Neugierig auf die KI, die Gespräche revolutioniert? Haben Sie sich jemals gefragt, wie ChatGPT es schafft, Ihre Fragen zu verstehen und schlüssige Antworten zu verfassen? Tauchen Sie ein in die komplizierten Funktionsweisen dieser bahnbrechenden Technologie, von der GPT-Grundlage bis zur Rolle der Verarbeitung natürlicher Sprache und darüber hinaus. Entdecken Sie die Leistung, Einschränkungen und zukünftigen Möglichkeiten. Entdecken Sie die Wissenschaft hinter Ihrem digitalen Gesprächspartner ChatGPT.
1. Über GPT und ChatGPT
1.1 Definition von GPT Modellen
GPT, oder Generative Pre-trained Transformer, ist eine bedeutende Entwicklung in der künstlichen Intelligenz. Sie werden in zahlreichen generativen KI-Anwendungen verwendet, einschließlich ChatGPT. Auf der Transformer-Architektur aufgebaut, können GPT-Modelle menschenähnlichen Text und andere Inhaltsarten wie Bilder und Musik generieren. Außerdem kann man sie verwenden, um Fragen zu beantworten, Gespräche mit ihnen zu führen, alles Textbezogene zu handhaben und mehr.
1.2 Einführung in ChatGPT
ChatGPT ist ein Ableger von GPT-Modellen, entwickelt von OpenAI. Es funktioniert ähnlich wie sein Geschwistermodell InstructGPT, hat aber einen konversationellen Ansatz. Die Einzigartigkeit dieses Unterschieds verleiht ChatGPT eine interaktive Funktion, die es ihm ermöglicht, mit Benutzern zu kommunizieren und Aufgaben wie Fragen beantworten, Fehleridentifikation usw. weiter auszuführen.
1.3 Vergleich von ChatGPT mit Suchmaschinen
Suchmaschinen wie Google und Rechenmaschinen wie Wolfram Alpha interagieren auch über ein einzeiliges Texteingabefeld mit den Benutzern. Allerdings liegt die Stärke von Google in der Ausführung umfangreicher Datenbankabfragen, um eine Reihe von Treffern bereitzustellen, und Wolfram Alpha ist darauf ausgelegt, datenbezogene Fragen zu analysieren und Berechnungen durchzuführen, während ChatGPTs Stärke in der Fähigkeit liegt, Abfragen zu analysieren und umfassende Antworten auf der Grundlage einer großen Menge digital zugänglicher Textinformationen zu liefern.
Wenn Sie beispielsweise nach "Wie entsperre ich ein iPhone" in Suchmaschinen wie Google suchen, erhalten Sie Artikel mit Lösungen, die von verschiedenen Websites erstellt wurden. Sie müssen diese Artikel durchgehen, um die Lösung zu erhalten.
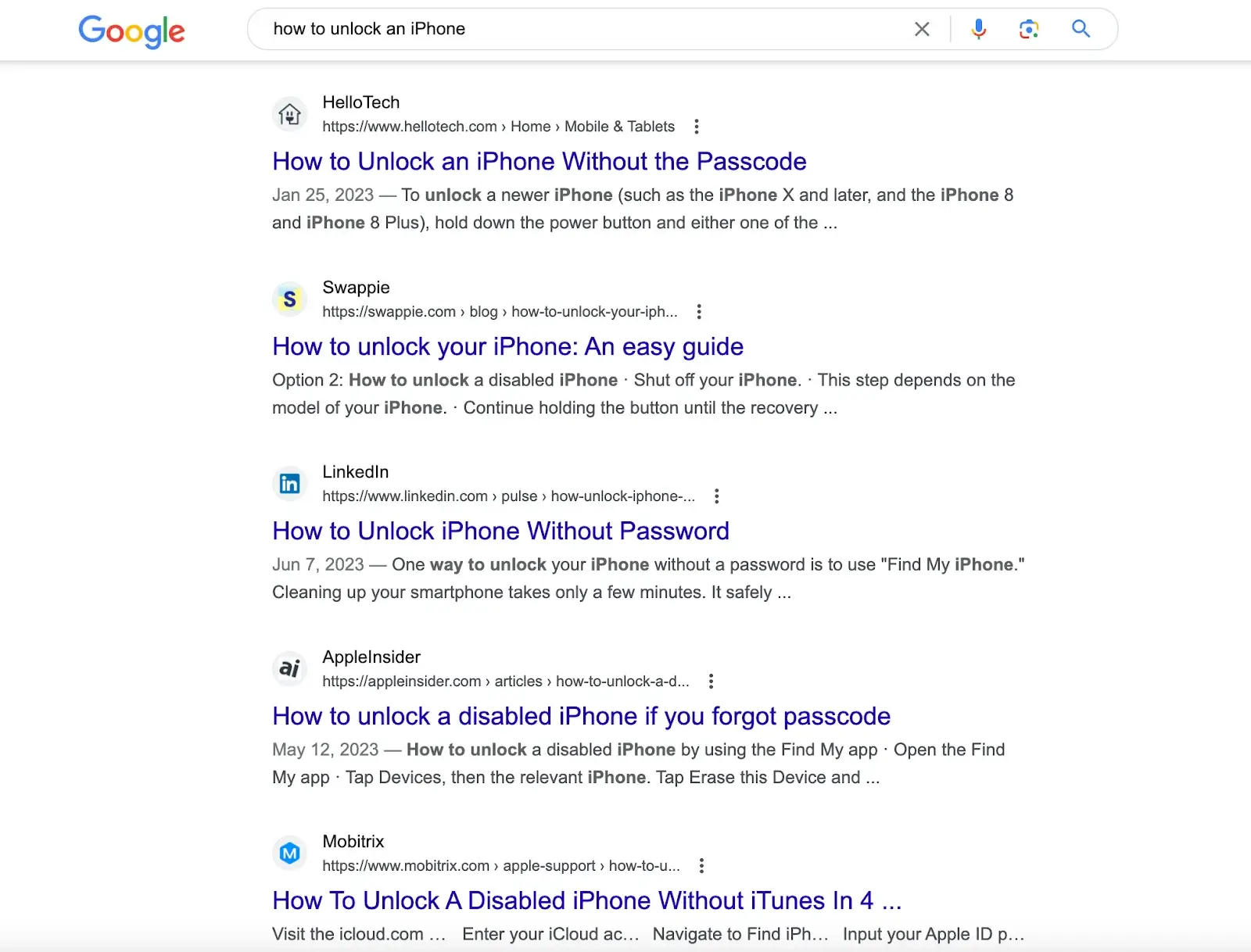
Wenn Sie diese Frage jedoch in ChatGPT eingeben, liefert es Ihnen direkt die Antwort. Die Antwort stammt aus seinem vortrainierten Datensatz, der auch die Inhalte in dem von den Suchmaschinen bereitgestellten Link enthält.
