How Does ChatGPT Work? Your 5-Minute Guide to AI - 2024

Curious about the AI that's revolutionizing conversations? Ever wondered how ChatGPT manages to understand your questions and craft coherent responses? Dive into the intricate workings of this groundbreaking technology, from its GPT foundation to the role of Natural Language Processing and beyond. Explore its performance, limitations, and future possibilities. Unravel the science behind your digital conversational partner, ChatGPT.
1. About GPT & ChatGPT
1.1. Defining GPT Models
GPT, or Generative Pre-trained Transformers, is a significant development in artificial intelligence. They're utilized in numerous generative AI applications, including ChatGPT. Built on the transformer architecture, GPT models can produce human-like text and other types of content like images and music. Plus, you can use it to answer questions, have conversations with them, handle everything text-related, and more.
1.2. Introduction to ChatGPT
ChatGPT is a derivative of GPT models, developed by OpenAI. It operates similarly to its sibling model, InstructGPT, but with a conversational approach. The uniqueness of this difference gives ChatGPT an interactive function, enabling it to communicate with users and further complete question answering, error identification, etc.
1.3. Comparing ChatGPT with Search Engines
Search engines like Google and computational engines like Wolfram Alpha also interact with users via a single-line text entry field. However, while Google's strength lies in executing vast database lookups to provide a series of matches and Wolfram Alpha is equipped to parse data-related questions and perform calculations, ChatGPT's strength is the ability to parse queries and deliver comprehensive answers based on a vast amount of digitally accessible text information.
For example, searching for "how to unlock an iPhone" on search engines like Google, you will get articles with solutions created by different websites. You need to go through these articles to get the solution.
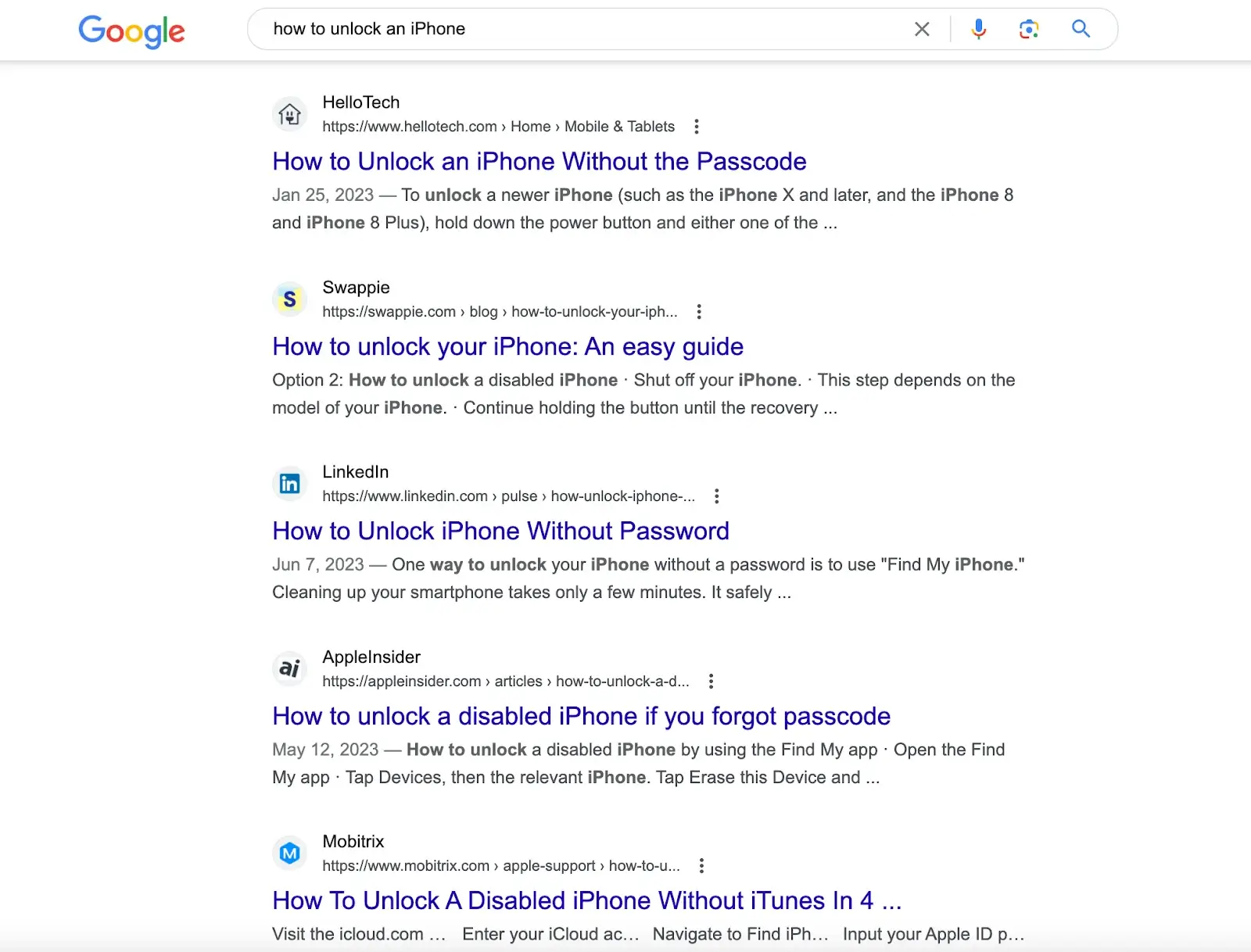
But if you enter this question into ChatGPT, it will directly feed you the answer. The answer comes from its pre-trained data set, which also contains the content in the link provided by the search engines.
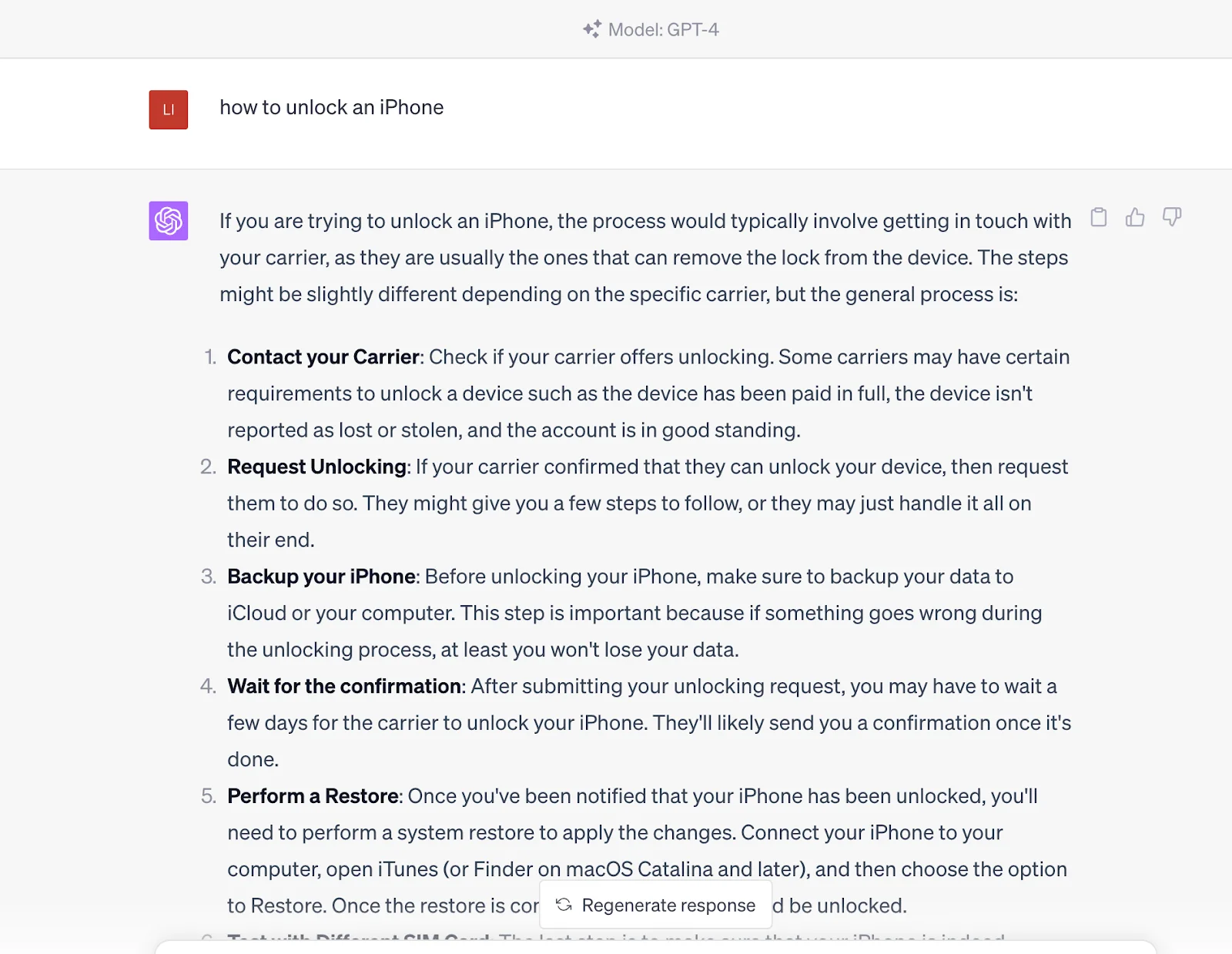
In other words, you communicate with a knowledgeable entity that can generate query results rather than just getting those content sources through search engines. However, it should be noted that it is currently inferior to search engines in terms of timeliness because the information of ChatGPT is based on the data trained as of 2021.
