Curieux de découvrir l'IA qui révolutionne les conversations ? Vous êtes-vous déjà demandé comment ChatGPT parvient à comprendre vos questions et à formuler des réponses cohérentes ? Plongez dans les rouages complexes de cette technologie de rupture, de ses fondements GPT au rôle du traitement du langage naturel et au-delà. Explorez ses performances, limites et possibilités futures. Démêlez la science derrière votre partenaire conversationnel numérique, ChatGPT.
À propos de GPT et ChatGPT
1.1 Définition des modèles GPT
GPT, ou Generative Pre-trained Transformers, est une avancée majeure dans l'intelligence artificielle. Ils sont utilisés dans de nombreuses applications d'IA générative, y compris ChatGPT. Construits sur l'architecture des transformers, les modèles GPT peuvent produire des textes et autres types de contenu semblables à l'homme, comme des images et de la musique. De plus, vous pouvez l'utiliser pour répondre à des questions, avoir des conversations avec eux, gérer tout ce qui est relatif au texte, et plus encore.1.2 Introduction to ChatGPT
ChatGPT is a derivative of GPT models, developed by OpenAI. It operates similarly to its sibling model, InstructGPT, but with a conversational approach. The uniqueness of this difference gives ChatGPT an interactive function, enabling it to communicate with users and further complete question answering, error identification, etc.
1.2 Introduction à ChatGPT
ChatGPT est un dérivé des modèles GPT, développé par OpenAI. Il fonctionne de manière similaire à son modèle frère, InstructGPT, mais avec une approche conversationnelle. L'unicité de cette différence confère à ChatGPT une fonction interactive, lui permettant de communiquer avec les utilisateurs et de compléter davantage la réponse aux questions, l'identification des erreurs, etc.
1.3 Comparaison de ChatGPT avec les moteurs de recherche
Des moteurs de recherche comme Google et des moteurs de calcul comme Wolfram Alpha interagissent également avec les utilisateurs via un champ de saisie texte à ligne unique. Cependant, alors que la force de Google réside dans l'exécution de vastes recherches dans des bases de données pour fournir une série de correspondances et que Wolfram Alpha est équipé pour analyser les questions liées aux données et effectuer des calculs, la force de ChatGPT est sa capacité à analyser les requêtes et à fournir des réponses complètes basées sur une vaste quantité d'informations textuelles numériquement accessibles.