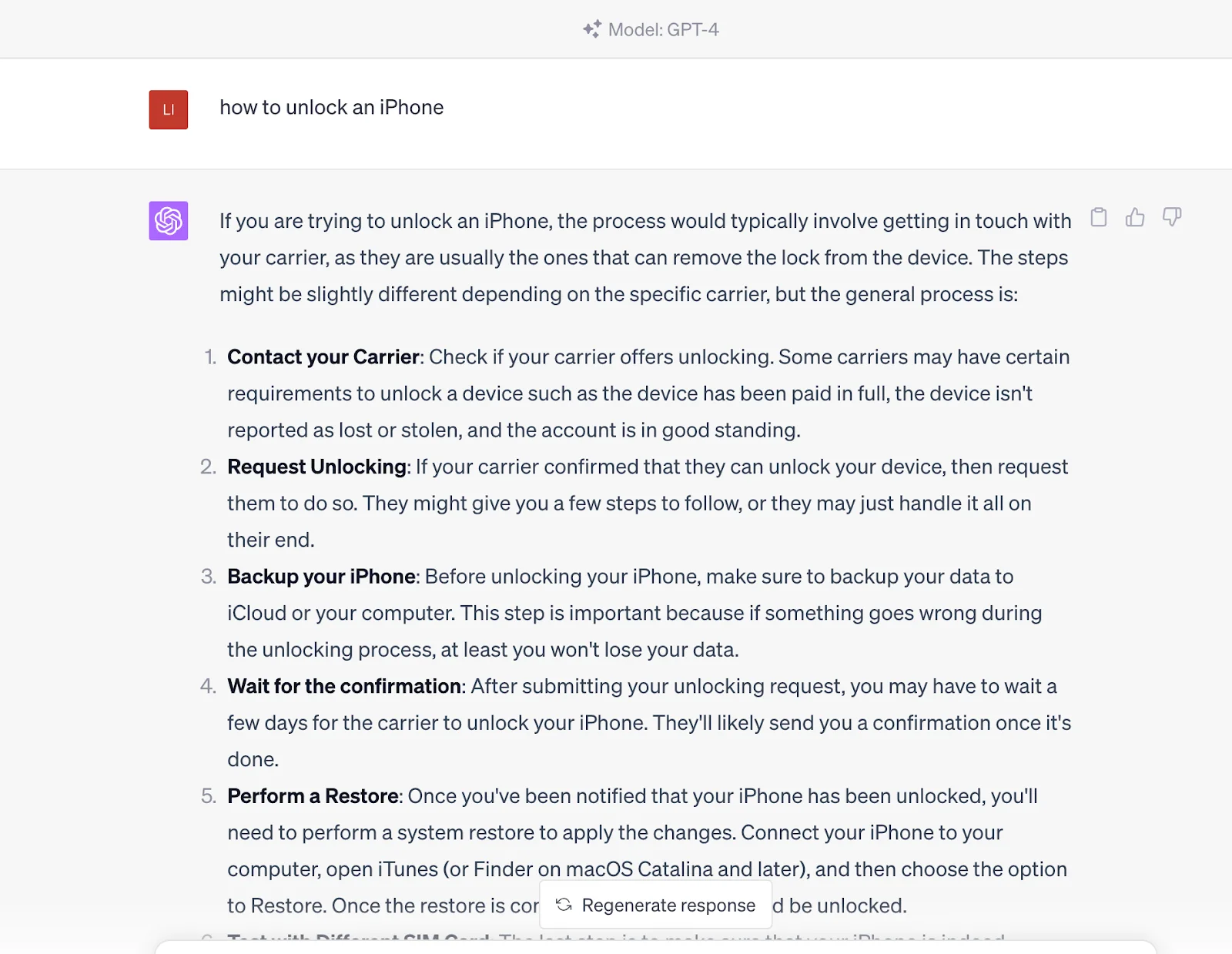
Mit anderen Worten, Sie kommunizieren mit einer wissenden Einheit, die Abfrageergebnisse generieren kann, anstatt nur diese Inhaltsquellen über Suchmaschinen zu erhalten. Es ist jedoch anzumerken, dass ChatGPT derzeit suchmaschinen bezüglich Aktualität unterlegen ist, da sich die Informationen von ChatGPT auf die bis 2021 trainierten Daten stützen.
