ChatGPT Tokens Explained: A 3-Minute Guide You Must Read

ChatGPT has become a global sensation, dazzling people with its ability to converse almost like a human. But have you ever wondered what makes this revolutionary technology tick? It all comes down to a core concept: tokens.
These elemental building blocks enable ChatGPT to understand and generate human-like language. In this article, we aim to demystify the role of tokens in ChatGPT's functionality. What tokens are, why they're crucial, and how to manage them effectively to maximize your ChatGPT experience -- let's dive in!
What Is Tokens?
At the most basic level, tokens represent words, subword units, characters, and symbols that ChatGPT uses to understand and generate language. When you type a prompt into ChatGPT, it first breaks down the text into tokens using tokenization.
For example, the prompt "What is OpenAI's ChatGPT?" would get tokenized into:
["What," "is," "Open," "AI," "'s," "Chat," "G," "PT," "?"]
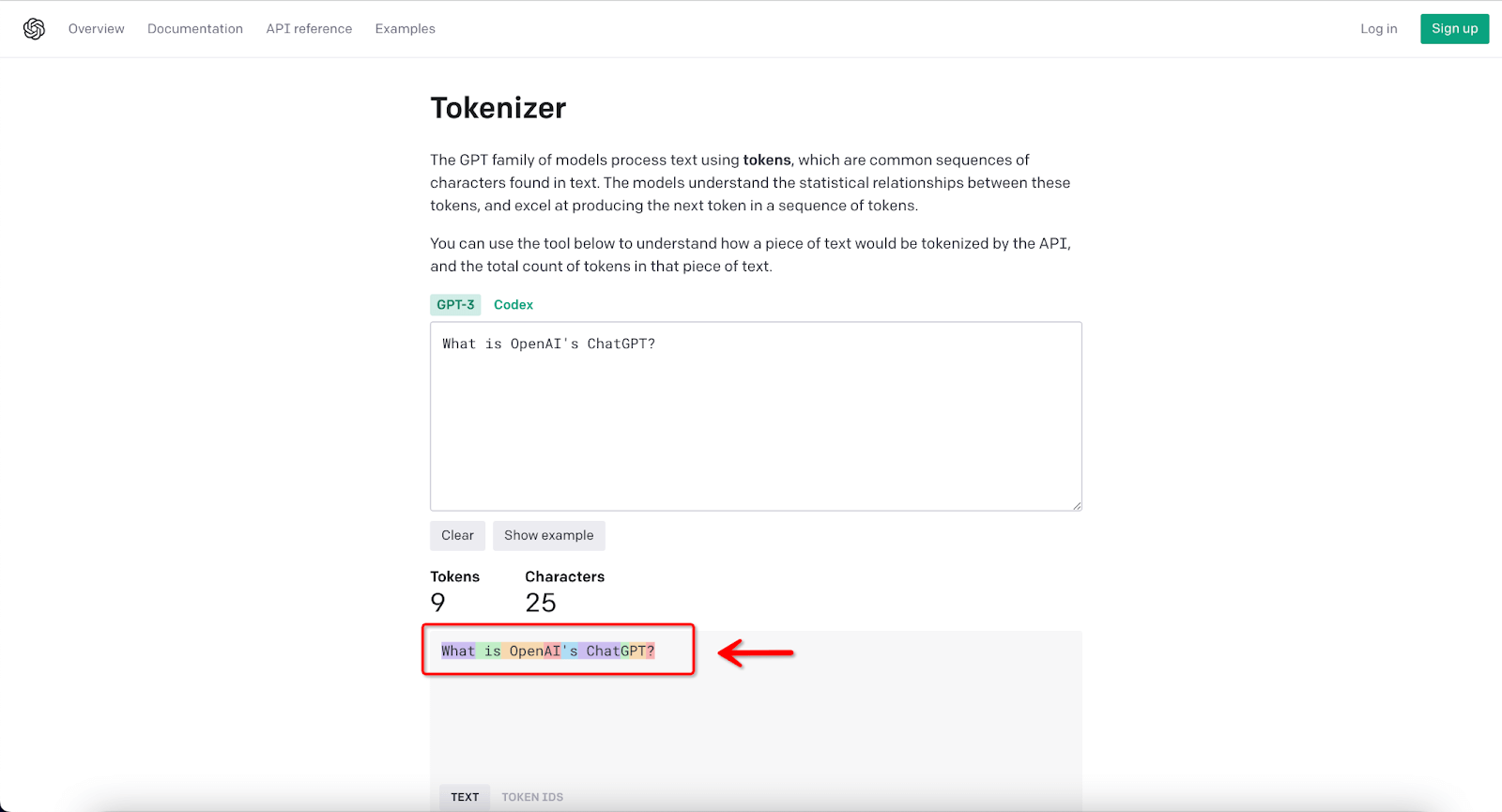
If we switch to the Token IDs option, it looks something like this:
[2061, 318, 4946, 20185, 338, 24101, 38, 11571]
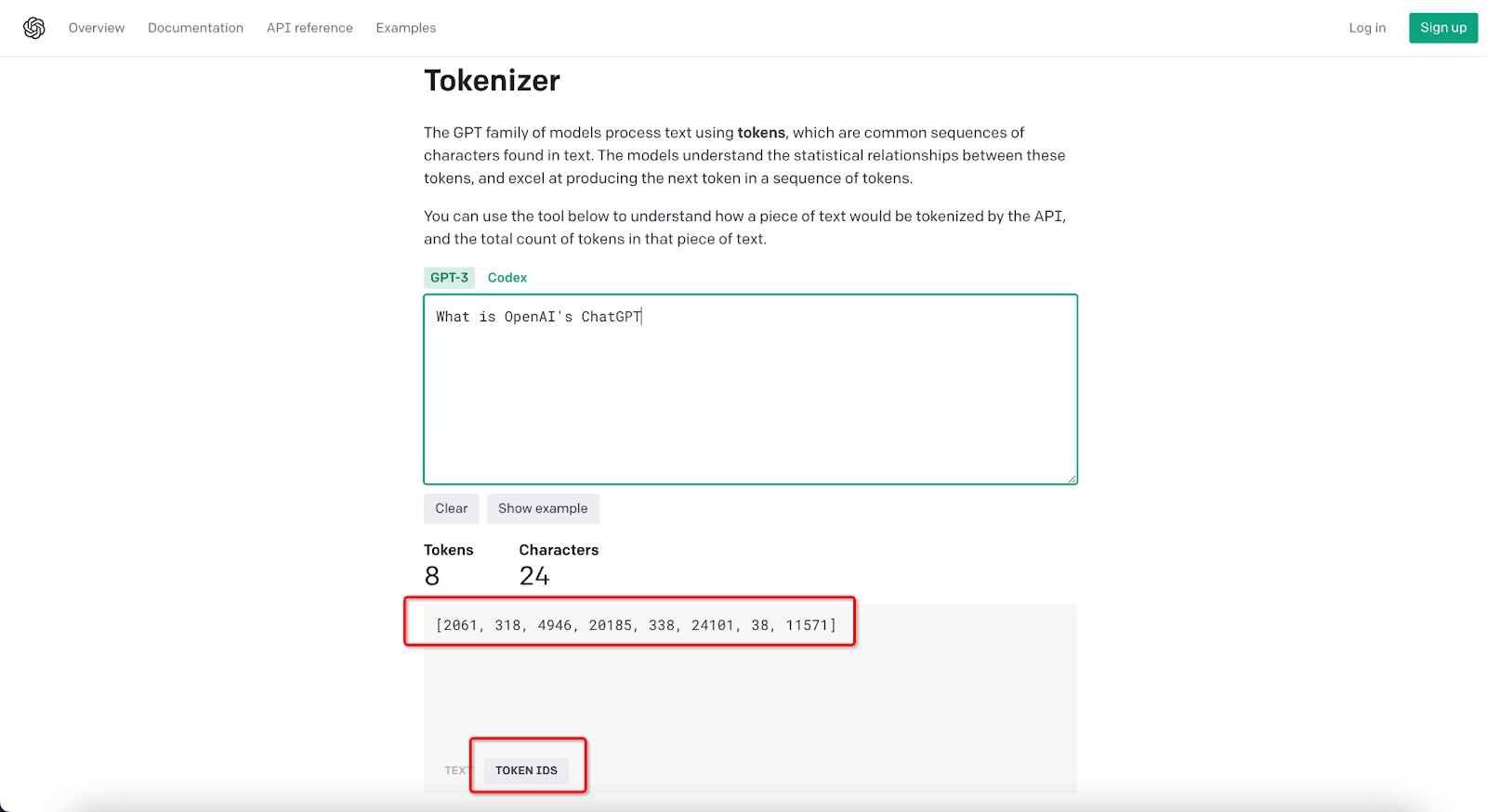
As you can see, some tokens represent whole words like "What" and "is," while others represent subword units like "Open," "G," and "PT" from the words "OpenAI" and "ChatGPT". The question mark is also its token.
