GPT Fine-Tuning: A 7-Minute Comprehensive Guide

OpenAI has unveiled the exciting capability of fine-tuning GPT, marking a new era of customization in artificial intelligence. This article delves into this groundbreaking feature, comprehensively understanding its significance and utility. Whether you're a developer, business professional, or an AI enthusiast, you'll discover how this advancement can reshape interactions and applications, making them more tailored than ever. Dive into all about GPT fine-tuning!
About GPT Fine-Tuning
Fine-tuning is a method wherein the core GPT model undergoes retraining based on distinct patterns, rules, or templates. This means adapting the base model with particular examples furnished by the user. Think of fine-tuning like teaching an already smart computer (called GPT) new tricks using specific examples you give it.
With fine-tuning, businesses and developers can tailor GPT to their needs, leading to cost savings and improved efficiency. One of the challenges with fine-tuning has always been the availability of quality datasets. However, current tools and platforms simplify this process, allowing users to create datasets with minimal effort and resources.
What Can Fine-Tuning Do?
Fine-tuning offers businesses a tailored approach to adapt GPT models. It improves adherence to instructions, personalizes tone, and aids in developing applications like chatbots. Notably, it leads to cost reduction due to shorter prompts yielding desired responses. Developers can customize GPT's abilities for specific needs, such as generating code or summarizing foreign-language documents, aligning with a company's brand voice.
The benefits of fine-tuning are manifold:
Better outcomes than simple prompting.
Training with more examples.
Token savings from concise prompts.
Quicker response times.
GPT models, pre-trained on vast texts, usually employ "few-shot learning" through demonstrations. Fine-tuning, however, refines this by using numerous examples, improving performance across diverse tasks.
Use Cases for Fine-Tuning
Fine-tuning applies to:
Setting style, tone, or format.
Enhancing output reliability.
Addressing intricate prompt failures.
Managing specific edge cases.
Executing new, challenging tasks.
This method excels in "show, not tell", effectively cutting costs and latency without quality loss. Supervised fine-tuning enhances model performance for unique needs, such as:
Improved Steerability: Businesses can better instruct the model, ensuring, for example, that outputs are concise or in a specified language.
Example:
Prompt: "Describe Paris."
Before: "Paris has a long history, being founded in the 3rd century BC..."
After fine-tuning: "Paris, France's capital, is known for the Eiffel Tower."
Reliable Output Formatting: The model can consistently format responses, which is crucial for tasks like code completion or generating API calls.
Example:
Prompt: "Generate HTML for a button."
Before: "You can create a button in HTML with the button tags and the text inside."
After fine-tuning: <button>Click Me</button>
Custom Tone: The tone of the model's output can be fine-tuned to resonate with a business's brand voice.
Example:
Prompt: "Tell me about your products."
Before: "We sell high-quality bags and shoes."
After fine-tuning: "Our collection offers exquisite bags and footwear, reflecting unparalleled elegance."
Furthermore, fine-tuning holds significant potential when combined with techniques like prompt engineering and information retrieval. Future OpenAI updates might also support advanced model fine-tuning with function calls.
When to Use Fine-Tuning?
It's recommended to use fine-tuning when you need specific, ingrained behavior patterns in a model, especially after other strategies, like prompt engineering or prompt chaining, prove insufficient. While these strategies can enhance results and have quicker feedback loops, there are tasks where fine-tuning becomes necessary. However, any effort put into prompt engineering isn't wasted, as the best results often emerge when fine-tuning incorporates effective prompts.
Example:
Task: Make a chatbot that always responds in poetic verse.
Before fine-tuning: "The Eiffel Tower is a famous landmark in Paris."
After fine-tuning: "In Paris stands a tower so grand, a symbol of love in this romantic land."
Furthermore, while fine-tuning focuses on ingraining specific behaviors in a model, retrieval strategies provide the model with fresh information from a database of documents. These strategies aren't alternatives but can complement fine-tuning for enhanced results.