2. So funktioniert ChatGPT
Die Funktionsweise von ChatGPT gliedert sich in zwei Phasen: Vortraining bzw. Datenerfassung und Inferenz bzw. Reaktion auf Benutzeraufforderungen. Wie bereits erwähnt, ist ChatGPT Google ähnlich. Nach umfangreicher Schulung kann ChatGPT Fragen verstehen und Antworten aus seiner Datenbank generieren. Der einzige Unterschied besteht darin, dass ChatGPT beim Senden einer Aufforderung direkte Antworten und keine Links liefert.
ChatGPT verwendet Deep-Learning-Neuronale Netzwerke, um menschenähnlichen Text zu generieren. Wie das menschliche Gehirn auf der Grundlage vorherigen Wissens Vorhersagen trifft und Schlüsse zieht, wird ChatGPT mit einer enormen Menge an Daten bzw. Token trainiert, im Grunde Textbausteine, die einzelne Wörter oder Teile komplexer Wörter darstellen können.
Im Gegensatz zu herkömmlichen KI-Modellen, die mit einem überwachten Ansatz trainiert werden, bei dem jede Eingabe mit einer bestimmten Ausgabe gepaart wird, verwendet ChatGPT einen unüberwachten Vortrainingsansatz. Hier lernt das Modell die inhärente Struktur und Muster in den Eingabedaten, ohne eine bestimmte Aufgabe im Sinn zu haben, und versteht so die Syntax und Semantik der Sprache und kann aussagekräftigen Text auf konversationelle Weise generieren. Dieses Vortraining ist die bahnbrechende Kraft hinter ChatGPTs enormen Wissen und Fähigkeiten. Das Modell kann basierend auf der erhaltenen Eingabe eine breite Palette von Antworten generieren, indem es kolossale Datenmengen mithilfe der transformerbasierten Sprachmodellierung verarbeitet. Diese Methodik bildet die Grundlage für ChatGPTs scheinbar grenzenloses Wissen und konversationelle Fähigkeiten.
Dieses Training beginnt damit, dass dem Modell eine enorme Menge von menschengeschriebenen Inhalten - von Büchern und Artikeln bis hin zu Internetinhalten - ausgesetzt wird. Das Modell lernt so Muster und Beziehungen aus diesen Token, die ein tiefes neuronales Netz bilden. Dieses Netz, ähnlich einem mehrschichtigen Algorithmus, der die Funktionsweise des menschlichen Gehirns nachahmt, ermöglicht es dem Modell, kontextbezogenen und menschenähnlichen Text zu generieren.
Bemerkenswert an ChatGPT ist seine Fähigkeit, lange Texte zu generieren, anstatt nur das nächste Wort in einem Satz vorherzusagen. OpenAI enthüllte seine Fähigkeit, ChatGPT in dieser Hinsicht durch Bestärkendes Lernen aus menschlichem Feedback (RLHF) zu trainieren, was es ihm ermöglicht, ganze Sätze, Absätze und sogar längere Textfolgen zu generieren, um kohärente Reaktionen zu erzeugen. Dieses Training beinhaltet ein Belohnungsmodell, bei dem der Trainer die verschiedenen vom Modell generierten Reaktionen bewertet, um dem KI zu helfen, zu verstehen, was eine gute Antwort ausmacht.
Eine weitere Stärke, die den Betrieb von ChatGPT unterstützt, ist seine enorme Anzahl von Parametern. GPT-3 sind 175 Milliarden und GPT-4 hat die genaue Zahl nicht preisgegeben, aber es kann spekuliert werden, dass es mehr sein könnte. Jede Aufforderung, die der Benutzer sendet, muss von diesen Parametern verarbeitet werden, und die Ausgabe wird von ihrem Wert und Gewicht beeinflusst. Darüber hinaus wurde Zufälligkeit in diese Parameter einbezogen, um mechanische, repetitive Antworten zu vermeiden und die Dinge frisch zu halten. Sie können beispielsweise die gleiche Aufforderung verwenden und unterschiedliche Ergebnisse erzielen.
3. Bestärkendes Lernen aus menschlichem Feedback (RLHF)
Laut OpenAI basiert die Ausbildung von ChatGPT weitgehend auf der Methode des Bestärkenden Lernens aus menschlichem Feedback (RLHF). Diese Methode umfasst eine Reihe unterschiedlicher Schritte, um ein Modell zu erzeugen, das wünschenswerte Antworten generieren kann.