ChatGPT interprets these tokens about one another based on patterns learned during its training on vast amounts of text data. It uses the tokens to analyze linguistic relationships, context, and meaning. The model then generates a response token-by-token, assembling coherent sentences from the predicted sequences of tokens.
So, tokens allow ChatGPT to decompose language into digestible pieces to process, learn from, and reproduce human-like text. Mastering the role of tokens is crucial for understanding ChatGPT's inner workings and using the system effectively.
How Tokens Enable ChatGPT
Tokens are an integral part of how ChatGPT processes language. When you enter text into ChatGPT or any GPT model, the first thing it does is tokenize that text. This process will split it into more miniature token representations of words, subwords, punctuation, and other symbols. These tokens then get converted by the model into numeric values called embeddings. Embeddings represent the contextual relationships between tokens based on patterns ChatGPT learned from its training data.
For instance, the embeddings contain information about tokens commonly appearing together in sentences based on ChatGPT's language understanding. ChatGPT uses attention mechanisms to focus on the relevant token embeddings when generating a response. Then, the chatbot analyzes these embeddings to predict the most likely next token in the sequence. The model chooses a token, assigns an embedding to represent it, and repeats this token-by-token process until the response is complete.
With the technique of segmenting text into tokens and employing embeddings to forecast the next tokens, ChatGPT achieves impressively human-like replies. This token-based decomposition and reconstruction of language allow for a nuanced grasp of context. Consequently, the model can generate text that closely aligns with the original prompt.
Why Tokens Are Matter
Now that you know what tokens are, let's discuss why they're integral to ChatGPT and other large language models:
Language Processing and Generation
Tokens are the basic building blocks allowing ChatGPT to break down and reconstruct language. The model relies entirely on sequences of tokens as inputs and outputs to understand and generate text. Without tokenization, ChatGPT could not effectively process or produce natural language.
For instance, how does ChatGPT handle a query like "What are the symptoms of the flu?"?
The model first breaks it down into individual tokens such as ["What", "are", "the", "symptoms", "of", "the", "flu", "?"], and then uses these tokens to formulate a response like, "The symptoms of the flu include fever, chills, and body aches."
Efficiency and Context Preservation
Tokenization provides an efficient way for ChatGPT to analyze the significance of each token, both individually and in sequence. This aids the model in maintaining context throughout long conversations with multiple question-response pairs.
If ChatGPT processed entire sentences or paragraphs as a whole, it would lose the nuances provided by understanding relationships between individual tokens.
Defining Model Capacity
Token limits determine how much data ChatGPT models can handle in a single interaction. For instance, ChatGPT-3.5 has a 4096 token limit. More capable models like GPT-4 can manage 8000+ tokens. These boundaries define the processing capacity of different ChatGPT variants.
Without tokenization, there would be no straightforward way to quantify model capacity. Setting token limit maximums ensures efficient performance within computing constraints.
Cost Implications
ChatGPT pricing directly correlates with the number of tokens used in cloud-based settings. Therefore, the more tokens consumed, the higher the cost, allowing for precise measurement of resource usage.
