Curioso sobre a IA que está revolucionando as conversas? Já se perguntou como o ChatGPT consegue entender suas perguntas e elaborar respostas coerentes? Mergulhe nos intricados funcionamentos dessa tecnologia inovadora, desde sua fundação no GPT até o papel do Processamento de Linguagem Natural e além. Explore seu desempenho, limitações e possibilidades futuras. Desvende a ciência por trás do seu parceiro de conversa digital, o ChatGPT.
1. Sobre GPT e ChatGPT
1.1 Definindo os modelos GPT
GPT, ou Generative Pre-trained Transformers (Transformadores Pré-Treinados Generativos), é um desenvolvimento significativo em inteligência artificial. Eles são utilizados em numerosas aplicações de IA generativa, incluindo o ChatGPT. Construídos na arquitetura transformer, os modelos GPT podem produzir texto semelhante ao humano e outros tipos de conteúdo, como imagens e música. Além disso, você pode usá-los para responder a perguntas, ter conversas com eles, lidar com tudo relacionado a texto e muito mais.
1.2 Introdução ao ChatGPT
O ChatGPT é um derivado dos modelos GPT, desenvolvido pela OpenAI. Ele funciona de forma semelhante ao seu modelo irmão, InstructGPT, mas com uma abordagem conversacional. A singularidade dessa diferença dá ao ChatGPT uma função interativa, permitindo que ele se comunique com os usuários e, além disso, complete perguntas e respostas, identifique erros, etc.
1.3 Comparando ChatGPT com Mecanismos de Busca
