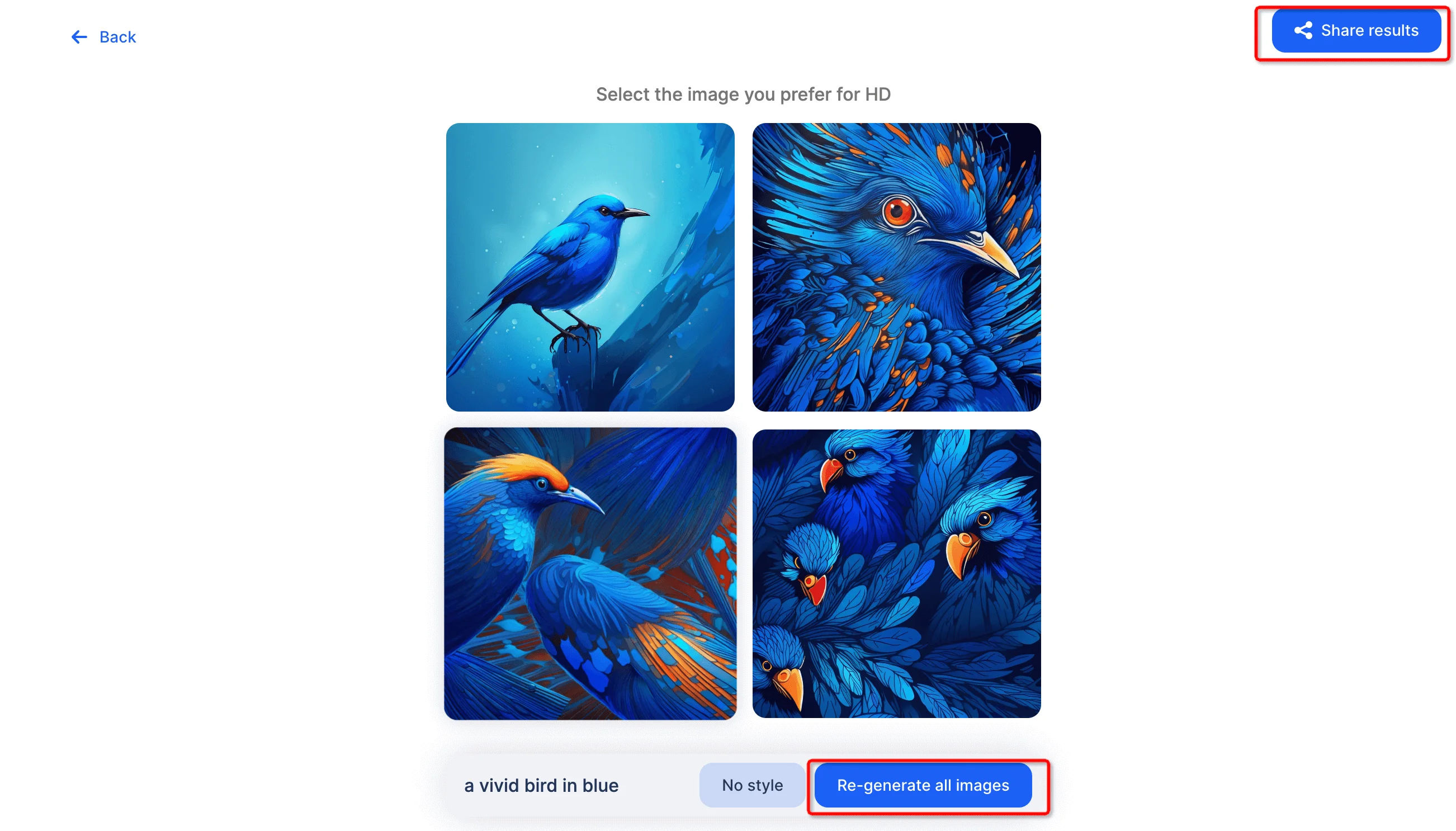
Once the image has been generated, you can download, share, or modify it using the editing tools provided. If you are not satisfied with it, you can re-generate all images.
Tips: You can set the style of the generation.