How to Calculate Tokens
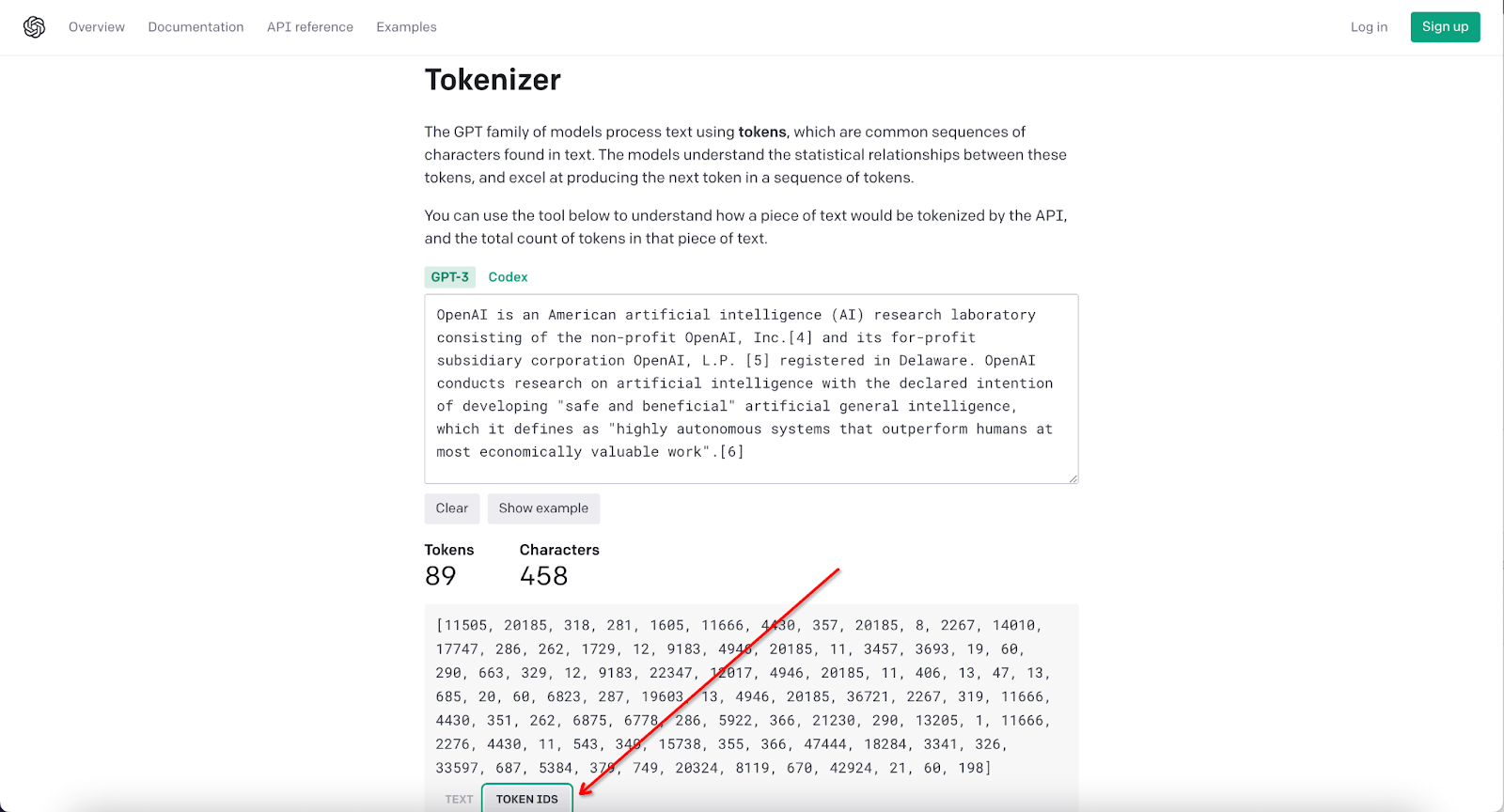
The GPT models handle text by breaking it into units called tokens, which represent sequences of characters. These tokens hold statistical relationships that the model leverages to predict subsequent tokens in a given sequence. For precise token calculations, you can use OpenAI's free tool, the "OpenAI tokenizer".
How to Use the Tool for Accurate Counting
1. This platform can be accessed directly at https://platform.openai.com/tokenizer without needing to sign in. You can choose GPT-3 or Codex model; the latter employs a unique encoding scheme that manages whitespace more efficiently.