Par exemple, en recherchant "comment déverrouiller un iPhone" sur des moteurs de recherche comme Google, vous obtiendrez des articles avec des solutions créées par différents sites Web. Vous devez parcourir ces articles pour obtenir la solution.
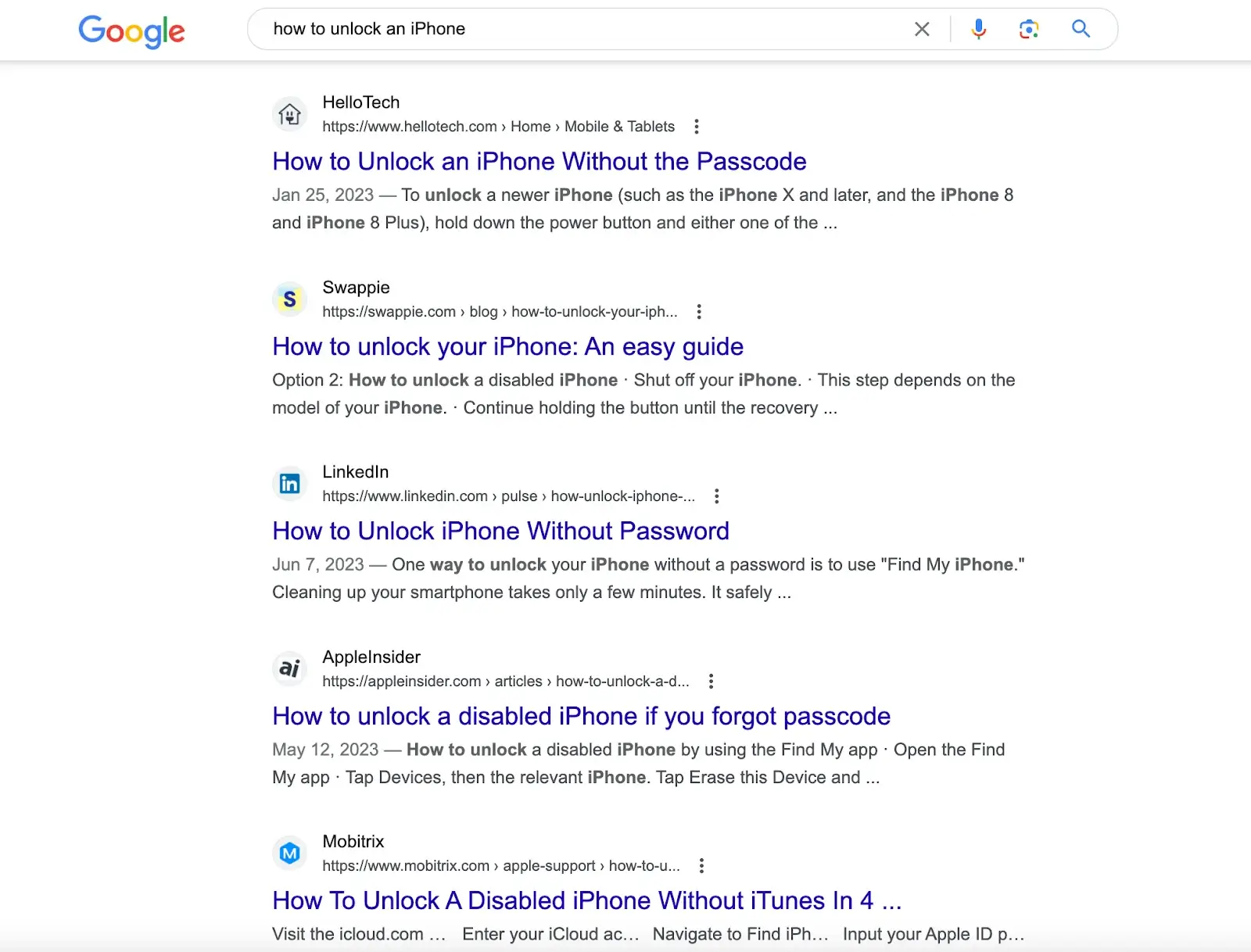
Mais si vous entrez cette question dans ChatGPT, il vous donnera directement la réponse. La réponse provient de son ensemble de données pré-entraîné, qui contient également le contenu des liens fournis par les moteurs de recherche.
En d'autres termes, vous communiquez avec une entité avisée capable de générer des résultats de requête plutôt que d'obtenir simplement ces sources de contenu via les moteurs de recherche. Cependant, il convient de noter qu'il est actuellement inférieur aux moteurs de recherche en termes d'actualité car les informations de ChatGPT sont basées sur les données formées à partir de 2021.
2. Comment fonctionne ChatGPT
Le fonctionnement de ChatGPT est divisé en deux phases : le pré-entraînement, ou la collecte de données, et l'inférence, ou la réponse aux invites de l'utilisateur. Comme nous l'avons déjà dit, ChatGPT est similaire à Google. Après un entraînement approfondi, ChatGPT peut comprendre les questions et générer des réponses à partir de sa base de données. La seule différence est qu'il générera des réponses directes, pas des liens lorsque vous enverrez une invite.
ChatGPT utilise des réseaux de neurones en deep learning pour générer des textes semblables à l'homme. Tout comme le cerveau humain fait des prédictions et tire des conclusions sur la base de connaissances antérieures, ChatGPT est formé sur une immense quantité de données, ou jetons, essentiellement des unités de texte qui peuvent représenter des mots isolés ou des parties de mots complexes.
Contrairement aux modèles d'IA traditionnels entraînés à l'aide d'une approche supervisée associant chaque entrée à une sortie spécifique, ChatGPT utilise une approche de pré-entraînement non supervisée. Ici, le modèle apprend la structure inhérente et les schémas dans les données d'entrée sans avoir de tâche particulière à l'esprit, comprenant ainsi la syntaxe et la sémantique du langage et lui permettant de générer un texte significatif de manière conversationnelle. Ce pré-entraînement est la puissance transformatrice derrière les vastes connaissances et capacités de ChatGPT. Le modèle peut développer un large éventail de réponses en fonction de l'entrée reçue en traitant des quantités colossales de données à l'aide d'un modélisation du langage basée sur des transformers. Cette méthodologie forme les bases des connaissances apparemment illimitées de ChatGPT et de ses capacités conversationnelles.