Mecanismos de busca como o Google e mecanismos computacionais como o Wolfram Alpha também interagem com os usuários por meio de um campo de entrada de texto de linha única. No entanto, enquanto a força do Google está em executar amplas pesquisas de banco de dados para fornecer uma série de correspondências e o Wolfram Alpha está equipado para analisar perguntas relacionadas a dados e realizar cálculos, a força do ChatGPT é a capacidade de analisar consultas e fornecer respostas abrangentes com base em uma vasta quantidade de informações textuais digitalmente acessíveis.
Por exemplo, pesquisando "como desbloquear um iPhone" em mecanismos de busca como o Google, você obterá artigos com soluções criados por diferentes sites. Você precisa passar por esses artigos para obter a solução.
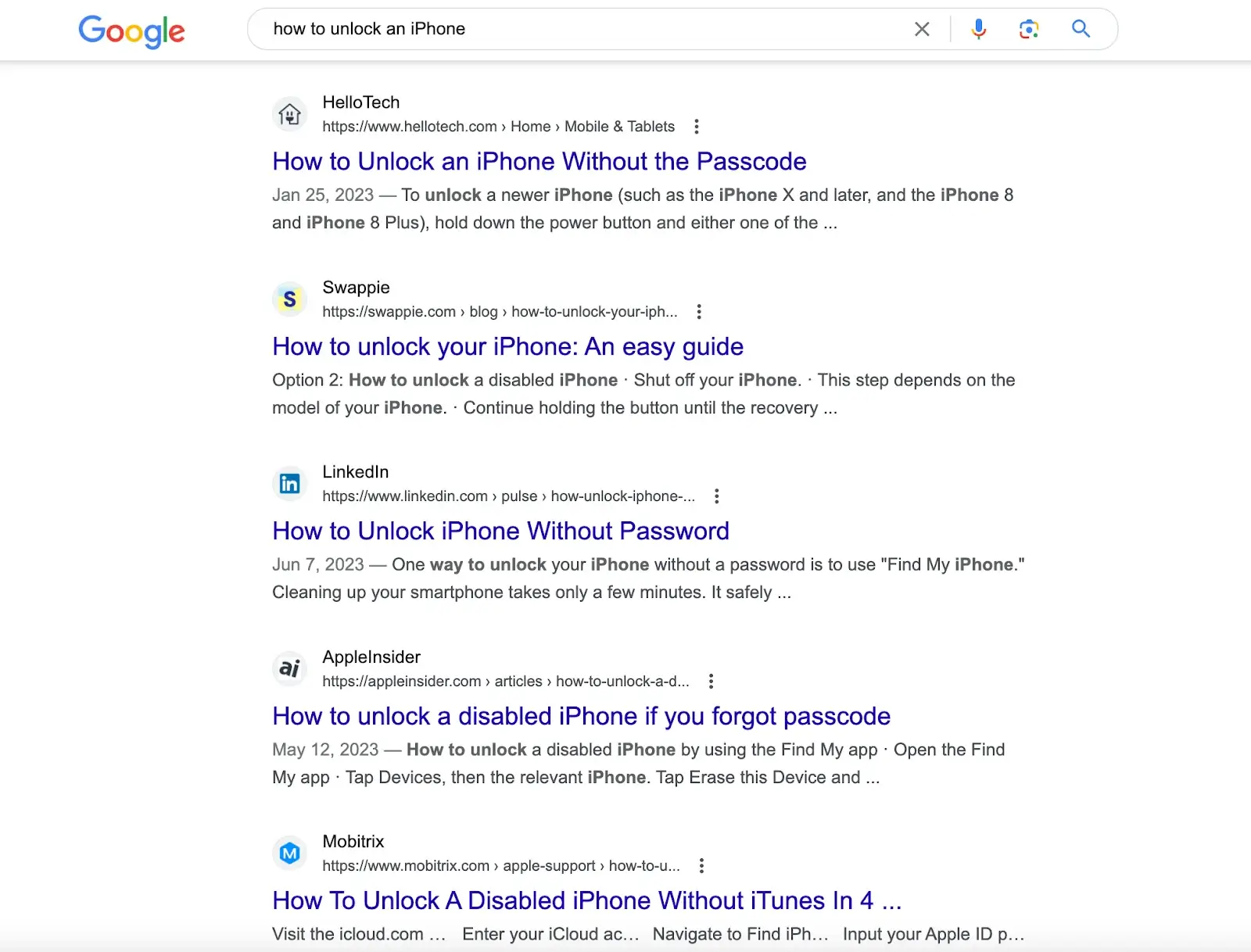
Mas se você inserir essa pergunta no ChatGPT, ele fornecerá a resposta diretamente. A resposta vem do conjunto de dados pré-treinado, que também contém o conteúdo no link fornecido pelos mecanismos de busca.
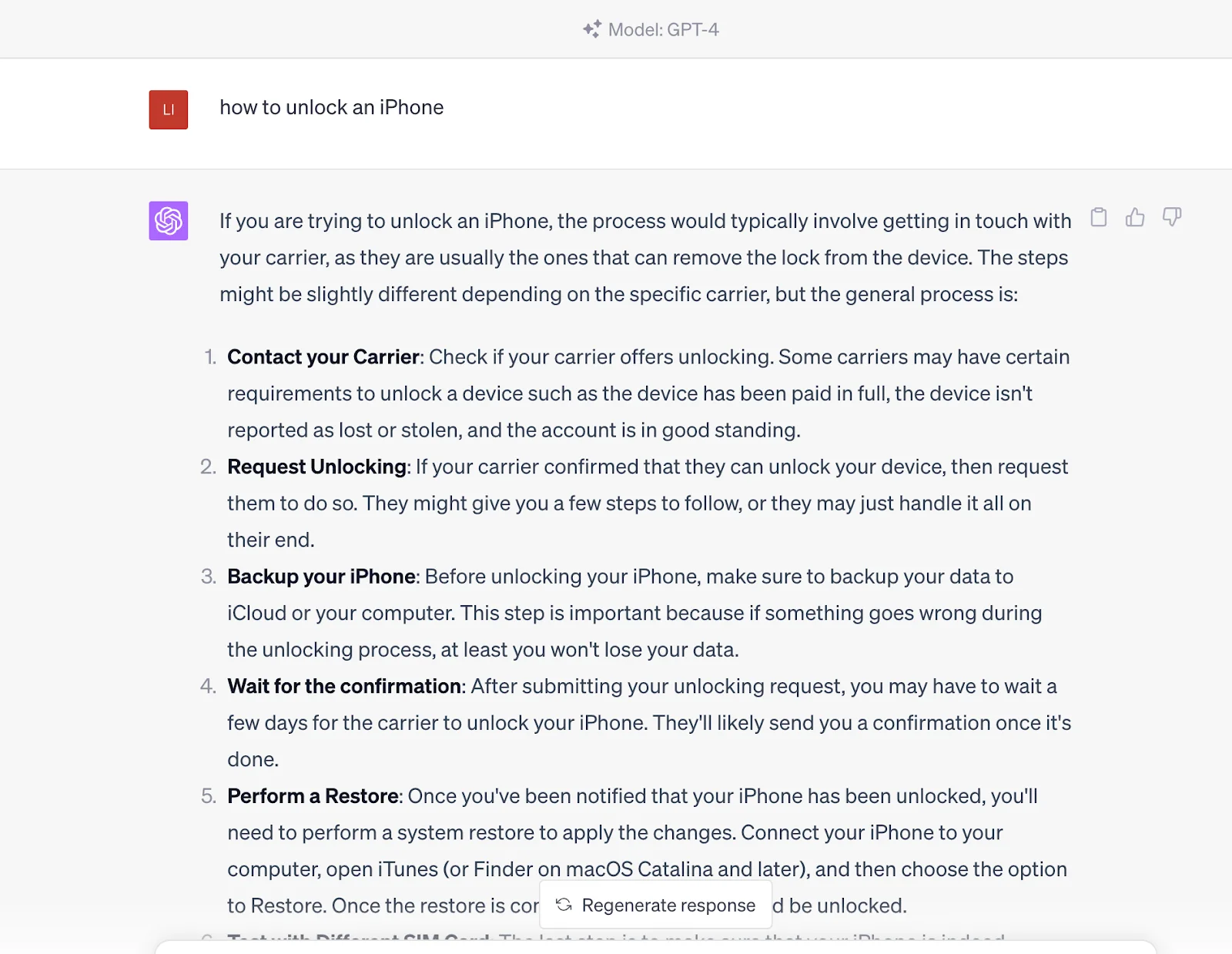
Em outras palavras, você se comunica com uma entidade informada que pode gerar resultados de consulta em vez de apenas obter essas fontes de conteúdo por meio de mecanismos de busca. No entanto, deve-se observar que atualmente é inferior aos mecanismos de busca em termos de atualidade, pois as informações do ChatGPT são baseadas nos dados treinados até 2021.