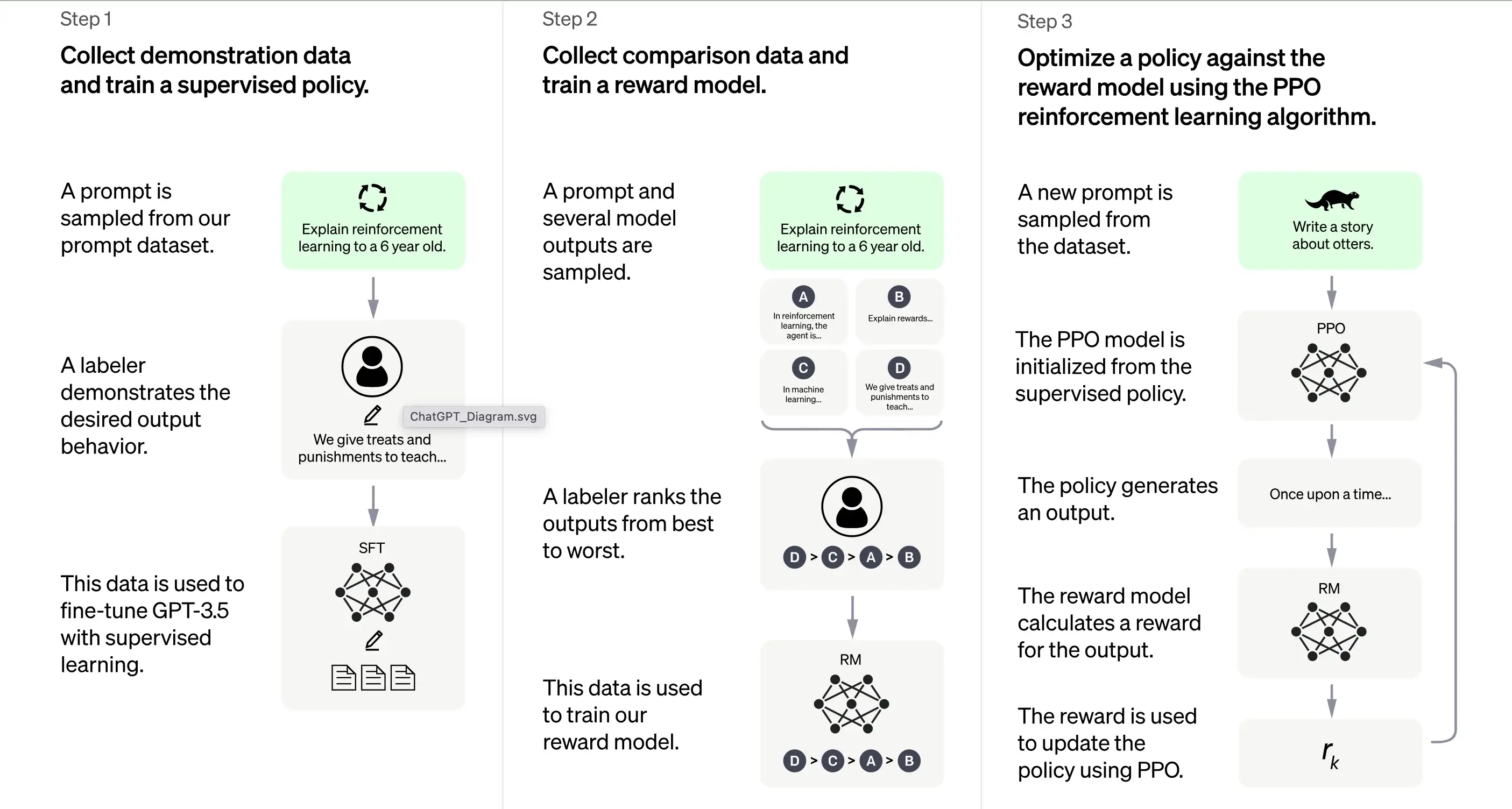
1. Erstausbildung: Überwachtes Feintuning (SFT)
Der erste Schritt bei der Schulung von ChatGPT ist das überwachte Feintuning (SFT). Diese Phase umfasst die Verwendung eines kleinen, sorgfältig kuratierten Datensatzes, der aus Aufforderungen und ihren entsprechenden Antworten besteht, die von menschlichen Kennzeichnern erstellt wurden. Die Ausbildung zielt darauf ab, qualitativ hochwertige korrekte Ausgaben an ChatGPT auszugeben. Laut OpenAI basiert das Trainingsmodell in dieser Phase auf dem GPT-3.5-Serienmodell.
Der erste Schritt bei der Schulung von ChatGPT ist das überwachte Feintuning (SFT), ein überwachtes Richtlinienmodell, das trainiert wird, indem Demonstrationsdaten von menschlichen Kennzeichnern gesammelt werden. ChatGPT verwendet zwei Quellen von Aufforderungen: direkte Kennzeichnung von Entwicklern oder OpenAIs API-Anforderungen. Der daraus resultierende kleine, hochwertige kuratierte Datensatz wird verwendet, um ein vortrainiertes Sprachmodell feinzutunen. Anstatt das ursprüngliche GPT-3-Modell feinzutunen, haben sich die ChatGPT-Entwickler für ein vortrainiertes GPT-3.5-Serienmodell entschieden, wahrscheinlich text-davinci-003. Diese Entscheidung wurde getroffen, um auf der Grundlage eines „Code-Modells“ und nicht eines reinen Textmodells einen Allzweck-Chatbot wie ChatGPT zu erstellen.
Allerdings kann das SFT-Modell immer noch nicht benutzerorientiert sein und unter Fehlausrichtung leiden. Um dieses Problem zu überwinden, bewerten die Entwickler nun unterschiedliche Ausgaben des SFT-Modells, um ein Belohnungsmodell zu erstellen.
2. Generieren des Belohnungsmodells
Der Schritt ist darauf ausgelegt, eine Zielfunktion, das Belohnungsmodell, zu generieren. Dieses Modell bewertet die Ausgaben des SFT-Modells mit einer Punktzahl, die proportional zu den Erwartungen der Klasse an diese Ausgaben ist. Je mehr Erwartungen erfüllt werden, desto höher ist die Punktzahl und umgekehrt.