DreamStudio
DreamStudio offers a versatile Stable Diffusion platform with various creative features. You can generate images from textual prompts with several options to influence the output.
Features
Customizable generation: DreamStudio offers advanced settings such as prompt strength, speed, and seed.
Free credits: Upon sign-up, users are given free credits that can be used to generate images.
Style library: It allows users to apply various styles to their generated images.
Negative prompt: This feature allows users to specify aspects that they don't want in their image.
Photo-based generation: Apart from text, users can also create images based on an existing photo.
Steps to Use
Visit the DreamStudio website: https://dreamstudio.ai, and click "Login" in the upper right corner, then choose “Sign Up” for a new account. You can log in with your Google or Discord account if you already have one.
Enter your prompts, you can also make specific adjustments, like image number, or style.
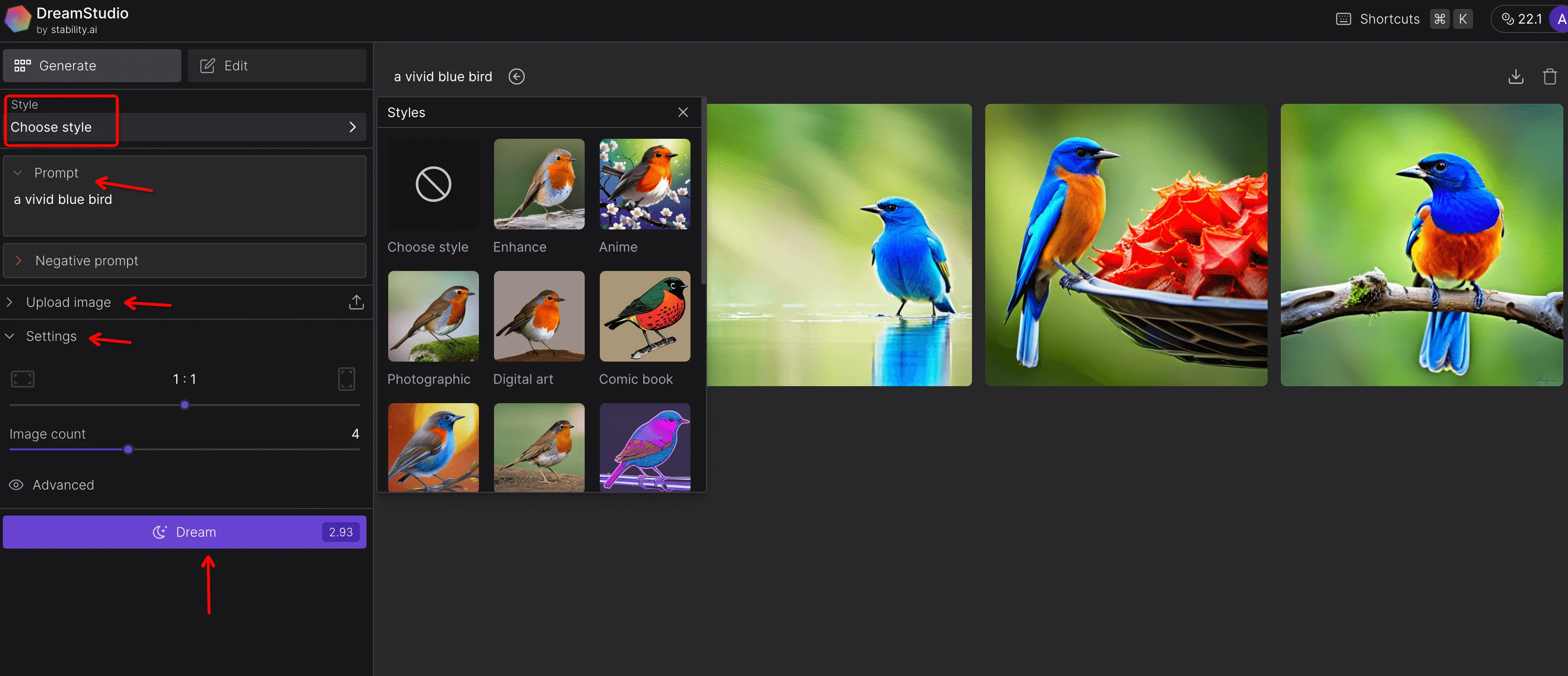
Click the 'Dream' button to generate your image.