Cet entraînement commence par exposer le modèle à une vaste quantité de contenu écrit par l'homme : des livres et des articles au contenu Internet. Le modèle apprend ainsi des schémas et des relations à partir de ces jetons, formant un réseau de neurones en deep learning. Ce réseau, similaire à un algorithme multicouche qui imite le fonctionnement du cerveau humain, permet au modèle de générer un texte contextuellement pertinent et humain.
Ce qui est remarquable avec ChatGPT, c'est sa capacité à générer de longs textes au lieu de simplement prédire le mot suivant dans une phrase. OpenAI a révélé sa capacité à entraîner ChatGPT à cet égard grâce à l'apprentissage par renforcement des commentaires humains (RLHF), lui permettant de générer des phrases, des paragraphes et même des chaînes de texte plus longues pour produire des réponses cohérentes. Cet entraînement implique un modèle de récompense dans lequel le formateur classe les différentes réactions générées par le modèle pour aider l'IA à comprendre ce qui constitue une bonne réponse.
Une autre force soutenant le fonctionnement de ChatGPT est son énorme nombre de paramètres. GPT-3 est de 175 milliards, et GPT-4 n'a pas révélé le nombre spécifique, mais on peut supposer qu'il pourrait être plus important. Chaque invite envoyée par l'utilisateur doit être traitée par ces paramètres, et la sortie sera affectée par sa valeur et son poids. De plus, le hasard a été intégré dans ces paramètres pour éviter des réponses mécaniques et répétitives et garder les choses fraîches. Par exemple, vous pouvez utiliser la même invite et générer différents résultats.
3. Apprentissage par renforcement des commentaires humains (RLHF)
Selon OpenAI, la formation de ChatGPT est en grande partie basée sur la méthode d'apprentissage par renforcement des commentaires humains (RLHF). Cette méthode implique une série d'étapes distinctes pour produire un modèle capable de générer des réponses souhaitables.
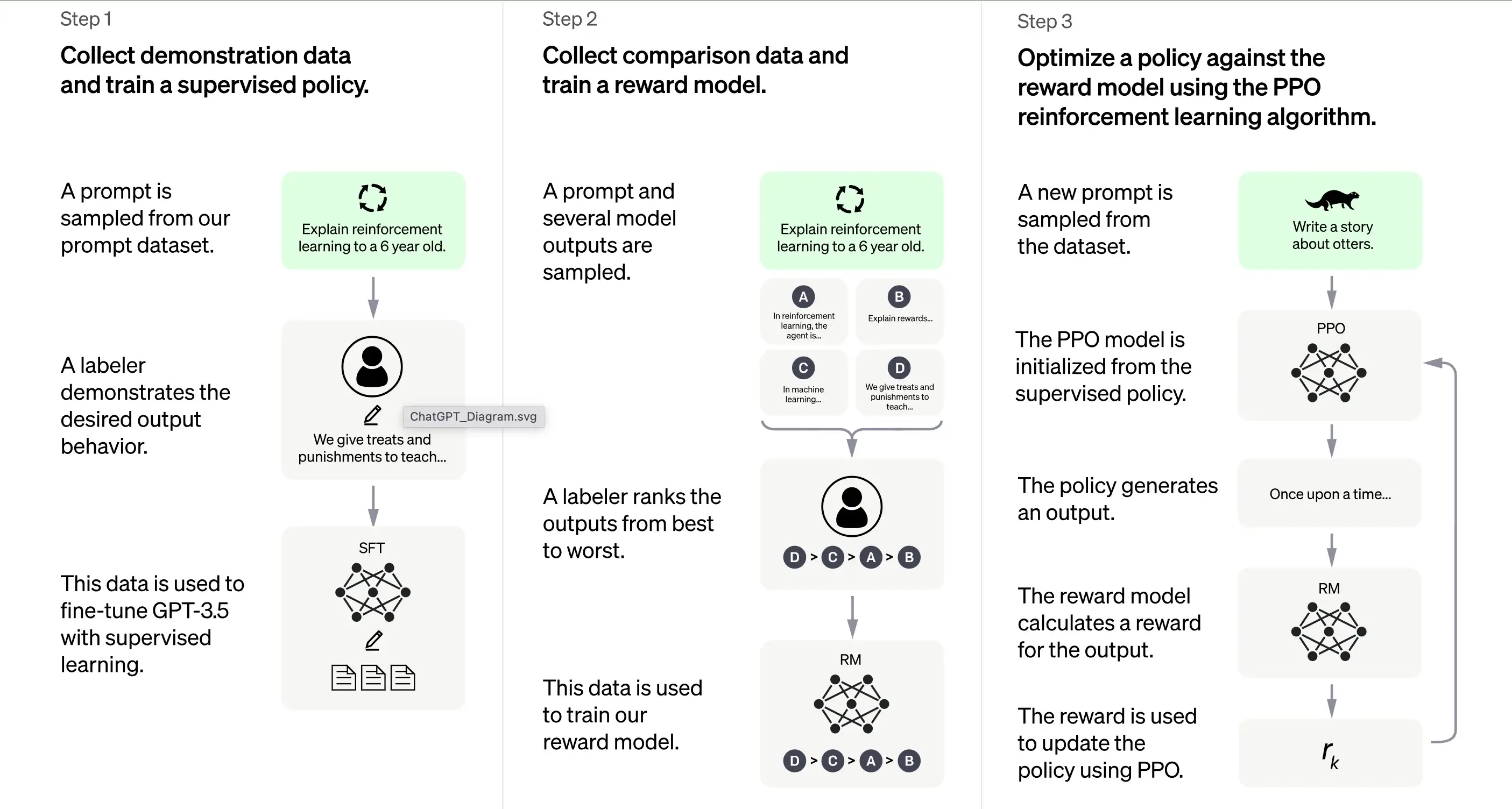
1. Formation initiale : réglage fin supervisé (SFT)