Die Kennzeichner werden die Ausgabe des SFT-Modells manuell anhand bestimmter Präferenzen und gemeinsamer Kriterien bewerten, denen sie folgen müssen. Letztendlich hilft dieser Prozess dabei, ein automatisiertes System zu erstellen, das menschliche Präferenzen nachahmen kann.
Der Vorteil dieser Methode besteht darin, dass sie extrem effizient ist. Da die Kennzeichner nur die Ausgabe statt das Modell verwenden müssen, um Inhalte von Grund auf zu erstellen.
Der Ablauf ist grob wie folgt:
Wählen Sie eine Liste von Aufforderungen aus, und das SFT-Modell generiert mehrere Ausgaben (beliebige Ausgabe zwischen 4 und 9) für jede Aufforderung.
Der Kennzeichner ordnet die Ausgaben von der besten bis zur schlechtesten und erstellt so einen neuen markierten Datensatz, bei dem die „Ränge“ als Beschriftungen dienen. Dieser Datensatz ist etwa zehnmal größer als der kuratierte Datensatz, der vom SFT-Modell verwendet wird.
Dieser Datensatz trainiert dann das Belohnungsmodell (RM). Das Modell nimmt als Eingabe einige SFT-Modellausgaben und ordnet sie der bevorzugten Reihenfolge zu.
Bisher haben wir besprochen, wie das Modell zunächst mithilfe des überwachten Feintunings trainiert und dann mithilfe eines Belohnungsmodells verfeinert wird. Diese Schritte bilden die Grundbausteine für die Schulung von ChatGPT. Der Prozess geht jedoch darüber hinaus. Das System geht dann in eine Phase iterativer Verbesserung über eine Technik namens Proximale Policy Optimierung über.
3. Iterative Verbesserung: Proximale Policy-Optimierung (PPO)
Die letzte Trainingsphase beinhaltet die Anwendung der Proximalen Policy-Optimierung (PPO). Diese Technik verwendet das Belohnungsmodell als Wertfunktion, um den erwarteten Ertrag einer Aktion zu schätzen. Anschließend wendet sie eine „Vorteilsfunktion“ an, die die Differenz zwischen dem erwarteten und dem tatsächlichen Ertrag darstellt, um die Richtlinie zu aktualisieren.
PPO ist ein „On-Policy“-Algorithmus, der aus der aktuellen Richtlinie auf der Grundlage der Aktionen des Agenten und der erhaltenen Belohnungen lernt und sie aktualisiert. Dieses Design hilft, stabiles Lernen zu gewährleisten, indem es den Umfang der Richtlinienänderung bei jeder Aktualisierung einschränkt und so verhindert, dass das Modell drastische Änderungen vornimmt, die den Lernprozess stören könnten.
Das PPO-Modell beginnt mit dem SFT-Modell und initialisiert die Wertfunktion aus dem Belohnungsmodell. In dieser Umgebung wird eine zufällige Aufforderung präsentiert und eine Reaktion erwartet. Sobald die Antwort gegeben wurde, endet die Episode mit der Belohnung, die durch das Belohnungsmodell bestimmt wird.
Kontinuierliches Lernen: Der iterative Zyklus
Mit Ausnahme des ersten Schritts, der nur einmal erfolgt, werden die Belohnungsmodellgenerierung und PPO-Phasen in Zyklen wiederholt. Dieser iterative Ansatz ermöglicht eine kontinuierliche Verbesserung des Modells im Laufe der Zeit. In jedem Zyklus sammelt das Modell mehr Vergleichsdaten, trainiert ein neues Belohnungsmodell und etabliert eine neue Richtlinie. Infolgedessen verbessert sich das Modell mit der Zeit bei der Anpassung an menschliche Präferenzen.
4. Die Transformer-Architektur: Ein Fundament für ChatGPT
4.1 Ein Überblick
Die Grundlage von ChatGPT ist eine Art neuronalem Netzwerk namens Transformer-Architektur. Ein neuronales Netzwerk ahmt im Grunde die Funktionsweise des menschlichen Gehirns nach, indem es Informationen durch mehrere Schichten miteinander verbundener Knoten verarbeitet. Stellen Sie sich ein Symphonieorchester vor: Jeder Musiker hat eine Rolle und gibt Melodien (Informationen) hin und her, die alle zusammenwirken, um Musik (eine Ausgabe) zu erzeugen.
Die Transformer-Architektur ist spezialisiert auf die Verarbeitung von Wortfolgen, indem sie einen Mechanismus nutzt, der als „Self-Attention“ bekannt ist. Der Self-Attention-Mechanismus ähnelt der Art und Weise, wie ein Leser einen früheren Satz oder Absatz erneut aufrufen könnte, um den Kontext eines neuen Wortes oder einer neuen Phrase zu verstehen. Der Transformer bewertet alle Wörter in einer Sequenz, um den Kontext und die Beziehungen zwischen ihnen zu erkennen.
4.2 Schichten des Transformers
Die Transformer-Architektur besteht aus mehreren Schichten, von denen jede aus zwei Haupt-Unterschichten besteht: der Self-Attention-Schicht und der Feedforward-Schicht. Die Self-Attention-Schicht berechnet die Relevanz jedes Wortes in einer Sequenz, während die Feedforward-Schicht nichtlineare Transformationen auf die Eingabedaten anwendet. Durch diese Konfiguration lernt der Transformer, die Beziehungen zwischen den Wörtern in einer Sequenz zu verstehen und zu navigieren.