Review the generated images, select a specific one to view it in a larger size, and save or copy it.
You can also use it to edit the images. Select the image, then click “Edit image”.
Then you can start the editing.
5. How to Download and Install Stable Diffusion on Your Computer
Besides using various online platforms and software that rely on the stable diffusion model, installing the model directly on the computer is possible. The user can also use this to generate images. This approach is technically challenging, but the benefit is that it gives the user more control and flexibility. With it, you can generate images for free anytime, anywhere, without restrictions on third-party platforms. Plus, it provides an added security advantage, especially when working on sensitive projects.
Below are detailed instructions on how to install the model. It is important to note that the various installations and file configurations involved in these steps require a certain amount of technical knowledge of the user and a computer. Please read carefully and operate with caution. Let's start:
Requirements
Ensure your PC meets the minimum requirements:
- Operating System: Windows 10 or 11
- Hardware: A discrete NVIDIA video card with 4GB or more of VRAM.
To check your video card's model and the VRAM amount, use the DirectX Diagnostic Tool and follow the steps below:
Press `Win key+R` to trigger the Run box.
In the Open field, type `dxdiag`.
In the DirectX Diagnostic Tool window, click the Display tab to see the name of your card and the amount of VRAM.
Step-by-Step Guide
Step 1: Install Python and Git
Visit the Python 3.10.6 website at https://www.python.org/.
Click the “Downloads” section.
Scroll down to find the 3.10.6 release version; click to visit it.
Then choose the link for your computer accordingly. We take the Windows installer (64-bit) as an example, assuming you're running 64-bit Windows.
Run the downloaded file to install Python.
Next, visit the Git for Windows download page at https://gitforwindows.org/.
Select the 64-bit Git for Windows Setup link.
Execute the downloaded installer, agreeing to all the default options.
Step 2: Download the Stable Diffusion project file
Download the Stable Diffusion project file by heading over to its GitHub page at https://github.com/OpenAI/stable-diffusion
Click on the green Code button located in the upper right corner, then choose Download ZIP.
Once downloaded, unzip the ZIP file to get a folder named stable-diffusion-webui-master.
Move this folder along with its contents to a straightforward location, such as the root directory of your C: drive.
Step 3: Acquire and Setup the Checkpoint File
Go to the Hugging Face website at https://huggingface.co/spaces/stabilityai/stable-diffusion to access the checkpoint file for Stable Diffusion.
Click on the download link to obtain the 768-v-ema.ckpt file. Be patient as this is a large file and might require some time to download.
Once downloaded, head to C:stable-diffusion-webui-mastermodelsStable-diffusion (provided you moved the folder to your C: drive's root).
Within this directory, locate the file named Put Stable Diffusion checkpoints file here.txt. Place the 768-v-ema.ckpt file into the same folder.
Step 4: Retrieve the Config Yaml File
Access the relevant webpage to download the config yaml file.
You will see the file in plain text format. Right-click on the page and choose Save as.
Go to folder C:stable-diffusion-webui-mastermodelsStable-diffusion and store the yaml file there.
Rename this file to 768-v-ema while preserving the yaml extension, yielding the final filename: 768-v-ema.yaml.
Step 5: Launch the webui-user.bat File
Head to the stable-diffusion-webui-master directory and initiate the webui-user.bat file.
After a short wait, a local URL will appear in the window. Copy this URL and paste it into your web browser to access the Stable Diffusion interface.
Step 6: Create an Image
In the Stable Diffusion interface, input a detailed description of the image you wish to generate.
Specify any text you'd prefer to exclude in the 'Negative prompt' field.
If necessary, fine-tune the parameters such as 'Sampling method', 'width', 'height', 'Batch count', and 'Batch size'.
Click the 'Generate' button to produce your image.
The Stable Diffusion platform also provides extra functionalities, such as image uploading for creating variations, image scaling and adjustment, and compatibility with multiple extensions.