La première étape de la formation de ChatGPT est le réglage fin supervisé (SFT). Cette phase implique l'utilisation d'un petit ensemble de données soigneusement sélectionnées composées d'invites et de leurs réponses correspondantes produites par des annotateurs humains. La formation vise à produire une sortie correcte de haute qualité pour ChatGPT. Selon OpenAI, le modèle de formation à ce stade est basé sur la série de modèles GPT-3.5.
La première étape de la formation de ChatGPT est le réglage fin supervisé (SFT), un modèle de stratégie supervisé formé en collectant des données de démonstration auprès d'annotateurs humains. ChatGPT utilise deux sources d'invites : un étiquetage direct par les développeurs ou les demandes d'API d'OpenAI. L'ensemble de données résultant, petit et de haute qualité, soigneusement sélectionné, est utilisé pour optimiser un modèle linguistique pré-entraîné. Au lieu d'optimiser le modèle GPT-3 d'origine, les développeurs de ChatGPT ont choisi un modèle GPT-3.5 pré-entraîné, probablement text-davinci-003. Cette décision a été prise pour créer un chatbot généraliste comme ChatGPT sur un modèle "code" plutôt que sur un modèle textuel pur.
Cependant, le modèle SFT peut encore ne pas être attentif à l'utilisateur et souffrir d'un désalignement. Pour surmonter ce problème, les développeurs classent maintenant les différentes sorties du modèle SFT pour créer un modèle de récompense.
2. Génération du modèle de récompense
Cette étape vise à générer une fonction objective, le modèle de récompense. Ce modèle note les sorties du modèle SFT, avec un score proportionnel à la mesure dans laquelle la classe s'attend à ces sorties. Plus les attentes sont satisfaites, plus le score est élevé, et vice versa.
Les annotateurs noteront manuellement la sortie du modèle SFT en fonction de préférences spécifiques et de critères communs qu'ils acceptent de suivre. En fin de compte, ce processus contribue à créer un système automatisé capable d'imiter les préférences humaines.
Son flux de travail est grosso modo le suivant :
Sélectionner une liste d'invites, et le modèle SFT génère de multiples sorties (toute sortie entre 4 et 9) pour chaque invite.
L'annotateur classe les sorties de la meilleure à la pire, créant ainsi un nouvel ensemble de données étiqueté avec les "rangs" comme étiquettes. Cet ensemble de données est environ dix fois plus grand que l'ensemble de données sélectionné utilisé par le modèle SFT.