OpenAI's designed their models as all-purpose assistants. However, embeddings with retrieval are the preferred choice for tasks requiring a wealth of contextual information. This is because fine-tuning will tailor OpenAI's generalist models, giving them a more narrowed focus and embedding specific behaviors. Conversely, retrieval strategies feed the model with context before generating its response. Notably, retrieval isn't an alternative but can complement fine-tuning.
GPT Fine-Tuning Steps

Here, we present a step-by-step guide to fine-tuning.
You can also get the OpenAI's guide at https://platform.openai.com/docs/guides/fine-tuning/use-a-fine-tuned-model.
Step 1: Data Preparation
The first phase involves curating the training data, ensuring it reflects the desired behavior of the model post-fine-tuning. For our discussion, a chatbot example will be employed.
Dataset Format:
The dataset should comprise conversation sets similar to the format of the Chat completions API:
Role: Indicates whether the input is from the system, user, or assistant.
Content: Contains the actual content of the message.
Optional Name: (if available).
Example:
To generate a sarcastic chatbot named "Marv", your dataset might resemble the following format:
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already."}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?"}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters."}]}Step 2: Uploading the Files
Before initiating the fine-tuning, you need to validate the data's format. Tools, such as Python scripts, can aid in this by identifying potential errors, reviewing token counts, and gauging the anticipated cost of the operation.
Once the data gets validated, it should be uploaded using the appropriate API for the subsequent fine-tuning process. For instance, a Python script could look like:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.File.create(
file=open("mydata.jsonl", "rb"),
purpose='fine-tune'
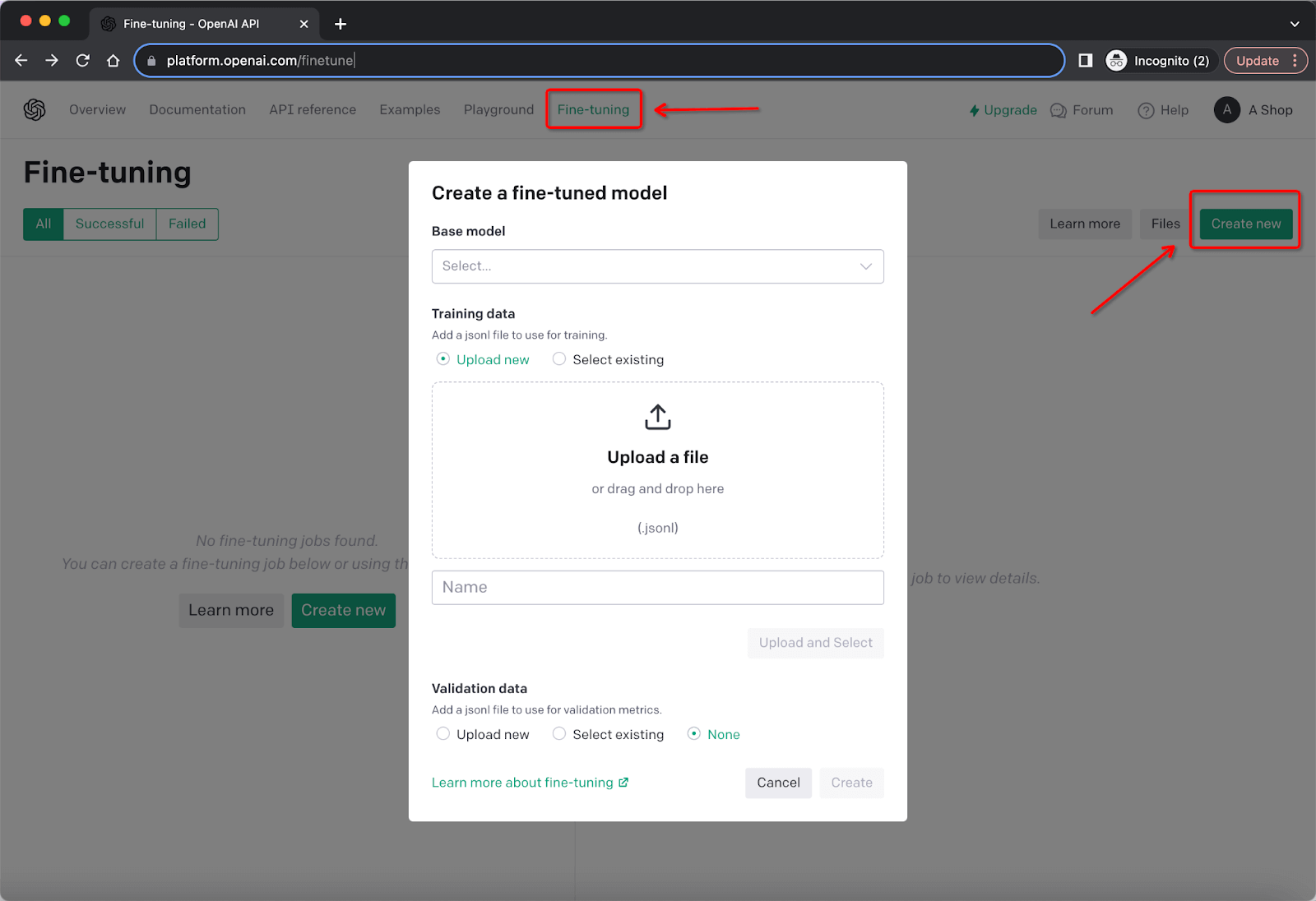
)If you use OpenAI platform (https://platform.openai.com), choose “Fine-tuning”, Click “Create new” to upload the file.
Step 3: Initiating the Fine-Tuning Job
Once the dataset is in place, the next logical progression is launching the fine-tuning job. This process involves specifying the base model (like gpt-3.5-turbo) and the uploaded file's ID.
For a clear representation, consider the following Python snippet:
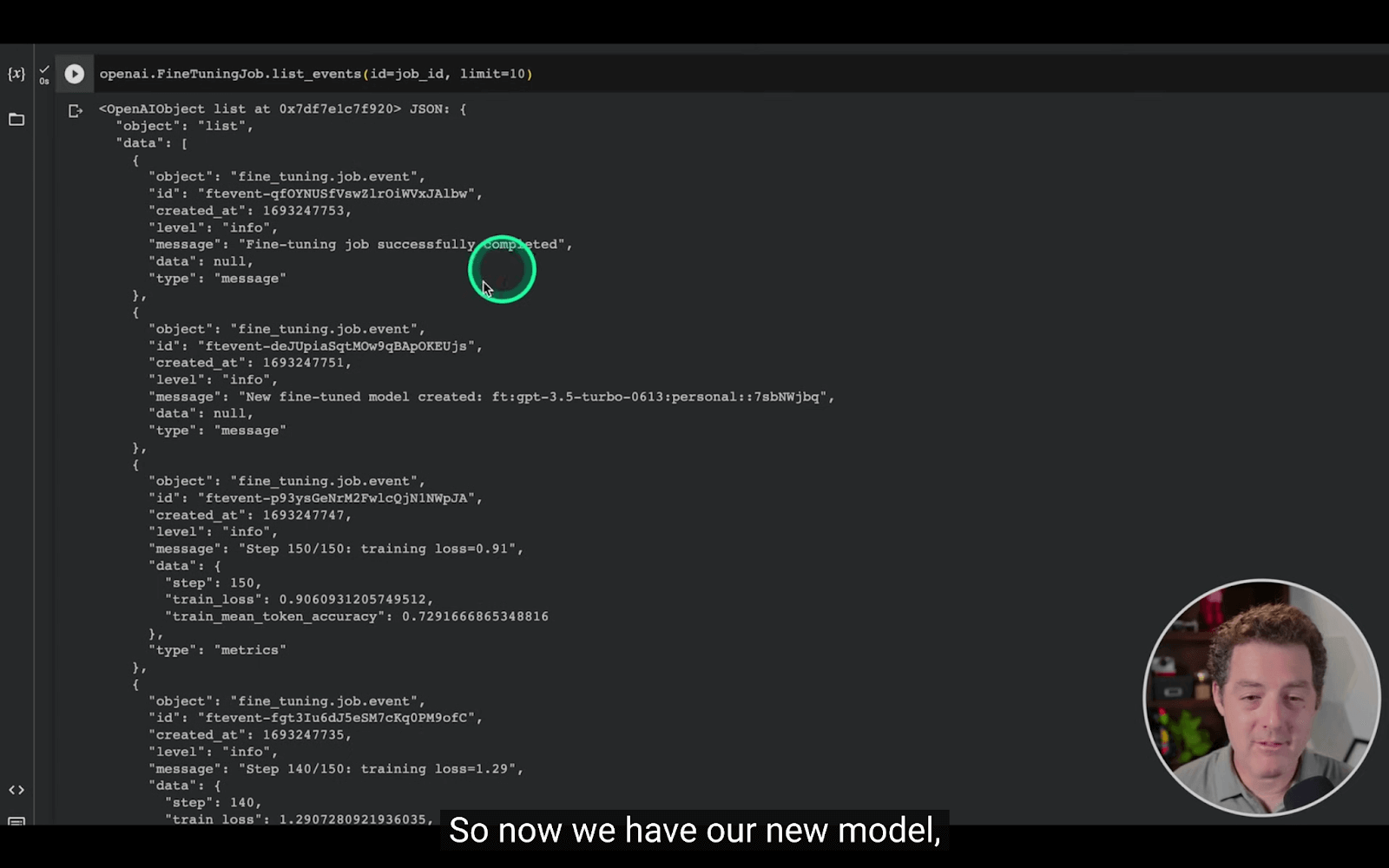
openai.FineTuningJob.create(training_file="file-abc123", model="gpt-3.5-turbo")After the job starts, waiting for it to wrap up, the time varies based on model and dataset sizes. Upon its conclusion, an email notification is dispatched to the user.