6. Limitations of Stable Diffusion
Despite its impressive capabilities, Stable Diffusion exhibits shortcomings that may influence its efficiency and effectiveness.
Image Quality and Resolution:
The model was initially trained on a dataset comprising images of 512x512 resolution. As a result, image quality noticeably degrades if user specifications deviate from this resolution. However, a subsequent update (version 2.0) has improved the native image generation resolution to 768x768.
Human Limb and Face Generation:
Another challenging area to generate stable diffusion results is human limbs and faces. Due to the poor representation of these features in the LAION database used to train the model, Stable Diffusion is prone to significant inaccuracies when dealing with prompts related to human limbs and facial images.
Inability to Achieve Perfect Photorealism:
Although Stable Diffusion can generate impressively realistic images, it falls short of perfect photorealism.
Stable Diffusion still has room for improvement in terms of image realism, although its current generation results are already impressive. This photorealistic imperfection also has implications for completing more compositional prompts, potentially causing the model to underperform when handling such instructions.
For example: let's use "green cube on top of red sphere" as the prompt.
Stable Diffusion Online:
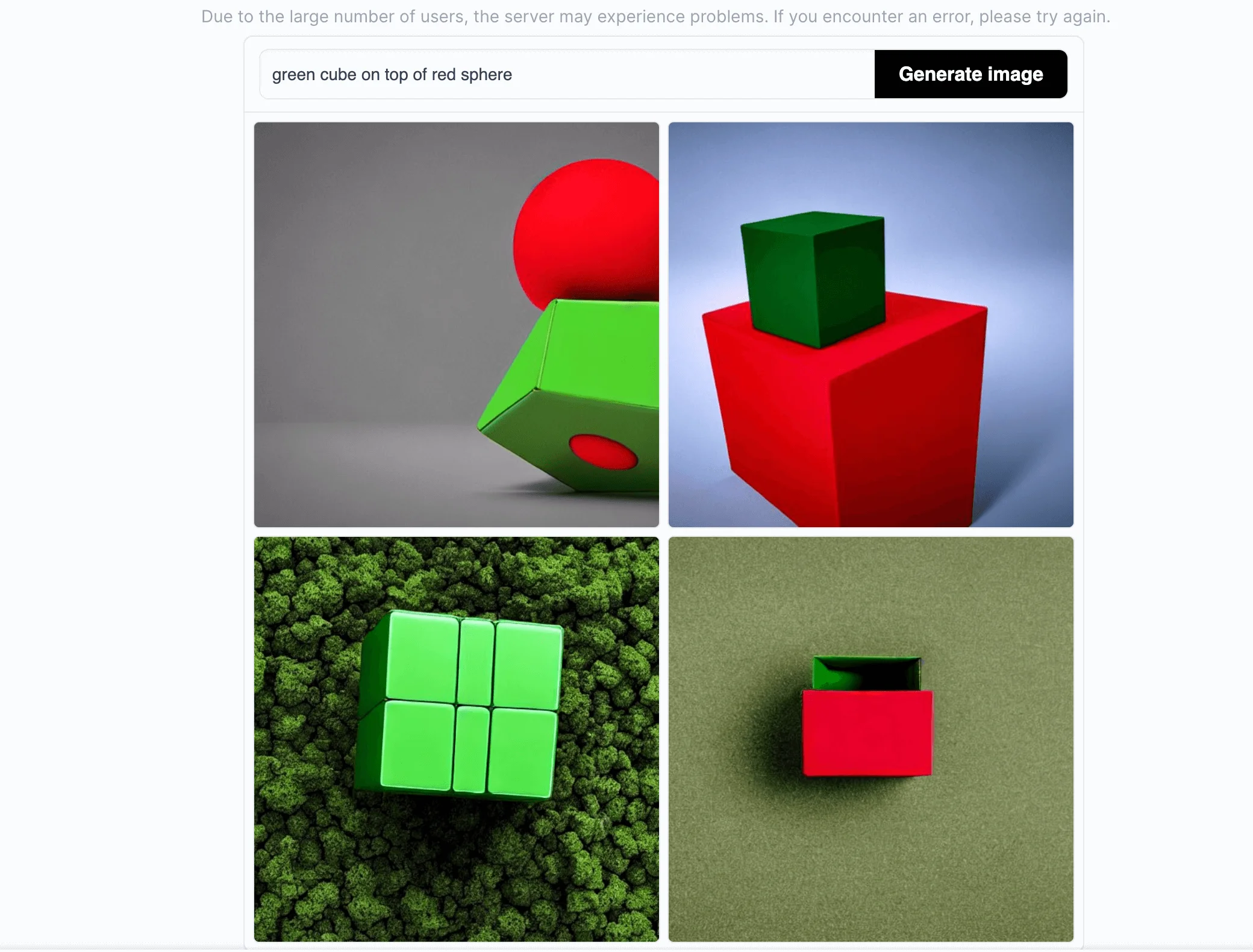
Midjourney:
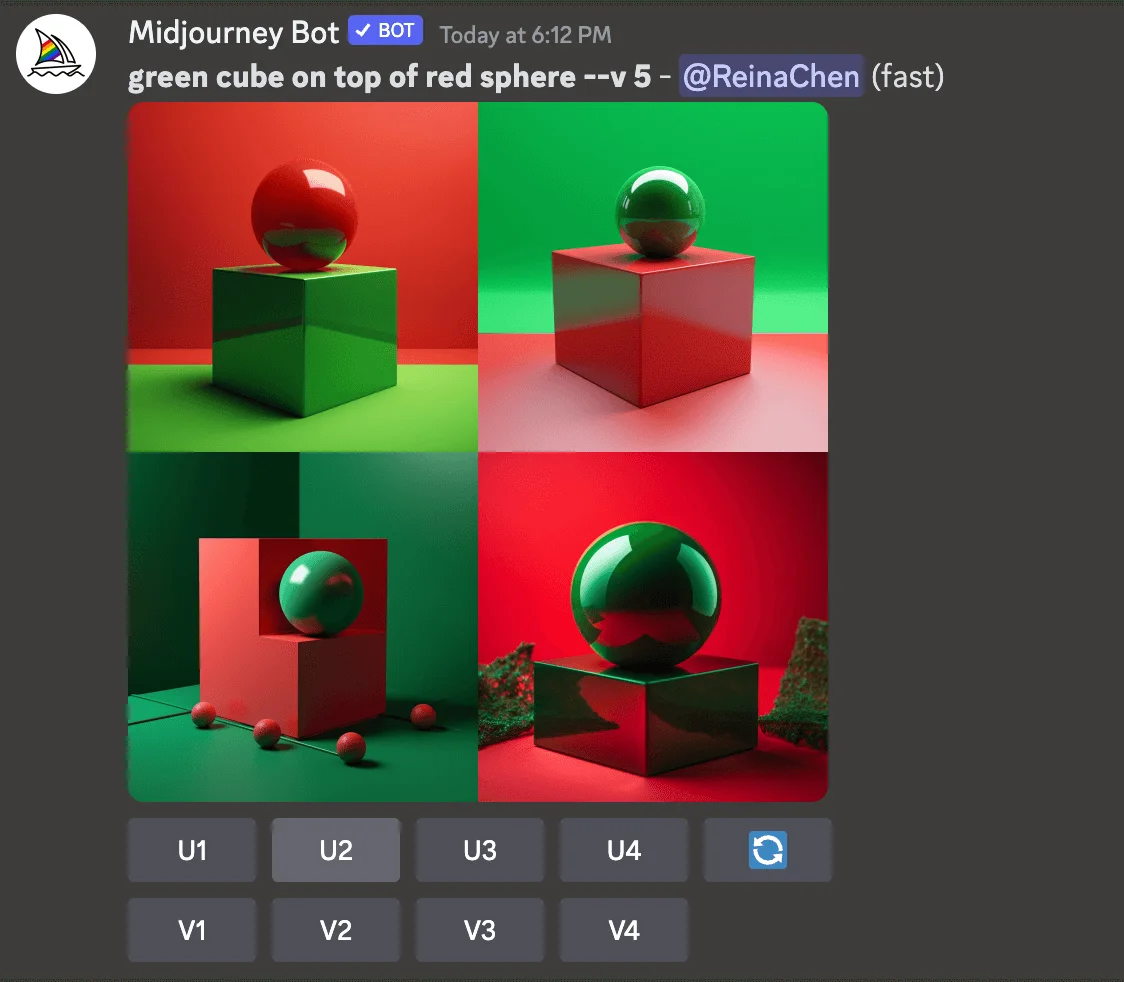
Algorithmic Bias:
An inherent limitation of Stable Diffusion lies in its algorithmic bias. The model was primarily trained on images accompanied by English descriptions, leading to an inherent Western bias in the generated images. Consequently, prompts in languages other than English are likely to yield less accurate results, with Western or white cultures often being the default representation.