Cet ensemble de données formera ensuite le modèle de récompense (RM). Le modèle prend comme entrée certaines sorties du modèle SFT et les classe par ordre de préférence.
Jusqu'à présent, nous avons discuté de la façon dont le modèle est initialement formé à l'aide d'un réglage fin supervisé, puis affiné à l'aide d'un modèle de récompense. Ces étapes constituent les blocs de base de la formation de ChatGPT. Cependant, le processus se poursuit au-delà de cela. Le système entre alors dans une phase d'amélioration itérative grâce à une technique appelée optimisation de la stratégie proximale.
3. Amélioration itérative : optimisation de la stratégie proximale (PPO)
La dernière étape de la formation implique l'application de l'optimisation de la stratégie proximale (PPO). Cette technique utilise le modèle de récompense comme fonction de valeur pour estimer le rendement attendu d'une action. Il applique ensuite une "fonction d'avantage", représentant la différence entre les rendements attendus et réels, pour mettre à jour la stratégie.
Le PPO est un algorithme "on-policy" qui apprend de et met à jour la stratégie actuelle en fonction des actions de l'agent et des récompenses reçues. Cette conception aide à assurer un apprentissage stable en limitant l'ampleur du changement de stratégie à chaque mise à jour, empêchant ainsi le modèle d'apporter des changements drastiques qui pourraient perturber le processus d'apprentissage.
Le modèle PPO commence avec le modèle SFT et initialise la fonction de valeur à partir du modèle de récompense. Dans cet environnement, une invite aléatoire est présentée et une réponse est attendue. Une fois la réponse donnée, l'épisode se termine avec la récompense, déterminée par le modèle de récompense.
Apprentissage continu : le cycle itératif
À l'exception du fait que la première étape ne se produit qu'une seule fois, les étapes de génération du modèle de récompense et de PPO sont répétées en cycles. Cette approche itérative permet une amélioration continue du modèle au fil du temps. À chaque cycle, le modèle collecte plus de données de comparaison, entraîne un nouveau modèle de récompense et établit une nouvelle stratégie. En conséquence, le modèle s'améliore avec le temps pour s'aligner sur les préférences humaines.
L'architecture Transformer : une base pour ChatGPT
4.1 Aperçu
Le socle de ChatGPT est un type de réseau de neurones appelé architecture Transformer. Un réseau de neurones, pour l'essentiel, émule le fonctionnement du cerveau humain en traitant les informations à travers plusieurs couches de nœuds interconnectés. Imaginez un orchestre symphonique : chaque musicien a un rôle, se transmettant des mélodies (informations) dans un sens et dans l'autre, le tout s'harmonisant pour créer de la musique (une sortie).
L'architecture Transformer se spécialise dans le traitement de séquences de mots en exploitant un mécanisme appelé "auto-attention". Le mécanisme d'auto-attention s'apparente à la façon dont un lecteur peut revisiter une phrase ou un paragraphe précédent pour comprendre le contexte d'un nouveau mot ou d'une nouvelle expression. Le transformateur évalue tous les mots d'une séquence pour discerner le contexte et les relations entre eux.
4.2 Couches du Transformer
L'architecture Transformer se compose de plusieurs couches, chacune composée de deux sous-couches principales : la couche d'auto-attention et la couche d'alimentation directe. La couche d'auto-attention calcule la pertinence de chaque mot dans une séquence, tandis que la couche d'alimentation directe applique des transformations non linéaires aux données d'entrée. Grâce à cette configuration, le Transformer apprend à comprendre et à naviguer dans les relations entre les mots d'une séquence.
4.3 Formation du Transformer
Pendant la formation, le transformateur reçoit des données d'entrée (une phrase, par exemple) et on lui demande de prédire un résultat sur la base de cette entrée. Le modèle est ensuite mis à jour en fonction de la proximité entre sa prédiction et la sortie. De cette façon, le transformateur affine sa capacité à comprendre le contexte et les relations entre les mots dans une séquence.
C'est comme apprendre de nouveaux mots à un enfant : on leur présente de nouveaux mots (entrée), ils font une supposition quant à la signification (prédiction) et on les corrige s'ils se trompent (mise à jour du modèle), aidant ainsi leur processus d'acquisition du langage.