2. Como o ChatGPT funciona
O funcionamento do ChatGPT é dividido em duas fases: pré-treinamento ou coleta de dados e inferência ou resposta a prompts do usuário. Como discutimos antes, o ChatGPT é semelhante ao Google. Após extensivo treinamento, o ChatGPT pode entender perguntas e gerar respostas de seu banco de dados. A única diferença é que ele gerará respostas diretas, não links quando você enviar um prompt.
O ChatGPT emprega redes neurais de deep learning para gerar texto semelhante ao humano. Como o cérebro humano faz previsões e tira conclusões com base em conhecimento prévio, o ChatGPT é treinado em uma imensa quantidade de dados ou tokens, essencialmente unidades de texto que podem representar palavras únicas ou partes de palavras complexas.
Ao contrário dos modelos de IA tradicionais treinados usando uma abordagem supervisionada emparelhando cada entrada com uma saída específica, o ChatGPT usa uma abordagem de pré-treinamento não supervisionado. Aqui, o modelo aprende a estrutura inerente e os padrões nos dados de entrada sem ter uma tarefa específica em mente, compreendendo assim a sintaxe e semântica da linguagem e permitindo gerar texto significativo de forma conversacional. Este pré-treinamento é o poder transformador por trás do vasto conhecimento e capacidades do ChatGPT.
O modelo pode desenvolver uma ampla gama de respostas com base na entrada recebida, processando enormes quantidades de dados usando modelagem de linguagem baseada em transformer. Essa metodologia forma a base das capacidades de conhecimento e conversação aparentemente ilimitadas do ChatGPT.
Esse treinamento começa expondo o modelo a enormes quantidades de conteúdo escrito por humanos - de livros e artigos a conteúdo da internet. O modelo assim aprende padrões e relacionamentos desses tokens, formando uma rede neural de deep learning. Essa rede, semelhante a um algoritmo de múltiplas camadas que imita o funcionamento do cérebro humano, permite que o modelo gere texto contextualmente relevante e semelhante ao humano.
O que é notável sobre o ChatGPT é sua capacidade de gerar longos textos em vez de apenas prever a próxima palavra em uma frase. A OpenAI revelou sua capacidade de treinar o ChatGPT a esse respeito por meio do aprendizado por reforço a partir de feedback humano (RLHF), permitindo que ele gere frases inteiras, parágrafos e até cadeias de texto mais longas para gerar respostas coerentes. Esse treinamento envolve um modelo de recompensa no qual o treinador classifica as diferentes reações geradas pelo modelo para ajudar a IA a entender o que constitui uma boa resposta.
Outra força que apóia o funcionamento do ChatGPT é seu enorme número de parâmetros. O GPT-3 tem 175 bilhões e o GPT-4 não revelou o número específico, mas pode-se especular que pode ser mais. Cada prompt que o usuário envia precisa ser processado por esses parâmetros, e a saída será afetada por seu valor e peso. Além disso, a aleatoriedade foi incorporada a esses parâmetros para evitar respostas mecânicas e repetitivas e mantê-las frescas. Por exemplo, você pode usar o mesmo prompt e gerar resultados diferentes.
3. Aprendizado por Reforço a partir de Feedback Humano (RLHF)
De acordo com a OpenAI, o treinamento do ChatGPT é em grande parte baseado no método de Aprendizado por Reforço a partir de Feedback Humano (RLHF). Este método envolve uma série de etapas distintas para produzir um modelo capaz de gerar respostas desejáveis.