2. Simply copy and paste your text into the tool to get an accurate token count, how it's split, and the token IDs.
For example:
"OpenAI is an American artificial intelligence (AI) research laboratory consisting of the non-profit OpenAI, Inc.[4] and its for-profit subsidiary corporation OpenAI, L.P. [5] registered in Delaware. OpenAI conducts research on artificial intelligence with the declared intention of developing "safe and beneficial" artificial general intelligence, which it defines as "highly autonomous systems that outperform humans at most economically valuable work".[6]
This paragraph is 88 tokens.
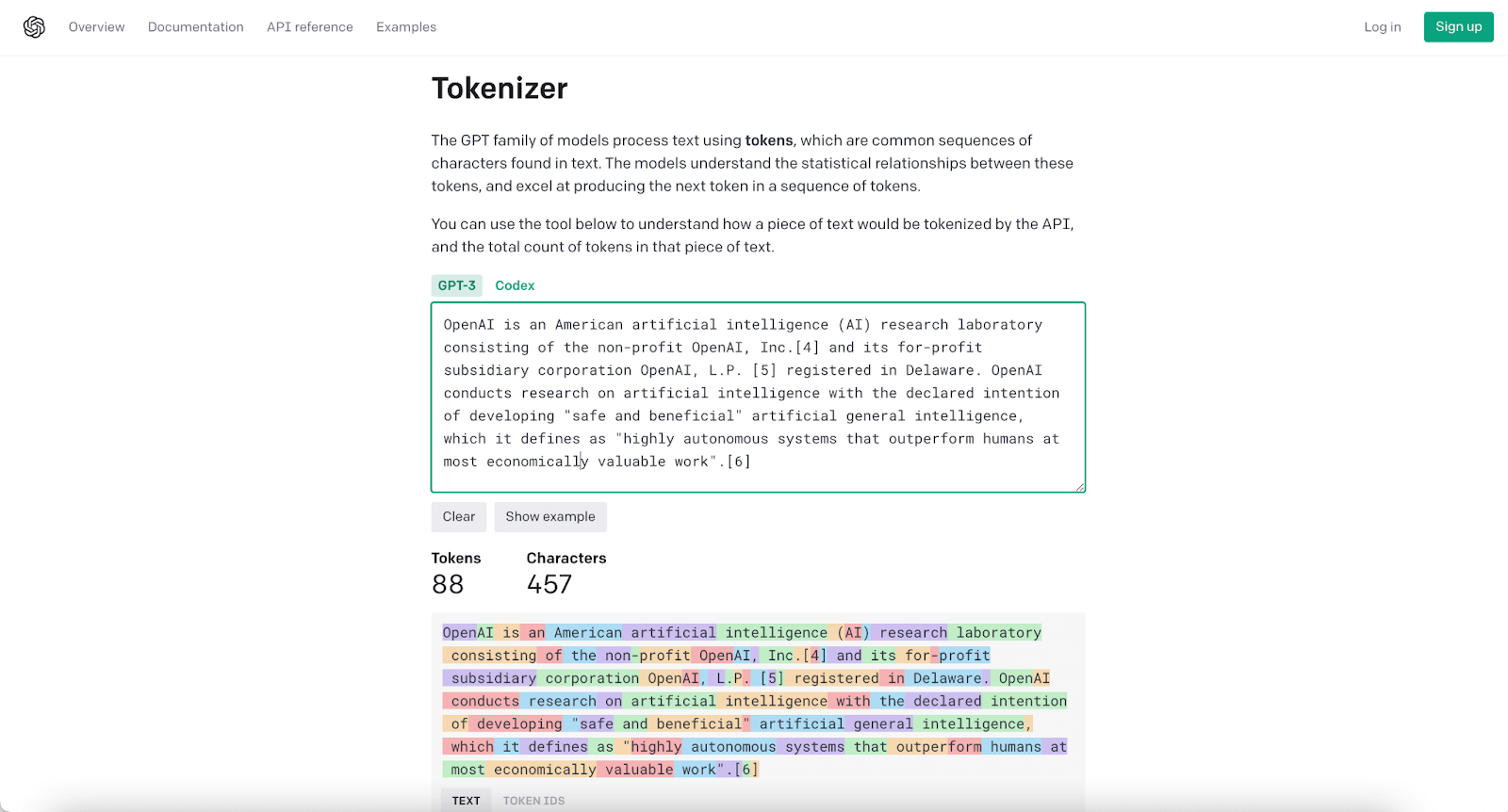
Here are the Token IDs.