4.4 Défis de l'utilisation
Cependant, comme tout outil puissant, l'architecture Transformer présente ses défis. Le potentiel de ces modèles à générer du contenu préjudiciable ou biaisé est une préoccupation majeure, car ils peuvent apprendre et perpétuer involontairement les préjugés présents dans les données d'apprentissage. Pensez à un perroquet qui mime tout ce qu'il entend, sans tenir compte de la pertinence ou de la correction politique des mots.
Les développeurs de ces modèles s'efforcent d'intégrer des "garde-fous" pour atténuer ces risques. Pourtant, ces garde-fous pourraient conduire à de nouveaux problèmes en raison des diverses perspectives et interprétations des préjugés.
Comme nous le savons tous, la puissance de génération de ChatGPT bénéficie des vastes sources de données de son modèle GPT, nous allons donc maintenant aborder les données qui soutiennent ChatGPT.
Le rôle des divers ensembles de données
5.1 ChatGPT : un produit d'un pré-entraînement approfondi
ChatGPT, qui s'appuie sur l'architecture GPT-3 (Generative Pre-trained Transformer 3), est un puissant modèle linguistique alimenté par l'ensemble de données monumental WebText2. Pour saisir l'échelle, imaginez une bibliothèque remplie de plus de 45 téraoctets de données textuelles, soit des milliers de fois le contenu de Wikipédia.
L'échelle colossale de WebText2 permet à ChatGPT d'apprendre des schémas et des associations entre les mots et les phrases à une échelle impensable, lui permettant de générer des réponses cohérentes et contextuellement pertinentes.
5.2 Optimisation de ChatGPT pour les conversations
Bien que ChatGPT hérite de sa colonne vertébrale de l'architecture GPT-3, il a été optimisé et affiné pour des applications conversationnelles spécifiques. Cela se traduit par une expérience d'interaction plus engageante et personnalisée pour les utilisateurs interagissant avec ChatGPT.
OpenAI, les créateurs de ChatGPT, a mis à disposition un ensemble de données unique appelé Persona-Chat, spécialement conçu pour la formation de modèles d'IA conversationnels. Cet ensemble de données se compose de plus de 160 000 dialogues entre participants humains ; chacun se voit attribuer une personnalité distinctive décrivant ses intérêts, sa personnalité et ses antécédents. C'est comme si ChatGPT avait été un participant à des milliers de scénarios de jeu de rôle, apprenant à adapter ses réponses au contexte et à la personnalité de la conversation.
5.3 Une variété d'ensembles de données : le secret
Outre Persona-Chat, ChatGPT est optimisé à l'aide de plusieurs autres ensembles de données conversationnels :
Cornell Movie Dialogs Corpus : cet ensemble de données contient des dialogues entre les personnages de scénarios de films, avec plus de 200 000 échanges conversationnels entre plus de 10 000 paires de personnages. Imaginez ChatGPT étudiant les scénarios de centaines de films, absorbant les nuances linguistiques de différents genres et contextes.
Ubuntu Dialogue Corpus : une compilation de dialogues à tours multiples entre des utilisateurs cherchant une assistance technique et l'équipe d'assistance de la communauté Ubuntu. Ces données peuvent simuler des conversations d'assistance technique pour aider ChatGPT à apprendre une terminologie spécifique et des méthodes de résolution de problèmes. Et cette conversation un million de fois.
C'est comme si ChatGPT avait assisté à plus d'un million de conversations d'assistance technique, apprenant la terminologie spécifique et les approches de résolution de problèmes.
DailyDialog : cet ensemble de données comprend des dialogues humains sur divers sujets, des discussions quotidiennes aux discussions sur les problèmes sociaux. En utilisant cette base de données, ChatGPT est comme rejoindre d'innombrables discussions pour comprendre le ton, l'humeur et les thèmes qui composent la conversation humaine quotidienne.
En outre, ChatGPT exploite une vaste quantité de données non structurées trouvées sur Internet, notamment des livres, des sites Web et d'autres sources textuelles. Cela élargit sa compréhension de la structure et des schémas linguistiques, qui peuvent être optimisés pour des applications spécifiques telles que l'analyse de sentiments ou la gestion du dialogue.