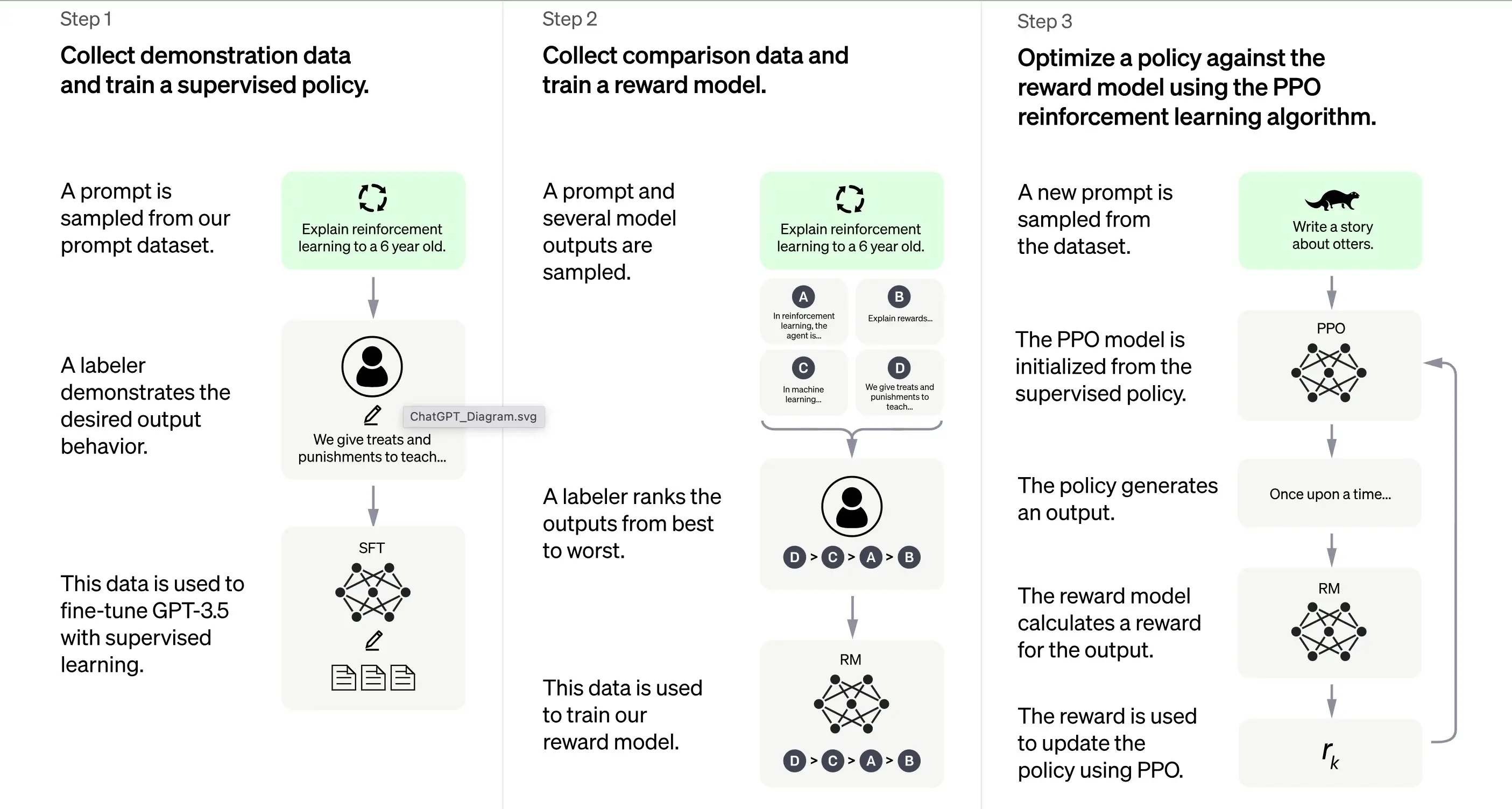
1. Treinamento Inicial: Ajuste Fino Supervisionado (SFT)
A primeira etapa no treinamento do ChatGPT é o Ajuste Fino Supervisionado (SFT). Esta fase envolve o uso de um conjunto de dados pequeno e cuidadosamente elaborado, composto por prompts e suas respostas correspondentes produzidas por humanos rotuladores. O treinamento visa produzir uma saída correta e de alta qualidade para o ChatGPT. De acordo com a OpenAI, o modelo de treinamento nesta fase é baseado na série de modelos GPT-3.5.