Data Loss and Memorization:
The model’s autoencoding mechanism is lossy, which can degrade image quality. Moreover, no measures were taken to deduplicate the dataset during training, leading to the potential memorization of duplicated images.
Safety Considerations:
The model was trained on the large-scale dataset LAION-5B, which contains adult material. As a result, the model may not be suitable for product use without additional safety mechanisms and considerations.
These limitations underline the need for further improvements in Stable Diffusion to ensure it can handle a broader range of tasks while mitigating biases and enhancing data safety.
7. Comparison: Midjourney vs. Stable Diffusion (consider using a table here)
Here's a summarized comparison between Midjourney and Stable Diffusion, two popular AI image generators:
Feature | Midjourney | Stable Diffusion |
|---|---|---|
Machine Learning Model | Proprietary | Open-source |
Usage | Requires internet, accessible via Discord | Can be used offline if downloaded |
Cost | Minimum $10/month for limited image generations | Free if run on own hardware, nominal fee for online services |
Custom Models | Supports a handful | Supports thousands of downloadable custom models |
Ease of Use | Easier with fewer settings | More advanced features and customization options |
Image Quality | High-quality images that match text prompts | Can match or exceed Midjourney's results with adjustments |
Art Styles | Offers an anime-optimized model | Allows download of custom models trained in various art styles |
Explicit Content | May ban accounts for explicit or suggestive prompts | Allows workarounds for explicit content with custom models |
As for image quality, both performed well, with accurate results. But from my point of view, Midjourney has better results for the same and more complex prompts. In addition, Midjourney relies on the Discord application, and its famous public room can enhance communication with users around the world. However, the Stable Diffusion also has great potential, so it's a good bet to try both generators together to help improve your efficiency.
8. FAQs
1. What Dataset Was the Stable Diffusion Model Trained On?
The Stable Diffusion model was trained on the 2b English language label subset of LAION 5b, a general internet crawl created by the German charity LAION【9†source】.
2. What Is the Copyright For Using Stable Diffusion Generated Images?
The copyright related to AI-generated images, such as those created by Stable Diffusion, is a complex issue that can vary depending on the jurisdiction.
3. Can Artists Opt-In or Opt-Out to Include Their Work in the Training Data?
Artists had no option to opt-in or opt-out for the LAION 5b model data. This dataset is intended to be a general representation of the language-image connection on the Internet.
4. What Is the Copyright on Images Created Through Stable Diffusion Online?
Images created through Stable Diffusion Online are completely open source, falling explicitly under the CC0 1.0 Universal Public Domain Dedication.
5. What Kinds of GPUs Will Be Able to Run Stable Diffusion, and at What Settings?
Most NVidia and AMD GPUs with a minimum of 6GB can run Stable Diffusion.
Conclusion
In conclusion, Stable Diffusion represents a significant leap in AI-driven image generation, offering a rich avenue for creativity and innovation. Its unique approach of using diffusion models to generate high-quality, photorealistic images offers immense possibilities for various applications, from art and design to advertising. It democratizes access to AI technologies as an open-source tool, allowing anyone with basic GPU-equipped hardware to create stunning visuals. However, with its power comes a responsibility to use it ethically and legally, as emphasized by the model's licensing terms. As we continue to explore and harness the capabilities of such advanced AI tools, we are opening doors to new frontiers of creativity and imagination. Happy creating with Stable Diffusion!