2. How Does ChatGPT Work
The functioning of ChatGPT is divided into two phases: pre-training, or data gathering, and inference, or responding to user prompts. As we discussed before, ChatGPT is similar to Google. After extensive training, ChatGPT can understand questions and generate answers from its database. The only difference is that it will generate direct answers, not links when you send a prompt.
ChatGPT employs deep-learning neural networks to generate human-like text. Like the human brain making predictions and drawing conclusions based on prior knowledge, ChatGPT is trained on an immense amount of data, or tokens, essentially units of text that can represent single words or parts of complex ones.
Unlike traditional AI models trained using a supervised approach pairing each input with a specific output, ChatGPT uses an unsupervised pretraining approach. Here, the model learns the inherent structure and patterns in the input data without having a particular task in mind, thus understanding the syntax and semantics of language and enabling it to generate meaningful text conversationally. This pretraining is the transformative power behind ChatGPT's vast knowledge and capabilities. The model can develop a wide range of responses based on the received input by processing colossal amounts of data using transformer-based language modeling. This methodology forms the foundation of ChatGPT's seemingly limitless knowledge and conversational abilities.
This training begins by exposing the model to vast amounts of human-written content—from books and articles to internet content. The model thus learns patterns and relationships from these tokens, forming a deep-learning neural network. This network, similar to a multi-layered algorithm that imitates the human brain's functioning, enables the model to generate contextually relevant and human-like text.
What is remarkable about ChatGPT is its ability to generate long texts instead of just predicting the next word in a sentence. OpenAI revealed its ability to train ChatGPT in this regard through reinforcement learning from human feedback (RLHF), allowing it to generate entire sentences, paragraphs, and even longer text strings to generate coherent responses. This training involves a reward model in which the trainer ranks the different reactions generated by the model to help the AI understand what constitutes a good response.
Another strength supporting the operation of ChatGPT is its massive number of parameters. GPT-3 is 175 billion, and GPT-4 did not reveal the specific number, but it can be speculated that it may be more. Every prompt the user sends needs to be processed by these parameters, and the output will be affected by its value and weight. Additionally, randomness has been incorporated into these parameters to avoid mechanical, repetitive responses and keep things fresh. For example, you can use the same prompt and generate different results.
3. Reinforcement Learning from Human Feedback (RLHF)
According to the OpenAI, the raining of ChatGPT is largely based on the Reinforcement Learning from Human Feedback (RLHF) method. This method involves a series of distinct steps to produce a model that can generate desirable responses.