Estimation Guidelines
Generally, one token corresponds to about four characters in standard English text. That means a 400-character piece of text would roughly translate to around 100 tokens. However, OpenAI's tokenizer gives the most accurate count since the exact ratio can fluctuate. Punctuation and special characters are also counted, so don't disregard them when estimating the token count. A helpful approximation is that 100 tokens are equivalent to about 75 words.
Note:
For developers, the Python tiktoken library provides programmatic tokenization capabilities. You can visit the library at https://github.com/openai/tiktoken.
Try tokenizing different text samples with varied lengths and complexity to understand how token counts accumulate.
Pay attention to token counts as you construct prompts and have conversations with ChatGPT to stay within model limits.
Different GPT Model Price
Model | Input Price for 1000 tokens (prompt) | Output Price for 1000 tokens (completion) |
|---|---|---|
Ada | $0.0004 | $0.0016 |
Babbage | $0.0005 | $0.0024 |
Curie | $0.0020 | $0.0120 |
DaVinci | $0.0200 | $0.1200 |
ChatGPT | $0.0020 | $0.0020 |
Chat 4K context | $0.0015 | $0.002 |
GPT-4 8k context | $0.03 | $0.06 |
Chat 16K context | $0.003 | $0.004 |
GPT-4 32k context | $0.06 | $0.12 |
GPT Token Limitations
Tokens are the building blocks of GPT models, but there are limits to how many tokens these models can handle at once. For instance, ChatGPT-3.5 can only manage up to 4096 tokens in a single request. If your input exceeds this limit, it will either be cut short, or you'll have to modify it to fit. Trimming or changing your text could lead to missing essential details, affecting the model's understanding.
Moreover, these limitations apply mainly to the OpenAI API and could be even more restrictive for ChatGPT. So, when interacting with these models, be mindful of these token limits to get the best results.
Here is a table that outlines the maximum token limits for various GPT models, both input and output.
Model | Max Tokens |
|---|---|
gpt-4 | 8,192 tokens |
gpt-4-0613 | 8,192 tokens |
gpt-4-32k | 32,768 tokens |
gpt-4-32k-0613 | 32,768 tokens |
gpt-3.5-turbo | 4,096 tokens |
gpt-3.5-turbo-16k | 16,384 tokens |
gpt-3.5-turbo-0613 | 4,096 tokens |
gpt-3.5-turbo-16k-0613 | 16,384 tokens |
text-davinci-003 | 4,097 tokens |
text-davinci-002 | 4,097 tokens |
code-davinci-002 | 8,001 tokens |
The reply may need to be completed when the model hits its token ceiling during a response. If your original message was very long, ChatGPT might not be able to offer a complete and well-structured answer. Additionally, in long conversations, the model can only recall a limited portion of the chat history due to this token cap. It will forget the older parts of the conversation, leading to responses that seem unrelated or out of context.
That's why it's crucial to be mindful of token limits when interacting with ChatGPT. You'll need to think creatively to ensure all the vital information fits these constraints. Understanding these limitations is essential for having meaningful and effective conversations with the model while avoiding common problems like lost context and incomplete replies.
Tips for GPT Token Limitations
When dealing with token limitations in ChatGPT, the conversation can get tricky. But don't worry—there are some clever ways to make the most of the situation. Here are practical strategies to ensure you have effective interactions:
Crafting Effective Prompts
The first step is to make your messages short and sweet. Remove extra words and simplify what you're trying to say. If you're asking a new question, summarize the key points from your earlier conversations. This will keep your query focused and less likely to be cut off.
Managing Long Conversations
If you hit the token limit in the middle of a chat, pause and summarize what you've been talking about. This will help ChatGPT pick up where it left off. If this becomes a frequent issue, consider switching to a ChatGPT model with a higher token limit.