Step 4: Deploying the Fine-Tuned Model
Once the fine-tuning concludes successfully, the freshly optimized model is ready for utilization. This model can be invoked in API calls or platforms like OpenAI Playground.
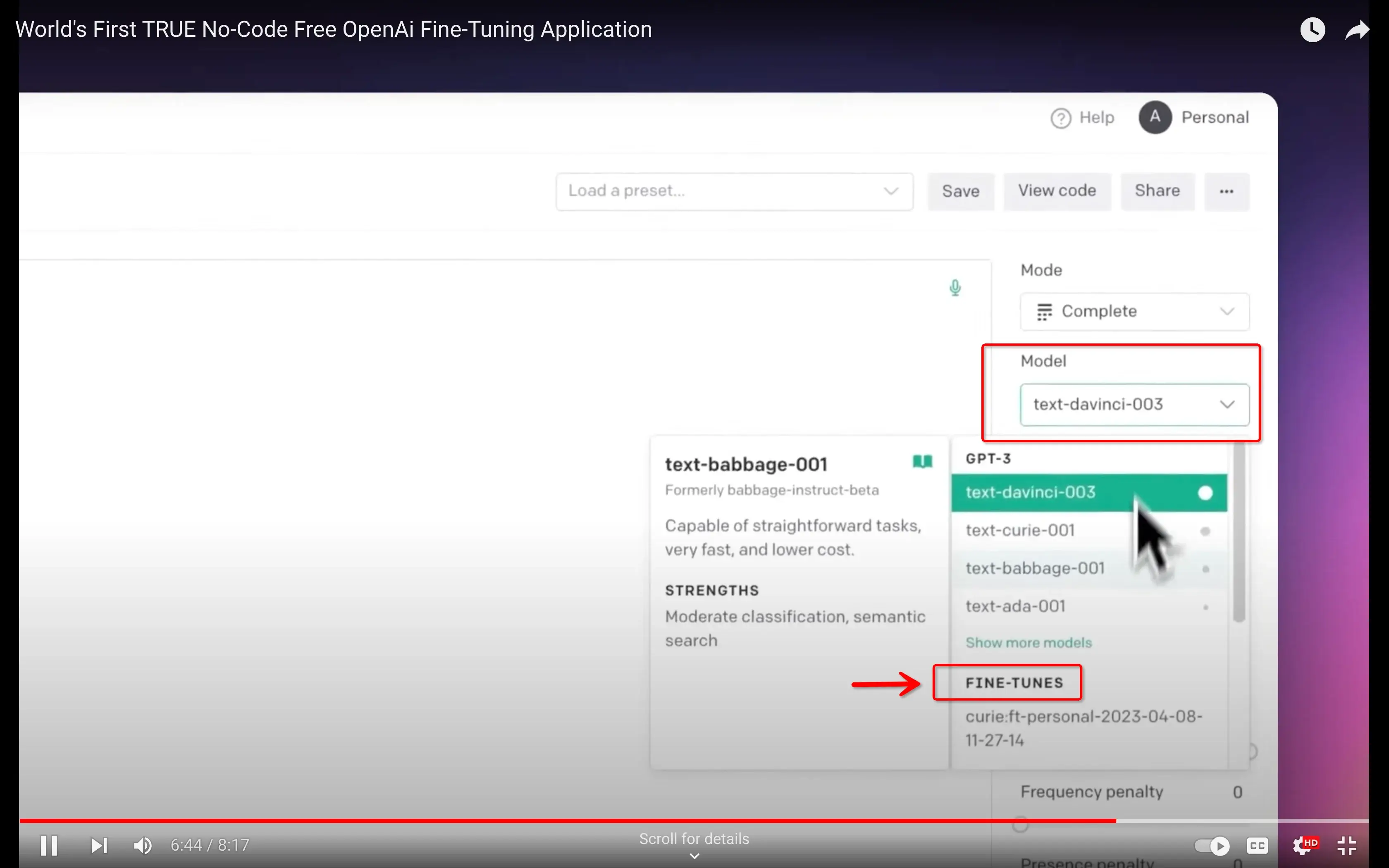
1. Go to OpenAI Playground at https://platform.openai.com/playground.
2. Select “Model”, find the “FINE-TUNES”, then select your fine-tuned model. Then you can use it.
To fetch a response from the model, you'd typically use the model's custom name in the API call:
completion = openai.ChatCompletion.create(
model="ft:gpt-3.5-turbo:custom_model_id",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)Matthew Berman has successfully fine-tuned Chat GPT using Google Colab with minimal effort. The results underscore the vast potential of GPT fine-tuning, which is certainly worth delving into.
GPT Fine-Tuning Pricing
Breakdown of Fine-Tuning Costs
Fine-tuning GPT models encompasses two primary expenses:
Initial training.
Usage costs.
Once you fine-tune a model, charges are based solely on the tokens utilized during requests to that specific model.
Pricing Table for Fine-tuning Models
Model | Training (per 1K tokens) | Input Usage (per 1K tokens) | Output Usage (per 1K tokens) |