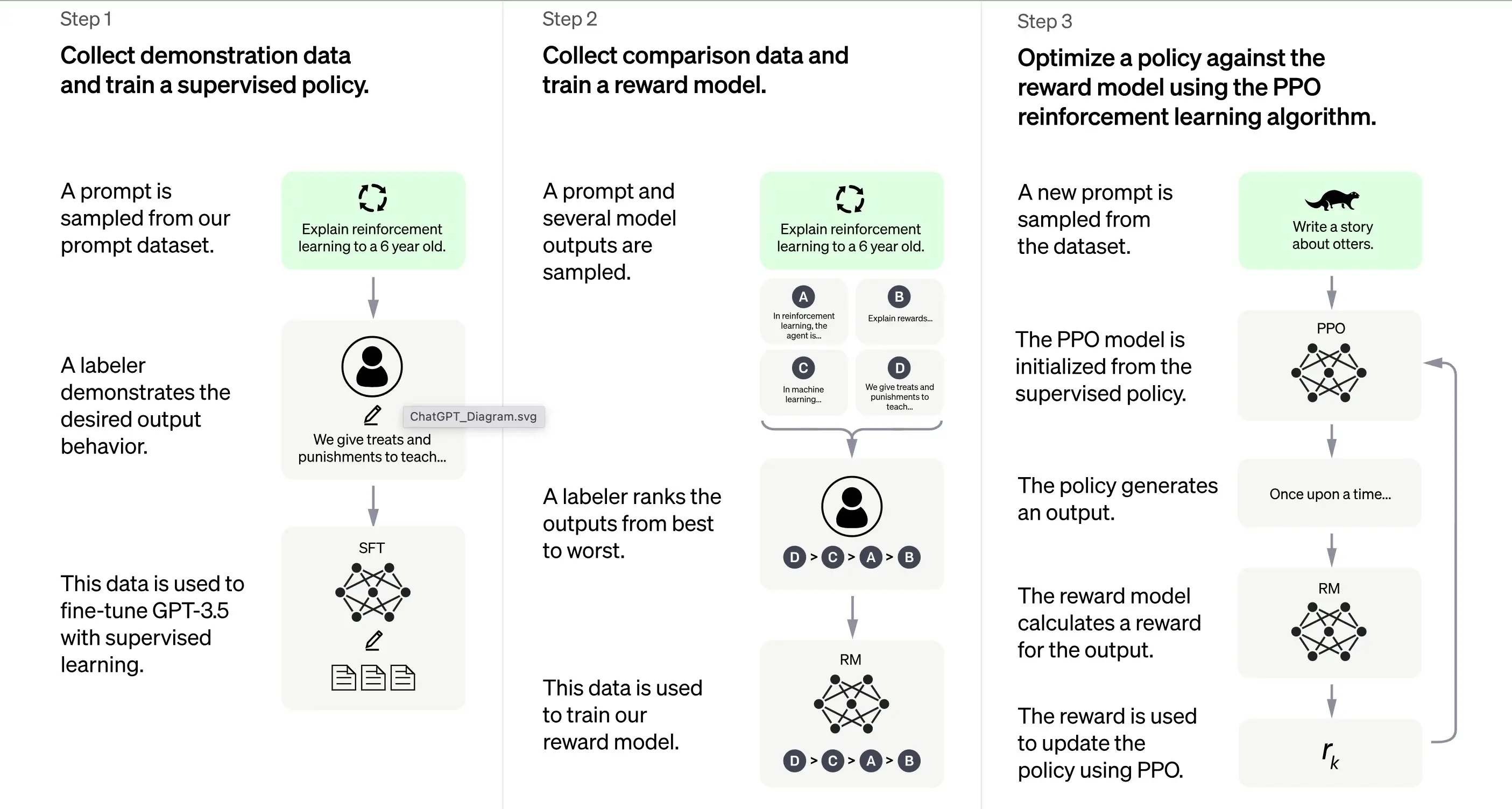
3.1. Initial Training: Supervised Fine-Tuning (SFT)
The first step in training ChatGPT is Supervised Fine-Tuning (SFT). This phase involves using a small, carefully curated dataset composed of prompts and their corresponding responses produced by human labelers. The training aims to output high-quality correct output to ChatGPT. According to OpenAI, the training model at this stage is based on the GPT-3.5 series model.
The first step in training ChatGPT is Supervised Fine-Tuning (SFT), a supervised policy model trained by collecting demonstration data from human labelers. ChatGPT uses two sources of prompts: direct labeling from developers or OpenAI's API requests. The resulting small, high-quality curated dataset is used to fine-tune a pretrained language model. Instead of fine-tuning the original GPT-3 model, ChatGPT developers chose a pretrained GPT-3.5 series model, likely text-davinci-003. This decision was made to create a general-purpose chatbot like ChatGPT on top of a "code model" rather than a pure text model.