A primeira etapa no treinamento do ChatGPT é o Ajuste Fino Supervisionado (SFT), um modelo de política supervisionado treinado coletando dados de demonstração de rotuladores humanos. O ChatGPT usa duas fontes de prompts: rotulagem direta de desenvolvedores ou solicitações da API da OpenAI. O conjunto de dados resultante pequeno, de alta qualidade e elaborado é usado para ajuste fino de um modelo de linguagem pré-treinado. Em vez de ajustar o modelo GPT-3 original, os desenvolvedores do ChatGPT escolheram um modelo pré-treinado da série GPT-3.5, provavelmente text-davinci-003. Esta decisão foi tomada para criar um chatbot de propósito geral como o ChatGPT sobre um modelo de "código" em vez de um modelo de texto puro.
No entanto, o modelo SFT ainda pode não ser atento ao usuário e sofrer de desalinhamento. Para superar esse problema, os desenvolvedores agora classificam as diferentes saídas do modelo SFT para criar um modelo de recompensa.
2. Gerando o Modelo de Recompensa
A etapa é projetada para gerar uma função objetivo, o modelo de recompensa. Este modelo pontua as saídas do modelo SFT, com uma pontuação proporcional ao quanto a classe espera que essas saídas atendam às expectativas. Quanto mais expectativas forem atendidas, maior a pontuação e vice-versa.
Os rotuladores pontuarão manualmente a saída do modelo SFT de acordo com preferências específicas e critérios comuns que concordam em seguir. Em última análise, este processo ajuda a criar um sistema automatizado que pode imitar as preferências humanas.
A vantagem deste método é que ele é extremamente eficiente. Porque os rotuladores só precisam classificar a saída em vez de usar o modelo para produzir conteúdo do zero.
Seu fluxo de trabalho é grosso modo o seguinte:
Selecione uma lista de prompts e o modelo SFT gera múltiplas saídas (qualquer saída entre 4 e 9) para cada prompt.
O rotulador classifica as saídas de melhor a pior, criando um novo conjunto de dados rotulado com os "rankings" como rótulos. Este conjunto de dados é cerca de dez vezes maior que o conjunto de dados elaborado usado pelo modelo SFT.
Esses dados treinarão então o Modelo de Recompensa (RM). O modelo recebe como entrada algumas saídas do modelo SFT e as classifica em ordem de preferência.
Até agora, discutimos como o modelo é treinado inicialmente usando ajuste fino supervisionado e, em seguida, refinado usando um modelo de recompensa. Essas etapas formam os blocos de construção básicos para treinar o ChatGPT. No entanto, o processo continua além disso. O sistema então entra em uma fase de melhoria iterativa por meio de uma técnica chamada Otimização de Política Proximal.
3. Melhoria Iterativa: Otimização de Política Proximal (PPO)
A etapa final de treinamento envolve a aplicação da Otimização de Política Proximal (PPO). Esta técnica usa o modelo de recompensa como uma função de valor para estimar o retorno esperado de uma ação. Em seguida, aplica uma "função de vantagem", representando a diferença entre os retornos esperados e reais, para atualizar a política.
O PPO é um algoritmo "on-policy" que aprende e atualiza a política atual com base nas ações do agente e nas recompensas recebidas. Este design ajuda a garantir uma aprendizagem estável, restringindo a extensão da mudança na política durante cada atualização, impedindo que o modelo faça alterações drásticas que poderiam interromper o processo de aprendizagem.
O modelo PPO começa com o modelo SFT e inicializa a função de valor a partir do modelo de recompensa. Neste ambiente, um prompt aleatório é apresentado e uma resposta é esperada. Uma vez dada a resposta, o episódio termina com a recompensa, determinada pelo modelo de recompensa.
Aprendizagem Contínua: O Ciclo Iterativo
Exceto que a primeira etapa ocorre apenas uma vez, as etapas de geração do modelo de recompensa e PPO são repetidas em ciclos. Esta abordagem iterativa permite a melhoria contínua do modelo ao longo do tempo. A cada ciclo, o modelo coleta mais dados de comparação, treina um novo modelo de recompensa e estabelece uma nova política. Como resultado, o modelo melhora ao longo do tempo em alinhar-se às preferências humanas.
4. A Arquitetura Transformer: Uma Base para o ChatGPT
4.1 Visão Geral
A base do ChatGPT é um tipo de rede neural chamada arquitetura transformer. Uma rede neural, em essência, emula a maneira como o cérebro humano funciona, processando informações por meio de múltiplas camadas de nós interconectados. Imagine uma orquestra sinfônica: cada músico tem um papel, passando melodias (informações) de um lado para o outro, tudo harmonizando para criar música (uma saída).