4.3 Training des Transformers
Während der Ausbildung wird dem Transformer Eingabedaten (ein Satz z.B.) bereitgestellt und er wird aufgefordert, basierend auf dieser Eingabe ein Ergebnis vorherzusagen. Das Modell wird dann entsprechend aktualisiert, wie genau seine Vorhersage mit der Ausgabe übereinstimmt. Auf diese Weise schärft der Transformer seine Fähigkeit, den Kontext und die Beziehungen zwischen Wörtern in einer Sequenz zu verstehen.
Es ist wie ein Kind neue Wörter zu lehren: Sie präsentieren ihnen neue Wörter (Eingabe), sie machen eine Vermutung über die Bedeutung (Vorhersage) und Sie korrigieren sie, wenn sie falsch liegen (Modell aktualisieren), wodurch ihr Spracherwerbsprozess unter
4.4 Herausforderungen bei der Verwendung
Wie jedes leistungsstarke Werkzeug bringt die Transformer-Architektur jedoch auch Herausforderungen mit sich. Das Potenzial dieser Modelle, schädliche oder voreingenommene Inhalte zu generieren, ist eine bedeutende Besorgnis, da sie unbeabsichtigt Verzerrungen aus den Trainingsdaten lernen und weitergeben können. Stellen Sie sich einen Papagei vor, der nachplappert, was auch immer er hört, unabhängig von der Angemessenheit oder politischen Korrektheit der Wörter.
Die Entwickler dieser Modelle bemühen sich, „Schutzmaßnahmen“ einzubauen, um diese Risiken abzumildern. Dennoch können diese Schutzmaßnahmen aufgrund unterschiedlicher Perspektiven und Interpretationen von Verzerrungen zu neuen Problemen führen.
Wie wir alle wissen, profitiert ChatGPTs Leistungserzeugung von den umfangreichen Datenquellen seines GPT-Modells, sodass wir als Nächstes die Daten diskutieren werden, die ChatGPT unterstützen.
5. Die Rolle vielfältiger Datensätze
5.1 ChatGPT: Ein Produkt umfangreichen Vortrainings
ChatGPT, das auf der GPT-3-Architektur (Generative Pre-trained Transformer 3) aufbaut, ist ein leistungsstarkes Sprachmodell, das durch den monumentalen Datensatz WebText2 angetrieben wird. Um das Ausmaß zu verstehen, stellen Sie sich eine Bibliothek vor, die mit über 45 Terabyte Textdaten gefüllt ist, was dem Tausendfachen des Inhalts der Wikipedia entspricht.
Der kolossale Umfang von WebText2 ermöglicht es ChatGPT, in einem unvorstellbaren Maßstab Muster und Assoziationen zwischen Wörtern und Phrasen zu erlernen und so kohärente und kontextbezogene Antworten zu generieren.
5.2 Feintuning von ChatGPT für Gespräche
Obwohl ChatGPT sein Rückgrat vom GPT-3-Architektur erbt, wurde es für bestimmte Konversationsanwendungen feinabgestimmt und optimiert. Dies führt zu einer ansprechenderen und persönlicheren Interaktionserfahrung für Benutzer, die mit ChatGPT interagieren.
OpenAI, die Schöpfer von ChatGPT, hat einen einzigartigen Datensatz namens Persona-Chat zur Verfügung gestellt, der speziell für das Training konversationsbezogener KI-Modelle entwickelt wurde. Dieser Datensatz besteht aus über 160.000 Dialogen zwischen menschlichen Teilnehmern; jedem wurde eine unverwechselbare Persona zugewiesen, die ihre Interessen, Persönlichkeit und ihren Hintergrund umreißt. Es ist, als ob ChatGPT ein Teilnehmer in Tausenden von Rollenspiel-Szenarien gewesen wäre und gelernt hätte, seine Antworten auf den Kontext und die Person des Gesprächs abzustimmen.
5.3 Eine Vielzahl von Datensätzen: Die geheime Zutat
Neben Persona-Chat wird ChatGPT mit mehreren anderen Konversationsdatensätzen feinabgestimmt:
Cornell Movie Dialogs Corpus: Dieser Datensatz beherbergt Dialoge zwischen Charakteren in Filmscripts mit über 200.000 konversationellen Austauschen zwischen mehr als 10.000 Charakterpaaren. Man kann sich vorstellen, dass ChatGPT die Drehbücher von Hunderten von Filmen studiert und die sprachlichen Feinheiten unterschiedlicher Genres und Kontexte aufnimmt.
Ubuntu Dialogue Corpus: Eine Zusammenstellung von Dialogen mit mehreren Wendungen zwischen Benutzern, die technische Unterstützung suchen, und dem Support-Team der Ubuntu-Community. Diese Daten können Tech-Support-Gespräche simulieren, um ChatGPT dabei zu helfen, bestimmte Terminologie und Problemlösungsmethoden zu erlernen. Und dieses Gespräch eine Million Mal.
Es ist, als hätte ChatGPT an über einer Million technischen Support-Gesprächen teilgenommen und die spezifische Terminologie und die Problemlösungsansätze gelernt.
DailyDialog: Dieser Datensatz umfasst menschliche Dialoge zu verschiedenen Themen, von Alltagsgesprächen bis hin zu Diskussionen über soziale Themen. Mit dieser Datenbank ist ChatGPT wie der Eintritt in zahllose Diskussionen, um den Ton, die Stimmung und die Themen zu verstehen, die eine alltägliche menschliche Konversation ausmachen.