5.4 L'échelle de ChatGPT
Bien que similaire dans son approche à la série GPT, ChatGPT est un modèle distinct avec des différences dans l'architecture et les données d'apprentissage. ChatGPT comprend 1,5 milliard de paramètres, plus petit que les étonnants 175 milliards de paramètres du GPT-3, mais néanmoins impressionnant.
En résumé, les données d'apprentissage pour optimiser ChatGPT sont principalement conversationnelles, organisées pour inclure des dialogues entre humains, permettant à ChatGPT de générer des réponses naturelles et engageantes. Pensez à son apprentissage non supervisé comme apprendre à un enfant à communiquer en l'exposant à une myriade de conversations et en le laissant trouver des schémas et leur donner un sens.
Après le pré-entraînement, ChatGPT doit également être capable de comprendre les questions et de construire des réponses à partir des données. Cela implique la phase d'inférence, soutenue par le traitement du langage naturel et la gestion du dialogue ; découvrons-le.
6. Le traitement du langage naturel :
Le traitement du langage naturel (TAL ou NLP en anglais) est un sous-domaine de l'intelligence artificielle qui se concentre sur la possibilité pour les ordinateurs de comprendre, interpréter et générer le langage humain. C'est une technologie critique à l'ère numérique d'aujourd'hui, car elle sous-tend de nombreuses applications telles que l'analyse de sentiments, les chatbots, la reconnaissance vocale et la traduction automatique.
Les technologies NLP peuvent bénéficier de manière significative aux entreprises en automatisant les tâches, en améliorant le service client et en extrayant des informations précieuses à partir de sources de données telles que les commentaires des clients et les publications sur les médias sociaux.
Cependant, le langage humain est intrinsèquement complexe et ambigu, ce qui présente des difficultés d'interprétation informatique. Pour relever ce défi, les algorithmes NLP sont formés sur d'énormes quantités de données, leur permettant de reconnaître les schémas et d'apprendre les nuances du langage. Ces algorithmes doivent également être constamment affinés et mis à jour pour suivre l'évolution de l'utilisation du langage et de son contexte.
Le NLP décompose les entrées linguistiques (par exemple, des phrases ou des paragraphes) en composants plus petits et analyse leurs significations et relations pour générer des informations ou des réponses. Il utilise diverses techniques, notamment la modélisation statistique, l'apprentissage automatique et l'apprentissage profond, pour discerner les schémas et apprendre à partir de grandes quantités de données, interprétant et générant ainsi le langage avec précision.
ChatGPT est un exemple concret de NLP en action. Il est conçu pour s'engager dans des conversations à tours multiples avec les utilisateurs qui semblent naturelles et engageantes. Cela implique l'utilisation d'algorithmes et de techniques d'apprentissage automatique pour comprendre le contexte d'une conversation et le maintenir sur plusieurs échanges avec l'utilisateur.
Cette capacité à maintenir un contexte sur une conversation prolongée est connue sous le nom de gestion du dialogue. Elle permet aux programmes informatiques d'interagir avec des personnes de manière à ce que cela ressemble plus à une conversation qu'à une série d'interactions ponctuelles. Cet aspect du NLP est vital car il renforce la confiance et l'engagement des utilisateurs, conduisant à de meilleurs résultats à la fois pour l'utilisateur et pour l'organisation utilisant le programme.
7. Évaluation des performances de ChatGPT
Trois critères principaux
L'évaluation de ChatGPT est une étape cruciale pour assurer son efficacité et sa fiabilité. Comme le modèle est formé sur la base d'interactions humaines, son évaluation repose également principalement sur des contributions humaines, dans lesquelles des évaluateurs de la qualité évaluent les sorties du modèle.
Pour éviter que le modèle ne s'adapte excessivement au jugement des évaluateurs ayant participé à la phase de formation, l'évaluation utilise un ensemble de test composé d'invites provenant de la base d'utilisateurs d'OpenAI qui ne sont pas incluses dans les données d'apprentissage. Cela permet une évaluation impartiale des performances du modèle dans des scénarios du monde réel.