|---|---|---|---|
babbage-002 | $0.0004 | $0.0016 | $0.0016 |
davinci-002 | $0.0060 | $0.0120 | $0.0120 |
GPT-3.5 Turbo | $0.0080 | $0.0120 | $0.0160 |
For example, if one were to fine-tune the davinci-002 model using a training file comprising 150,000 tokens over four epochs, the anticipated cost would likely be near $3.60.
Estimating Fine-Tuning Costs
To figure out the cost of fine-tuning:
Check the price for every 1,000 tokens.
Count how many tokens are in your training file.
Decide how many rounds (epochs) of training you want.
Multiply these three numbers together.
Example:
Let's say you're using the GPT-3.5 Turbo model for fine-tuning:
The price for every 1,000 tokens is $0.0080.
You have a training file with 200,000 tokens.
You decide to train for 5 rounds (epochs).
Now, calculate:
$0.0080 (price per 1K tokens) x 200 (200,000 tokens/1,000) x 5 (epochs) = $8.00
So, your estimated cost for this GPT-3.5 Turbo fine-tuning project would be $8.00.
Evaluating Fine-Tuning Costs for ChatGPT
Fine-tuning ChatGPT helps get better answers using shorter questions, which can save money. Think of it like getting a car that runs longer on less fuel. For example, by fine-tuning, you can make your questions up to 90% shorter, speeding up your system and reducing costs.