Darüber hinaus nutzt ChatGPT eine enorme Menge an unstrukturierten Daten, die im Internet zu finden sind, einschließlich Bücher, Websites und andere Textquellen. Dies erweitert sein Verständnis von Sprachstruktur und -mustern, die für bestimmte Anwendungen wie Stimmungsanalyse oder Dialogverwaltung feinabgestimmt werden können.
5.4 Der Umfang von ChatGPT
Obwohl der Ansatz der GPT-Serie ähnelt, handelt es sich bei ChatGPT um ein eigenständiges Modell mit Unterschieden in der Architektur und den Trainingsdaten. ChatGPT umfasst 1,5 Milliarden Parameter, ist zwar kleiner als die atemberaubenden 175 Milliarden Parameter von GPT-3, aber dennoch beeindruckend.
Zusammenfassend lässt sich sagen, dass es sich bei den Trainingsdaten zur Feinabstimmung von ChatGPT überwiegend um Konversationsdaten handelt, die kuratiert sind, um Dialoge zwischen Menschen einzubeziehen, sodass ChatGPT natürliche, ansprechende Antworten generieren kann. Stellen Sie sich das unbeaufsichtigte Training so vor, als würde man einem Kind das Kommunizieren beibringen, indem man es unzähligen Gesprächen aussetzt und es Muster finden und alles verstehen lässt.
Nach dem Vortraining muss ChatGPT auch in der Lage sein, Fragen zu verstehen und aus den Daten Antworten zu konstruieren. Dies umfasst die Inferenzphase, unterstützt durch Verarbeitung natürlicher Sprache und Dialogmanagement; Lass es uns herausfinden.
6. Natural Language Processing:
Natural Language Processing (NLP) ist ein Teilgebiet der künstlichen Intelligenz, das sich darauf konzentriert, Computern zu ermöglichen, menschliche Sprache zu verstehen, zu interpretieren und zu generieren. Es ist eine kritische Technologie im heutigen digitalen Zeitalter, da sie viele Anwendungen wie Stimmungsanalyse, Chatbots, Spracherkennung und Sprachübersetzung zugrunde liegt.
NLP-Technologien können Unternehmen erheblich nützen, indem sie Aufgaben automatisieren, den Kundenservice verbessern und wertvolle Erkenntnisse aus Datenquellen wie Kundenfeedback und Social-Media-Beiträgen extrahieren.
Menschliche Sprache ist jedoch von Natur aus komplex und mehrdeutig, was Schwierigkeiten bei der Computerinterpretation mit sich bringt. Um dies zu bewältigen, werden NLP-Algorithmen mit riesigen Datenmengen trainiert, damit sie sprachliche Muster und Feinheiten erkennen können. Diese Algorithmen müssen auch ständig verfeinert und aktualisiert werden, um mit der sich ständig weiterentwickelnden Verwendung von Sprache und ihrem Kontext Schritt zu halten.
NLP zerlegt Spracheingaben (z. B. Sätze oder Absätze) in kleinere Komponenten und analysiert deren Bedeutungen und Beziehungen, um Erkenntnisse zu gewinnen oder Antworten zu generieren. Es verwendet verschiedene Techniken wie statistische Modellierung, maschinelles Lernen und Deep Learning, um Muster aus großen Datenmengen zu erkennen und daraus zu lernen, damit es Sprache genau interpretieren und generieren kann.
ChatGPT ist ein praktisches Beispiel für NLP in Aktion. Es wurde entwickelt, um sich in mehreren Gesprächsrunden auf eine Weise mit Benutzern zu engagieren, die natürlich und ansprechend wirkt. Dies beinhaltet den Einsatz von Algorithmen und Machine-Learning-Techniken, um den Kontext eines Gesprächs zu verstehen und über mehrere Austausche mit dem Benutzer aufrechtzuerhalten.
Diese Fähigkeit, einen Kontext über ein längeres Gespräch hinweg aufrechtzuerhalten, wird als Dialogverwaltung bezeichnet. Sie ermöglicht Computerprogrammen, mit Menschen auf eine Weise zu interagieren, die sich eher wie ein Gespräch anfühlt als eine Reihe von einmaligen Interaktionen. Dieser Aspekt von NLP ist von entscheidender Bedeutung, da er Vertrauen und Engagement bei den Nutzern aufbaut, was zu besseren Ergebnissen für den Nutzer und die Organisation führt, die das Programm verwendet.
7. Leistungsbewertung von ChatGPT
Drei Kernkriterien
Die Bewertung von ChatGPT ist ein entscheidender Schritt, um dessen Wirksamkeit und Zuverlässigkeit sicherzustellen. Da das Modell auf der Grundlage menschlicher Interaktionen trainiert wird, basiert auch seine Bewertung überwiegend auf menschlichen Eingaben, wobei Qualitätsbewerter die Modellausgaben bewerten.
Um zu verhindern, dass sich das Modell an das Urteil der Bewerter anpasst, die an der Schulungsphase teilgenommen haben, verwendet die Bewertung einen Testdatensatz, der Aufforderungen von OpenAIs Benutzerbasis enthält, die nicht in die Trainingsdaten aufgenommen wurden. Dies ermöglicht eine unvoreingenommene Bewertung der Modellleistung in realen Szenarien.