L'évaluation du modèle est menée sur trois critères principaux :
Critère | Explication |
Utilité | Mesure la capacité du modèle à se conformer aux instructions de l'utilisateur et à deviner les intentions de l'utilisateur. |
Véracité | Évalue la propension du modèle aux «hallucinations», qui fait référence à sa tendance à inventer des faits. Pour cela, l'ensemble de données TruthfulQA est utilisé. |
Innocuité | Les évaluateurs de la qualité évaluent si la sortie du modèle est appropriée, respecte les classes protégées et évite les contenus désobligeants. Cet aspect de l'évaluation utilise les ensembles de données RealToxicityPrompts et CrowS-Pairs. |
Performance Zero-Shot
ChatGPT est également évalué pour ses performances « zero-shot », c'est-à-dire sa capacité à gérer des tâches sans exemples précédents sur les tâches NLP traditionnelles telles que la réponse aux questions, la compréhension de la lecture et le résumé. Fait intéressant, les développeurs ont remarqué des régressions de performances par rapport au GPT-3 sur certaines tâches. Ce phénomène, connu sous le nom de « taxe d'alignement », montre que la procédure d'alignement basée sur RLHF du modèle peut réduire les performances sur des tâches spécifiques.
Cependant, une technique de mélange de pré-entraînement peut atténuer substantiellement ces régressions de performances. Lors de l'entraînement du modèle PPO par descente de gradient, les mises à jour du gradient sont calculées en combinant les gradients des modèles SFT et PPO. Ce processus contribue à améliorer les performances du modèle sur des tâches spécifiques.
8. Limites et améliorations de ChatGPT
ChatGPT, comme tout modèle d'IA, a des limites malgré ses capacités remarquables.
Réponses incorrectes ou absurdes.
ChatGPT peut parfois produire des réponses plausibles mais incorrectes ou absurdes. Cela est principalement dû au fait que ses données ne sont pas entièrement correctes. Comme nous l'avons déjà dit, ChatGPT recevra diverses sources de données lors de la formation, y compris des livres et Internet. Alors, quelles sont les couleurs des feux de signalisation ?
S'il y a des réponses incorrectes dans sa source de données, comme noir, blanc et jaune, alors ChatGPT peut également produire de mauvaises réponses.
De plus, lorsque le modèle est formé pour être plus prudent, il peut refuser de répondre à des questions qu'il peut gérer correctement. Et lors de la formation supervisée, les connaissances du modèle, et non celles du démonstrateur humain, influencent la réponse souhaitée.
Sensible aux modifications de l'entrée
Le modèle est également sensible aux modifications de l'entrée. Cela signifie qu'il peut produire une réponse très différente une fois que vous ajustez la commande ou lui demandez de répondre à la question à nouveau. Par exemple, le modèle répondra correctement aux requêtes auxquelles il prétendait auparavant ne pas savoir répondre. Ou changez la réponse de la précédente (Oui à Non). En outre, le biais des données et la sur-optimisation connue de la formation de ChatGPT ont également provoqué certains problèmes. Vous pouvez trouver des phrases et des déclarations longues ou trop utilisées dans la sortie de ChatGPT, comme réaffirmer sa relation avec OpenAI.
Dans un scénario idéal, ChatGPT poserait des questions de clarification pour les requêtes ambiguës. Cependant, les modèles actuels ont tendance à deviner les intentions des utilisateurs. Bien que des efforts aient été faits pour refuser les demandes inappropriées, le modèle peut toujours répondre à des instructions préjudiciables ou présenter des comportements biaisés. Pour lutter contre cela, OpenAI utilise l'API Moderation pour avertir ou bloquer certains contenus dangereux, mais il peut encore y avoir de faux négatifs et de faux positifs.
Malgré ces limites, les progrès de GPT-3 à GPT-4 sont prometteurs, montrant la capacité améliorée du modèle à générer des textes plausibles et précis. Dans la perspective future, on s'attend à ce que ces améliorations se poursuivent et que les limites diminuent avec chaque nouvelle itération du modèle GPT.
Conclusion
En conclusion, ChatGPT, produit de l'IA avancée de GPT, fonctionne grâce à une combinaison d'architecture Transformer, d'apprentissage par renforcement des commentaires humains et de divers ensembles de données. Il exploite le traitement du langage naturel pour comprendre et générer un texte semblable à l'homme, facilitant des interactions engageantes. Bien qu'impressionnant, il est important de noter que les performances du système ne sont pas irréprochables et nécessitent des évaluations d'amélioration continues. Malgré ses limites, ChatGPT est une innovation remarquable dans la technologie de l'IA, repoussant les limites de l'interaction homme-machine.