However, the SFT model may still be not user-attentive and suffer from misalignment. To overcome this issue, the developers now rank different outputs of the SFT model to create a reward model.
3.2. Generating the Reward Model
The step is designed to generate an objective function, the reward model. This model scores the outputs of the SFT model, with a score proportional to how much the class expects those outputs. The more expectations are met, the higher the score, and vice versa.
Labelers will manually score the output of the SFT model according to specific preferences and common criteria they agree to follow. Ultimately, this process helps create an automated system that can mimic human preferences.
The advantage of this method is that it is extremely efficient. Because the labelers only need to rank the output instead of using the model to produce content from scratch.
Its workflow is roughly as follows:
Select a list of prompts, and the SFT model generates multiple outputs (any output between 4 and 9) for each prompt.
The labeler ranks the outputs from best to worst, creating a new labeled dataset with the "ranks" as labels. This dataset is about ten times larger than the curated dataset used by the SFT model.
This dataset will then train the Reward Model (RM). The model takes as input some SFT model outputs and ranks them in order of preference.
So far, we've discussed how the model is initially trained using supervised fine-tuning and then refined using a reward model. These steps form the basic building blocks for training ChatGPT. However, the process continues beyond there. The system then enters a phase of iterative improvement through a technique called Proximal Policy Optimization.
3.3. Iterative Improvement: Proximal Policy Optimization (PPO)
The final training stage involves applying Proximal Policy Optimization (PPO). This technique uses the reward model as a value function to estimate the expected return of an action. It then applies an "advantage function," representing the difference between the expected and actual returns, to update the policy.
PPO is an "on-policy" algorithm that learns from and updates the current policy based on the agent's actions and the rewards received. This design helps ensure stable learning by constraining the extent of change in the policy during each update, preventing the model from making drastic changes that could disrupt the learning process.
The PPO model begins with the SFT model and initializes the value function from the reward model. In this environment, a random prompt is presented, and a response is expected. Once the response is given, the episode ends with the reward, determined by the reward model.
3.4. Continual Learning: The Iterative Cycle
Except that the first step only occurs once, the reward model generation and PPO stages are repeated in cycles. This iterative approach allows for continuous improvement of the model over time. With each cycle, the model collects more comparison data, trains a new reward model, and establishes a new policy. As a result, the model improves at aligning with human preferences over time.
4. The Transformer Architecture: A Foundation for ChatGPT
4.1. An Overview
The underpinning of ChatGPT is a type of neural network called transformer architecture. A neural network, in essence, emulates the way the human brain works by processing information through multiple layers of interconnected nodes. Picture a symphony orchestra: each musician has a role, passing melodies (information) back and forth, all harmonizing together to create music (an output).
The transformer architecture specializes in processing sequences of words by leveraging a mechanism known as "self-attention." The self-attention mechanism is akin to the way a reader might revisit a prior sentence or paragraph to comprehend the context of a novel word or phrase. The transformer assesses all the words in a sequence to discern the context and relationships between them.
4.2. Layers of the Transformer
The transformer architecture consists of multiple layers, each composed of two primary sub-layers: the self-attention layer and the feedforward layer. The self-attention layer calculates the relevance of each word in a sequence, while the feedforward layer applies non-linear transformations to the input data. Through this configuration, the transformer learns to comprehend and navigate the relationships among the words in a sequence.
4.3. Training the Transformer
During training, the transformer is provided with input data (a sentence, for instance) and asked to predict an outcome based on that input. The model is then updated according to how closely its prediction aligns with the output. In this way, the transformer hones its ability to understand the context and relationships between words in a sequence.
It's like teaching a child new words: you present them with new words (input), they make a guess about the meaning (prediction), and you correct them if they're wrong (updating the model), thereby aiding their language acquisition process.
4.4. Challenges When Using It
However, like any powerful tool, transformer architecture comes with its challenges. The potential for these models to generate harmful or biased content is a significant concern, as they can inadvertently learn and perpetuate biases present in the training data. Think of a parrot that mimics whatever it hears, regardless of the appropriateness or political correctness of the words.
The developers of these models strive to incorporate "guard rails" to mitigate these risks. Still, these guard rails might lead to new issues due to diverse perspectives and interpretations of biases.