Utilizing Tokenization Tools
Use tools that can break them into smaller parts for really long pieces of text. Process these smaller segments separately and then stitch them together. This way, you can cover all your content without exceeding the token cap.
Keeping Conversations on Track
In longer discussions, key details might get lost due to token constraints. Make it a habit to remind ChatGPT about the important parts of your conversation. This will help the model stay focused on what's relevant.
What To Do When You Hit the Limit
Sometimes, despite your best efforts, you might still hit the token ceiling. If that happens
Realign the Conversation: Quickly summarize the conversation to help ChatGPT catch up.
For example: "Recapping our discussion, we've been exploring how to write the essay. In brief.."Ask Focused Questions: If you notice that the answers are getting irrelevant, restate your original question more straightforwardly. This helps ChatGPT get back on track.
Switch Models: If you need more room for discussion, consider using a ChatGPT model with a higher token limit. This will let you carry on without losing context.
Condense Your Query: If a long question gets cut off, trim it to the essential parts and ask again.
Segment Your Input: If one query is too long, break it into smaller chunks. Summarize the previous answers before asking the next part to maintain continuity.
Remember, the trick is to manage the context of your conversation carefully.
Applying Token Mastery in Real-world Applications
Understanding how to manage token usage opens doors for various practical applications using OpenAI's ChatGPT and Whisper AI. Below are some real-world scenarios demonstrating how mastery of token management can be instrumental.
Creating Conversational Experiences
Designing chatbots or virtual assistants requires token optimization for fluid and coherent interactions. Doing so makes it easier for users to engage with your system.
Example: Design an interactive healthcare assistant to summarize a patient's symptoms and questions periodically. This ensures it stays within the token limits while keeping the conversation relevant.
Streamlining Business Operations
Token mastery can help automate tasks like data analysis and report writing more efficiently, saving both time and resources.
Example: ChatGPT could divide lengthy forum posts into smaller parts for analysis in a content moderation system. After each segment, it could summarize its findings, enabling the system to stay within token limits while providing comprehensive reviews.
Generating Content
Whether you're a content creator or a marketer, understanding token limitations can help you generate substantial content without losing context.
Example: A marketing team can use ChatGPT to develop a series of blog posts. They could keep the narrative consistent across multiple prompts by periodically reiterating the main points and the campaign's goal.
Developing Adaptive Assistants
Intelligent token management can be crucial when creating AI assistants that are both engaging and efficient.
Example: A virtual tour guide app could be programmed to ask users for priority interests when nearing token limits. This ensures that the conversation stays focused on the most relevant topics.
Pioneering Innovations with ChatGPT and Whisper APIs
Companies like Snap Inc., Quizlet, Instacart, Shopify's Shop, and the Speak App have successfully integrated ChatGPT and Whisper APIs into their platforms:
Snap Inc.: Their "My AI" feature on Snapchat offers a chatbot that provides quick recommendations and even generates haikus, catering to their massive user base who regularly engage in messaging.
Quizlet: Through their new feature, Q-Chat, they offer a fully adaptive AI tutor. The tool helps students with tailored questions based on their study materials, all while staying within the token constraints.
Instacart: Their "Ask Instacart" feature is in development to enable customers to get shoppable answers to their culinary questions, facilitated by ChatGPT integrated with Instacart's database.
Shopify's Shop: Their AI-powered shopping assistant utilizes ChatGPT to make personalized product recommendations, making the shopping experience more engaging and efficient.
Speak App: This language learning app uses Whisper API to offer highly accurate conversational practice and feedback, helping users achieve spoken fluency.
By understanding and adapting to token limitations, these companies have offered valuable and efficient services to their users.
Conclusion
Understanding and mastering tokens is crucial for seamless interactions with ChatGPT. While token limitations can be a hurdle, effective strategies such as crafting concise prompts and intelligent text segmentation can help you navigate them effortlessly.
With practice, you'll be well-equipped to harness ChatGPT's full capabilities for personal and professional needs. Ultimately, the key to unlocking the full potential of language AI lies in optimizing the use of these foundational tokens. We hope this guide serves you well. For more deep dives into AI, stay tuned to Gate2AI!