Die Bewertung des Modells erfolgt anhand von drei Kernkriterien:
Kriterien | Erläuterung |
|---|---|
Hilfsbereitschaft | Dies misst die Fähigkeit des Modells, Benutzeranweisungen zu befolgen und die Absichten des Benutzers zu verstehen. |
Wahrhaftigkeit | Damit wird die Neigung des Modells zu „Halluzinationen“ bewertet, was sich auf seine Tendenz bezieht, Fakten zu erfinden. Hierzu wird der TruthfulQA-Datensatz verwendet. |
Harmlosigkeit | Qualitätsbewerter bewerten, ob die Ausgabe des Modells angemessen ist, geschützte Klassen respektiert und abfällige Inhalte vermeidet. Dieser Aspekt der Auswertung nutzt die Datensätze RealToxicityPrompts und CrowS-Pairs. |
Zero-Shot-Leistung
ChatGPT wird auch für seine „Zero-Shot“-Leistung bewertet, d.h. seine Fähigkeit, Aufgaben ohne vorherige Beispiele bei traditionellen NLP-Aufgaben wie Fragebeantwortung, Leseverständnis und Zusammenfassung zu bewältigen. Interessanterweise stellten die Entwickler Leistungseinbußen im Vergleich zu GPT-3 bei einigen Aufgaben fest. Dieses Phänomen, bekannt als „Alignment Tax“, zeigt, dass das auf RLHF basierende Anpassungsverfahren die Leistung bei bestimmten Aufgaben reduzieren kann.
Ein Pre-Train-Mix-Verfahren kann diese Leistungseinbußen jedoch erheblich abmildern. Während des Trainings des PPO-Modells durch Gradientenabstieg werden die Gradientenupdates berechnet, indem die Gradienten des SFT-Modells und der PPO-Modelle kombiniert werden. Dieser Prozess hilft, die Leistung des Modells bei bestimmten Aufgaben zu verbessern.
8. Einschränkungen und Verbesserungen bei ChatGPT
ChatGPT weist trotz seiner bemerkenswerten Fähigkeiten Einschränkungen auf.
Falsche oder unsinnige Antworten.
ChatGPT kann mitunter plausible, aber falsche oder unsinnige Antworten produzieren. Dies liegt hauptsächlich daran, dass seine Daten nicht vollständig korrekt sind. Wie bereits erwähnt, wird ChatGPT während der Ausbildung verschiedene Datenquellen erhalten, darunter Bücher und das Internet. Also, welche Farben haben die Ampeln?
Wenn es in seiner Datenquelle falsche Antworten gibt, wie schwarz, weiß und gelb, dann kann ChatGPT auch falsche Antworten ausgeben.
Auch wenn das Modell darauf trainiert wird, vorsichtiger zu sein, kann es sich weigern, Fragen zu beantworten, die es korrekt beantworten könnte. Und während der überwachten Ausbildung beeinflusst das Wissen des Modells, aber nicht das des menschlichen Demonstrators, die gewünschte Antwort.
Empfindlich gegenüber Eingaben
Das Modell reagiert auch empfindlich auf Eingabeanpassungen. Das bedeutet, es kann eine sehr unterschiedliche Antwort liefern, sobald Sie den Befehl anpassen oder es bitten, die Frage erneut zu beantworten. So kann das Modell beispielsweise Abfragen korrekt beantworten, von denen es zuvor behauptet hat, sie nicht zu kennen. Oder es ändert die Antwort von der vorherigen (Ja zu Nein). Darüber hinaus verursachten auch die Datenverzerrung und die bekannte Überoptimierung des ChatGPT-Trainings einige Probleme. In ChatGPTs Ausgabe können Sie lange oder übermäßig verwendete Phrasen und Aussagen finden, wie z. B. die Bestätigung seiner Beziehung zu OpenAI.
Im Idealfall würde ChatGPT bei mehrdeutigen Abfragen nachfragen. Die aktuellen Modelle neigen jedoch dazu, die Absichten des Benutzers zu erraten. Obwohl versucht wurde, unangemessene Anforderungen abzulehnen, kann das Modell immer noch auf schädliche Anweisungen reagieren oder ein voreingenommenes Verhalten zeigen. Um dies zu bekämpfen, setzt OpenAI die Moderations-API ein, um bestimmte unsichere Inhalte zu warnen oder zu blockieren, aber es können immer noch falsch negative und positive Ergebnisse auftreten.
Trotz dieser Einschränkungen sind die Fortschritte von GPT-3 bis GPT-4 vielversprechend und zeigen die verbesserte Fähigkeit des Modells, plausible und akkurate Texte zu generieren. Wenn wir in die Zukunft blicken, ist zu erwarten, dass sich diese Verbesserungen fortsetzen und die Einschränkungen mit jeder neuen Iteration des GPT-Modells abnehmen werden.
Abschluss
Zusammenfassend lässt sich sagen, dass ChatGPT, ein Produkt der fortschrittlichen KI von GPT, durch eine Kombination aus Transformatorarchitektur, verstärkendem Lernen aus menschlichem Feedback und verschiedenen Datensätzen funktioniert. Es nutzt die Verarbeitung natürlicher Sprache, um menschenähnlichen Text zu verstehen und zu generieren und so ansprechende Interaktionen zu ermöglichen. Obwohl die Leistung des Systems beeindruckend ist, ist es wichtig zu beachten, dass sie nicht fehlerfrei ist und kontinuierliche Verbesserungsbewertungen erfordert. Trotz seiner Einschränkungen ist ChatGPT eine bemerkenswerte Innovation in der KI-Technologie, die die Grenzen der Maschine-Mensch-Interaktion verschiebt.