As we all know, ChatGPT's power generation ability benefits from the large data sources of its GPT model, so next, we will discuss the data that provides support for ChatGPT.
5. The Role of Diverse Datasets
5.1. ChatGPT: A Product of Extensive Pretraining
ChatGPT, which stands on the shoulders of the GPT-3 (Generative Pre-trained Transformer 3) architecture, is a robust language model powered by the monumental dataset, WebText2. To understand the scale, imagine a library filled with over 45 terabytes of text data, equivalent to thousands of times the content of Wikipedia.
The colossal scale of WebText2 allows ChatGPT to learn patterns and associations between words and phrases at an unimaginable scale, enabling it to generate coherent and contextually relevant responses.
5.2. Fine-tuning ChatGPT for Conversations
While ChatGPT inherits its backbone from the GPT-3 architecture, it has been fine-tuned and optimized for specific conversational applications. This results in a more engaging and personalized interaction experience for users interacting with ChatGPT.
OpenAI, the creators of ChatGPT, has made available a unique dataset called Persona-Chat, designed specifically for training conversational AI models. This dataset consists of over 160,000 dialogues between human participants; each assigned a distinctive persona outlining their interests, personality, and background. It's as if ChatGPT was a participant in thousands of role-play scenarios, learning how to tailor its responses to the context and persona of the conversation.
5.3. A Variety of Datasets: The Secret Sauce
Aside from Persona-Chat, ChatGPT is fine-tuned using several other conversational datasets:
Cornell Movie Dialogs Corpus: This dataset houses dialogues between characters in movie scripts, with over 200,000 conversational exchanges among more than 10,000 character pairs. Think of it as ChatGPT studying the scripts of hundreds of movies, absorbing the linguistic nuances of different genres and contexts.
Ubuntu Dialogue Corpus: A compilation of multi-turn dialogues between users seeking technical support and the Ubuntu community's support team. This data can simulate tech support conversations to help ChatGPT learn specific terminology and problem-solving methods. And this conversation a million times.
It's as if ChatGPT sat in on over a million technical support conversations, learning the specific terminology and problem-solving approaches.
DailyDialog: This dataset comprises human dialogues on various topics, from daily life chats to discussions on social issues. Using this database, ChatGPT is like joining countless discussions to understand the tone, mood, and themes that make up everyday human conversation.
In addition, ChatGPT leverages a vast amount of unstructured data found on the internet, including books, websites, and other text sources. This broadens its understanding of language structure and patterns, which can be fine-tuned for specific applications like sentiment analysis or dialogue management.
5.4. The Scale of ChatGPT
Though similar in approach to the GPT series, ChatGPT is a distinct model with differences in architecture and training data. ChatGPT comprises 1.5 billion parameters, smaller in scale than GPT-3's staggering 175 billion parameters, but nonetheless impressive.
To summarize, the training data for fine-tuning ChatGPT is predominantly conversational, curated to include dialogues between humans, enabling ChatGPT to generate natural, engaging responses. Think of its unsupervised training like teaching a child to communicate by exposing them to a myriad of conversations and letting them find patterns and make sense of it all.
After pre-training, ChatGPT also needs to be able to understand questions and construct answers from the data. This involves the inference phase, supported by natural language processing and dialogue management; let's find out.
6. Natural Language Processing:
Natural Language Processing (NLP) is a subfield of artificial intelligence that focuses on enabling computers to understand, interpret, and generate human language. It is a critical technology in today's digital age, as it underlies many applications such as sentiment analysis, chatbots, speech recognition, and language translation.
NLP technologies can significantly benefit businesses by automating tasks, enhancing customer service, and extracting valuable insights from data sources like customer feedback and social media posts.
However, human language is inherently complex and ambiguous, presenting computer interpretation difficulties. To tackle this, NLP algorithms are trained on vast amounts of data, enabling them to recognize patterns and learn language nuances. These algorithms must also be constantly refined and updated to keep pace with the ever-evolving use of language and its context.
NLP breaks down language inputs (e.g., sentences or paragraphs) into smaller components and analyzes their meanings and relationships to generate insights or responses. It employs various techniques, including statistical modeling, machine learning, and deep learning, to discern patterns and learn from large data quantities, thereby accurately interpreting and generating language.