A arquitetura transformer se especializa no processamento de sequências de palavras aproveitando um mecanismo conhecido como "auto-atenção". O mecanismo de auto-atenção é semelhante à maneira como um leitor pode revisitar uma frase ou parágrafo anterior para compreender o contexto de uma palavra ou frase nova. O transformer avalia todas as palavras em uma sequência para discernir o contexto e as relações entre elas.
4.2 Camadas do Transformer
A arquitetura transformer consiste em múltiplas camadas, cada uma composta por duas subcamadas principais: a camada de auto-atenção e a camada feedforward. A camada de auto-atenção calcula a relevância de cada palavra em uma sequência, enquanto a camada feedforward aplica transformações não lineares aos dados de entrada. Por meio desta configuração, o transformer aprende a compreender e navegar pelas relações entre as palavras em uma sequência.
4.3 Treinando o Transformer
Durante o treinamento, o transformer recebe dados de entrada (uma frase, por exemplo) e é solicitado a prever um resultado com base nessa entrada. O modelo é então atualizado de acordo com o quão próxima está sua previsão em relação à saída. Dessa maneira, o transformer aprimora sua capacidade de entender o contexto e as relações entre palavras em uma sequência.
É como ensinar novas palavras a uma criança: você apresenta novas palavras a ela (entrada), ela faz um palpite sobre o significado (previsão) e você a corrige se estiver errada (atualizando o modelo), thereby aiding their language acquisition process.
4.4 Desafios ao Usá-lo
No entanto, como qualquer ferramenta poderosa, a arquitetura transformer vem com seus desafios. O potencial desses modelos para gerar conteúdo prejudicial ou tendencioso é uma preocupação significativa, pois eles podem inadvertidamente aprender e perpetuar vieses presentes nos dados de treinamento. Pense em um papagaio que repete qualquer coisa que ouve, independentemente da adequação ou correção política das palavras.
Os desenvolvedores desses modelos se esforçam para incorporar "guarda-corpos" para mitigar esses riscos. Ainda assim, esses guarda-corpos podem levar a novos problemas devido a perspectivas e interpretações diversas de vieses.
Como todos sabemos, o poder de geração do ChatGPT beneficia-se das grandes fontes de dados de seu modelo GPT, então, em seguida, discutiremos os dados que dão suporte ao ChatGPT.
5. O Papel de Conjuntos de Dados Diversos
5.1 ChatGPT: Um Produto de Pré-Treinamento Extensivo
O ChatGPT, que se apoia na arquitetura GPT-3 (Generative Pre-trained Transformer 3), é um robusto modelo de linguagem alimentado pelo monumental conjunto de dados WebText2. Para entender a escala, imagine uma biblioteca repleta com mais de 45 terabytes de dados de texto, equivalente a milhares de vezes o conteúdo da Wikipedia.
A escala colossal do WebText2 permite que o ChatGPT aprenda padrões e associações entre palavras e frases em uma escala inimaginável, permitindo que gere respostas coerentes e contextualmente relevantes.
5.2 Ajuste fino do ChatGPT para conversas
Embora o ChatGPT herde sua espinha dorsal da arquitetura GPT-3, ele foi refinado e otimizado para aplicativos conversacionais específicos. Isso resulta em uma experiência de interação mais envolvente e personalizada para os usuários que interagem com o ChatGPT.
A OpenAI, criadora do ChatGPT, disponibilizou um conjunto de dados exclusivo chamado Persona-Chat, projetado especificamente para treinar modelos de IA conversacional. Este conjunto de dados consiste em mais de 160.000 diálogos entre participantes humanos; cada um atribuído a uma persona distinta que delineia seus interesses, personalidade e histórico. É como se o ChatGPT fosse um participante em milhares de cenários de interpretação de papéis, aprendendo a adaptar suas respostas ao contexto e à persona da conversa.
5.3 Uma Variedade de Conjuntos de Dados: O Segredo
Além do Persona-Chat, o ChatGPT é refinado usando vários outros conjuntos de dados conversacionais:
Cornell Movie Dialogs Corpus: Este conjunto de dados abriga diálogos entre personagens em roteiros de filmes, com mais de 200.000 trocas conversacionais entre mais de 10.000 pares de personagens. Pense nisso como o ChatGPT estudando os roteiros de centenas de filmes, absorvendo os matizes linguísticos de diferentes gêneros e contextos.
Ubuntu Dialogue Corpus: Uma compilação de diálogos multi-turnos entre usuários buscando suporte técnico e a equipe de suporte da comunidade Ubuntu. Esses dados podem simular conversas de suporte técnico para ajudar o ChatGPT a aprender terminologia específica e métodos de resolução de problemas. E esta conversa um milhão de vezes.