But, there's a catch. The starting price to fine-tune a model like GPT-3.5 Turbo is 4 to 5 times more than just using it without changes.
Should you fine-tune? It depends on your needs. If your project matches what ChatGPT was originally taught, fine-tuning might be worth the initial cost because you'll save in the long run.
By itself, GPT-3.5 Turbo is affordable and suitable for basic tasks. If you tweak it to your needs, it can be pricier but will need less direction, which is great for businesses with special training data. While powerful models like GPT-4 cost more, you can use them for experimenting or prepping data for GPT-3.5 Turbo tweaks.
Whether to fine-tune or not depends on your specific needs and budget.
GPT Fine-tuning: Understanding Token and Rate Limits
1. Token Limits for Training
Key Fact: Training examples can't be longer than 4,096 tokens.
If an example is too long? It gets cut down to only its first 4,096 tokens.
Best practice? Keep your total tokens under 4,000 for each message to avoid any loss of data.
Tip: You can use tools like OpenAI's token-counting notebook to check how many tokens your text contains.
2. Rate Limits: What and How?
What's a Rate Limit? It's a cap on how often and how much you can request from the GPT API.
Table: Types of Rate Limits
Type | Acronym | Description |
|---|---|---|
Requests Per Minute | RPM | Max number of requests in one minute. |
Requests Per Day | RPD | Max number of requests in one day. |
Tokens Per Minute | TPM | Max tokens you can send in one minute. |
Remember: Hitting any of these limits means you can't make more requests until the limit resets.
GPT-4's Special Rate Limits
GPT-4 has stricter limits initially to handle high demand.
Can you check your rate limits? Yes, on the account page.
Can you request higher limits? Not during the early stages of GPT-4's release.
How Fine-tuned Models Are Affected?
They share the rate limit of their base model.
Using a base model doesn't give extra capacity for the fine-tuned ones. They pull from the same "pool" of allowed requests and tokens.
3. How to Check Your Rate Limits?
Method 1: Look at your account page's 'rate limits' section.
Method 2: Check the HTTP response headers after making a request.
Table: Useful Header Fields
Header Field | Meaning |
|---|---|
x-ratelimit-limit-requests | Max requests allowed. |
x-ratelimit-limit-tokens | Max tokens allowed. |
x-ratelimit-remaining-requests | How many requests you have left. |
x-ratelimit-remaining-tokens | How many tokens you have left. |
x-ratelimit-reset-requests | Time to wait for request limits to reset. |
x-ratelimit-reset-tokens | Time to wait for token limits to reset. |
4. What If You Go Over Your Limits?
Error Message Example: "Rate limit reached for default-text-davinci-002... Limit: 20.000000/min. Current: 24.000000/min".
Translation: You've asked the API too many times in a short period, so you need to wait a bit before asking again.
5. Tokens and Models: What's the Deal?
Different GPT models have different token limits. You can't send more tokens than a model's set limit in a single request.
FAQs
Q1: When will fine-tuning be available for GPT-4 or GPT-3.5-Turbo-16k?
A1: OpenAI intends to introduce fine-tuning capabilities for these models in 2023.
Q2: How can I determine if my adjusted model outperforms the original?
A2: It's advisable to produce examples from the original and adjusted models using a chat conversation test set, then assess them in parallel. For a deeper analysis, consider employing the OpenAI evals system, tailoring an evaluation for your specific requirements.
Q3: Is it possible to refine an already adjusted model?
A3: Absolutely. When initiating a fine-tuning task, input the name of the previously adjusted model into the 'model' parameter. This action commences a new fine-tuning task with the adjusted model as its foundation.
Q4: How does OpenAI ensure the safe use of the fine-tuning feature?
A4: OpenAI has integrated safeguards for responsible fine-tuning. The Moderation API and a GPT-4-backed moderation system process the fine-tuning data. With this method, OpenAI can identify and eliminate potentially harmful training materials, ensuring that even modified outputs comply with their safety guidelines. It also indicates that OpenAI retains some oversight over the content users feed into their models.