ChatGPT is a practical example of NLP in action. It is designed to engage in multi-turn conversations with users that feel natural and engaging. This involves using algorithms and machine learning techniques to understand the context of a conversation and maintain it over multiple exchanges with the user.
This capability of maintaining a context over an extended conversation is known as Dialogue Management. It allows computer programs to interact with people in a manner that feels more like a conversation than a series of one-off interactions. This aspect of NLP is vital as it builds trust and engagement with users, leading to better outcomes for both the user and the organization using the program.
7. Performance Evaluation of ChatGPT
Three Core Criteria
The evaluation of ChatGPT is a crucial step in ensuring its effectiveness and reliability. Since the model is trained based on human interactions, its evaluation also predominantly relies on human input, wherein quality raters assess the model's outputs.
To prevent the model from overfitting to the judgment of the raters who participated in the training phase, the evaluation employs a test set comprising prompts from OpenAI's user base that are not included in the training data. This allows for an unbiased assessment of the model's performance in real-world scenarios.
The model's evaluation is conducted across three core criteria:
Criteria | Explanation |
|---|---|
Helpfulness | This measures the model's ability to comply with user instructions and intuit the user's intentions. |
Truthfulness | This assesses the model's proclivity for 'hallucinations,' which refers to its tendency to invent facts. For this, the TruthfulQA dataset is used. |
Harmlessness | Quality raters assess whether the model's output is appropriate, respects protected classes, and avoids derogatory content. This aspect of evaluation employs the RealToxicityPrompts and CrowS-Pairs datasets. |
Zero-shot Performance
ChatGPT is also evaluated for its "zero-shot" performance, i.e., its ability to handle tasks without prior examples on traditional NLP tasks like question answering, reading comprehension, and summarization. Interestingly, the developers noticed performance regressions compared to GPT-3 on some tasks. This phenomenon, known as an "alignment tax," shows that the model's RLHF-based alignment procedure might reduce performance on specific tasks.
However, a pre-train mix technique can substantially mitigate these performance regressions. During the training of the PPO model through gradient descent, the gradient updates are computed by combining the SFT model's and PPO models' gradients' gradients. This process helps to improve the performance of the model on specific tasks.
8. Limitations and Improvements in ChatGPT
ChatGPT, like any AI model, has limitations despite its remarkable capabilities.
Incorrect or nonsensical answers.
ChatGPT, at times, can produce plausible-sounding but incorrect or nonsensical answers. This is mainly because its data is not entirely correct. As we discussed before, ChatGPT will receive various data sources during training, including books and the Internet. So, what are the colors of the traffic lights?
If there are wrong answers in its data source, such as black, white, and yellow, then ChatGPT may also output wrong answers.
Also, when the model is trained to be more careful, it may refuse to answer questions it can handle correctly. And during supervised training, the knowledge of the model, but not that of the human demonstrator, influences the desired response.
Sensitive to input tweak
The model is also sensitive to input tweaks. This means it may produce a very different answer once you adjust the command or ask it to answer the question again. For example, the model will correctly answer queries it previously claimed it did not know. Or change the answer from the previous one (Yes to No). In addition, the data bias and known over-optimization of training ChatGPT also caused some problems. You may find lengthy or overused phrases and statements in ChatGPT's output, such as reaffirming its relationship with OpenAI.
In an ideal scenario, ChatGPT would ask clarifying questions for ambiguous queries. However, the current models tend to guess user intentions instead. While efforts have been made to refuse inappropriate requests, the model may still respond to harmful instructions or exhibit biased behavior. To combat this, OpenAI employs the Moderation API to warn or block certain unsafe content, but false negatives and positives may still exist.
Despite these limitations, the advances from GPT-3 to GPT-4 are promising, showcasing the model's improved ability to generate plausible and accurate text. As we look forward, the expectation is that these improvements will continue, and the limitations will decrease with each new iteration of the GPT model.
Conclusion
In conclusion, ChatGPT, a product of GPT's advanced AI, operates through a combination of transformer architecture, reinforcement learning from human feedback, and diverse datasets. It leverages Natural Language Processing to understand and generate human-like text, facilitating engaging interactions. Though impressive, it's important to note that the system's performance is not flawless and requires continuous improvement evaluations. Despite its limitations, ChatGPT is a remarkable innovation in AI technology, pushing the boundaries of machine-human interaction.