É como se o ChatGPT participasse de mais de um milhão de conversas de suporte técnico, aprendendo a terminologia específica e as abordagens de resolução de problemas.
DailyDialog: Este conjunto de dados compreende diálogos humanos sobre vários tópicos, desde bate-papos da vida cotidiana até discussões sobre questões sociais. Usando esse banco de dados, o ChatGPT é como participar de inúmeras discussões para entender o tom, o clima e os temas que compõem a conversa humana diária.
Além disso, o ChatGPT aproveita uma vasta quantidade de dados não estruturados encontrados na internet, incluindo livros, sites e outras fontes de texto. Isso amplia sua compreensão da estrutura e padrões da linguagem, que pode ser refinada para aplicativos específicos, como análise de sentimentos ou gerenciamento de diálogo.
5.4 A Escala do ChatGPT
Embora semelhante na abordagem à série GPT, o ChatGPT é um modelo distinto com diferenças na arquitetura e nos dados de treinamento. O ChatGPT é composto por 1,5 bilhão de parâmetros, menor em escala que os impressionantes 175 bilhões de parâmetros do GPT-3, mas não menos impressionante.
Resumindo, os dados de treinamento para refinar o ChatGPT são predominantemente conversacionais, elaborados para incluir diálogos entre humanos, permitindo que o ChatGPT gere respostas naturais e envolventes. Pense em seu treinamento não supervisionado como ensinar uma criança a se comunicar, expondo-a a uma miríade de conversas e deixando que encontre padrões e faça sentido de tudo.
Depois do pré-treinamento, o ChatGPT também precisa ser capaz de entender perguntas e construir respostas a partir dos dados. Isso envolve a fase de inferência, apoiada pelo processamento de linguagem natural e gerenciamento de diálogo; vamos descobrir.
6. Processamento de Linguagem Natural:
O Processamento de Linguagem Natural (NLP) é um subcampo da inteligência artificial que foca em permitir que computadores entendam, interpretem e gerem linguagem humana. É uma tecnologia crítica na era digital de hoje, pois fundamenta muitos aplicativos como análise de sentimentos, chatbots, reconhecimento de fala e tradução de idiomas.
As tecnologias de PNL podem beneficiar significativamente os negócios, automatizando tarefas, aprimorando o atendimento ao cliente e extraindo insights valiosos de fontes de dados como feedbacks de clientes e postagens em redes sociais.
No entanto, a linguagem humana é inerentemente complexa e ambígua, apresentando dificuldades de interpretação por computador. Para lidar com isso, os algoritmos de PNL são treinados em enormes quantidades de dados, permitindo que reconheçam padrões e aprendam nuances da linguagem. Esses algoritmos também devem ser constantemente refinados e atualizados para acompanhar o uso da linguagem em constante evolução e seu contexto.
O PNL decompõe entradas de linguagem (por exemplo, frases ou parágrafos) em componentes menores e analisa seus significados e relacionamentos para gerar insights ou respostas. Ele emprega várias técnicas, incluindo modelagem estatística, aprendizado de máquina e deep learning, para discernir padrões e aprender com grandes quantidades de dados, interpretando e gerando linguagem com precisão.
O ChatGPT é um exemplo prático de PNL em ação. Ele é projetado para se envolver em conversas multi-turnos com os usuários que se sintam naturais e envolventes. Isso envolve o uso de algoritmos e técnicas de aprendizado de máquina para entender o contexto de uma conversa e mantê-lo ao longo de múltiplas trocas com o usuário.
Essa capacidade de manter um contexto ao longo de uma conversa prolongada é conhecida como Gerenciamento de Diálogo. Ele permite que programas de computador interajam com pessoas de uma maneira que se assemelha mais a uma conversa do que a uma série de interações isoladas. Este aspecto do PNL é vital, pois constrói confiança e engajamento com os usuários, levando a melhores resultados tanto para o usuário quanto para a organização que usa o programa.
7. Avaliação de Desempenho do ChatGPT
Três Critérios Principais
A avaliação do ChatGPT é um passo crucial para garantir sua eficácia e confiabilidade. Como o modelo é treinado com base em interações humanas, sua avaliação também depende predominantemente da entrada humana, na qual avaliadores de qualidade avaliam as saídas do modelo.
Para evitar que o modelo se ajuste excessivamente ao julgamento dos avaliadores que participaram da fase de treinamento, a avaliação emprega um conjunto de testes composto por prompts de usuários da base de usuários da OpenAI que não estão incluídos nos dados de treinamento. Isso permite uma avaliação imparcial do desempenho do modelo em cenários do mundo real.
A avaliação do modelo é realizada com base em três critérios principais:
Critério | Explicação |
|---|---|
Utilidade | Mede a capacidade do modelo de cumprir as instruções do usuário e intuir as intenções do usuário. |
Veracidade | Avalia a propensão do modelo para “alucinações”, que se refere à sua tendência de inventar fatos. Para isso, o conjunto de dados TruthfulQA é usado. |
Inocuidade | Os avaliadores de qualidade avaliam se a saída do modelo é apropriada, respeita classes protegidas e evita conteúdo pejorativo. Este aspecto da avaliação emprega os conjuntos de dados RealToxicityPrompts e CrowS-Pairs. |
Desempenho Zero-Shot
O ChatGPT também é avaliado por seu desempenho "zero-shot", ou seja, sua capacidade de lidar com tarefas sem exemplos prévios em tarefas tradicionais de PNL como perguntas e respostas, compreensão de leitura e sumarização. Curiosamente, os desenvolvedores notaram regressões de desempenho em comparação com o GPT-3 em algumas tarefas. Este fenômeno, conhecido como "alignment tax", mostra que o procedimento de alinhamento baseado em RLHF do modelo pode reduzir o desempenho em tarefas específicas.
No entanto, uma técnica de pré-treinamento misto pode mitigar substancialmente essas regressões de desempenho. Durante o treinamento do modelo PPO por meio da descida do gradiente, as atualizações do gradiente são computadas combinando os gradientes do modelo SFT e dos modelos PPO. Este processo ajuda a melhorar o desempenho do modelo em tarefas específicas.
8. Limitações e Melhorias no ChatGPT
O ChatGPT, como qualquer modelo de IA, tem limitações, apesar de suas capacidades notáveis.
Respostas incorretas ou sem sentido.
O ChatGPT, às vezes, pode produzir respostas plausíveis, mas incorretas ou sem sentido. Isso se deve principalmente ao fato de seus dados não serem totalmente corretos. Como discutimos antes, o ChatGPT receberá várias fontes de dados durante o treinamento, incluindo livros e a Internet. Então, quais são as cores dos semáforos?
Se existirem respostas erradas em sua fonte de dados, como preto, branco e amarelo, o ChatGPT também poderá gerar respostas erradas.
Além disso, quando o modelo é treinado para ser mais cauteloso, ele pode se recusar a responder perguntas que pode lidar corretamente. E durante o treinamento supervisionado, o conhecimento do modelo, e não do demonstrador humano, influencia a resposta desejada.
Sensível a ajustes na entrada
O modelo também é sensível a ajustes na entrada. Isso significa que ele pode produzir uma resposta muito diferente assim que você ajustar o comando ou pedir que ele responda à pergunta novamente. Por exemplo, o modelo responderá corretamente consultas que anteriormente alegou não saber. Ou mude a resposta da anterior (Sim para Não). Além disso, o viés de dados e a superotimização conhecida do treinamento do ChatGPT também causaram alguns problemas. Você pode encontrar frases e declarações longas ou excessivamente usadas na saída do ChatGPT, como reafirmar seu relacionamento com a OpenAI.
No cenário ideal, o ChatGPT faria perguntas de esclarecimento para consultas ambíguas. No entanto, os modelos atuais tendem a adivinhar as intenções do usuário. Embora esforços tenham sido feitos para recusar solicitações inadequadas, o modelo ainda pode responder a instruções prejudiciais ou exibir comportamentos tendenciosos. Para combater isso, a OpenAI emprega a API de Moderação para avisar ou bloquear determinados conteúdos inseguros, mas ainda podem existir falsos negativos e positivos.
Apesar dessas limitações, os avanços do GPT-3 para o GPT-4 são promissores, mostrando a capacidade aprimorada do modelo de gerar texto plausível e preciso. Olhando para frente, a expectativa é que essas melhorias continuem e as limitações diminuam a cada nova iteração do modelo GPT.
Conclusão
Em conclusão, o ChatGPT, um produto da IA avançada do GPT, opera por meio de uma combinação de arquitetura transformer, aprendizado por reforço a partir de feedback humano e conjuntos de dados diversos. Ele aproveita o Processamento de Linguagem Natural para entender e gerar texto semelhante ao humano, facilitando interações envolventes. Embora impressionante, é importante observar que o desempenho do sistema não é perfeito e requer avaliações de melhoria contínua. Apesar de suas limitações, o ChatGPT é uma notável inovação na tecnologia de IA, empurrando os limites da interação homem-máquina.