会話に革命をもたらしている AI について興味がありますか? ChatGPT がどのようにして質問を理解し、一貫した応答を作成することができるのか疑問に思ったことはありますか? GPT の基礎から自然言語処理の役割などに至るまで、この画期的なテクノロジーの複雑な仕組みを詳しく見てみましょう。 そのパフォーマンス、限界、将来の可能性を探ってください。 デジタル会話パートナーである ChatGPT の背後にある科学を解明します。
1. GPTとChatGPTについて
1.1 GPTモデルの定義
GPT(Generative Pre-trained Transformer)は、人工知能における重要な発展です。GPTモデルは、ChatGPTを含む様々な生成型AIアプリケーションで利用されています。トランスフォーマー・アーキテクチャをベースとしており、GPTモデルは人間らしいテキストや画像、音楽などのコンテンツを生成することができます。また、質問への回答、会話、あらゆるテキスト関連の処理などが可能です。
1.2 ChatGPTの紹介
ChatGPTはGPTモデルの派生型で、OpenAIによって開発されました。その動作はGPTの兄弟モデルであるInstructGPTと似ていますが、会話型のアプローチを取っています。この違いがChatGPTのインタラクティブな機能を可能にし、ユーザーとのコミュニケーション、質問への回答、エラー特定などができるのです。
1.3 ChatGPTと検索エンジンの比較
GoogleやWolfram Alphaなどの検索エンジンやコンピューテーショナル・エンジンも、ユーザーと1行のテキスト入力フィールドを介してインタラクションします。しかし、Googleの強みは膨大なデータベース検索を実行して一連の検索結果を提供することにある一方、Wolfram Alphaはデータ関連の質問を解析し、計算を実行するように設計されているのに対し、ChatGPTの強みはクエリを解析し、膨大な量のデジタルでアクセス可能なテキスト情報に基づいて包括的な回答を生成する能力にあります。
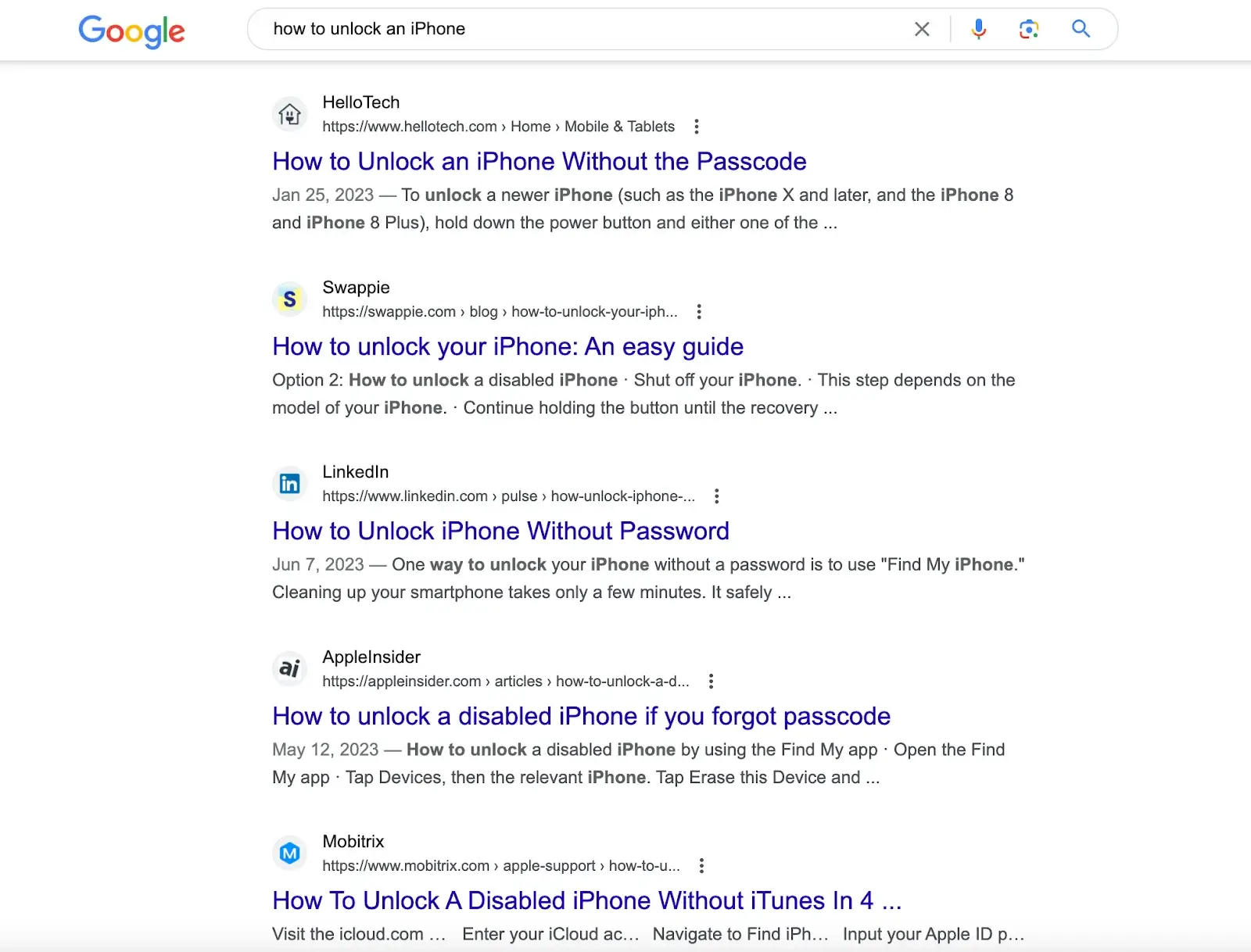
例えば、「iPhoneのロックを解除するには」と検索エンジンのGoogleで検索すると、さまざまなウェブサイトが作成した解決策の記事が表示されます。解決策を得るには、これらの記事を読み込む必要があります。
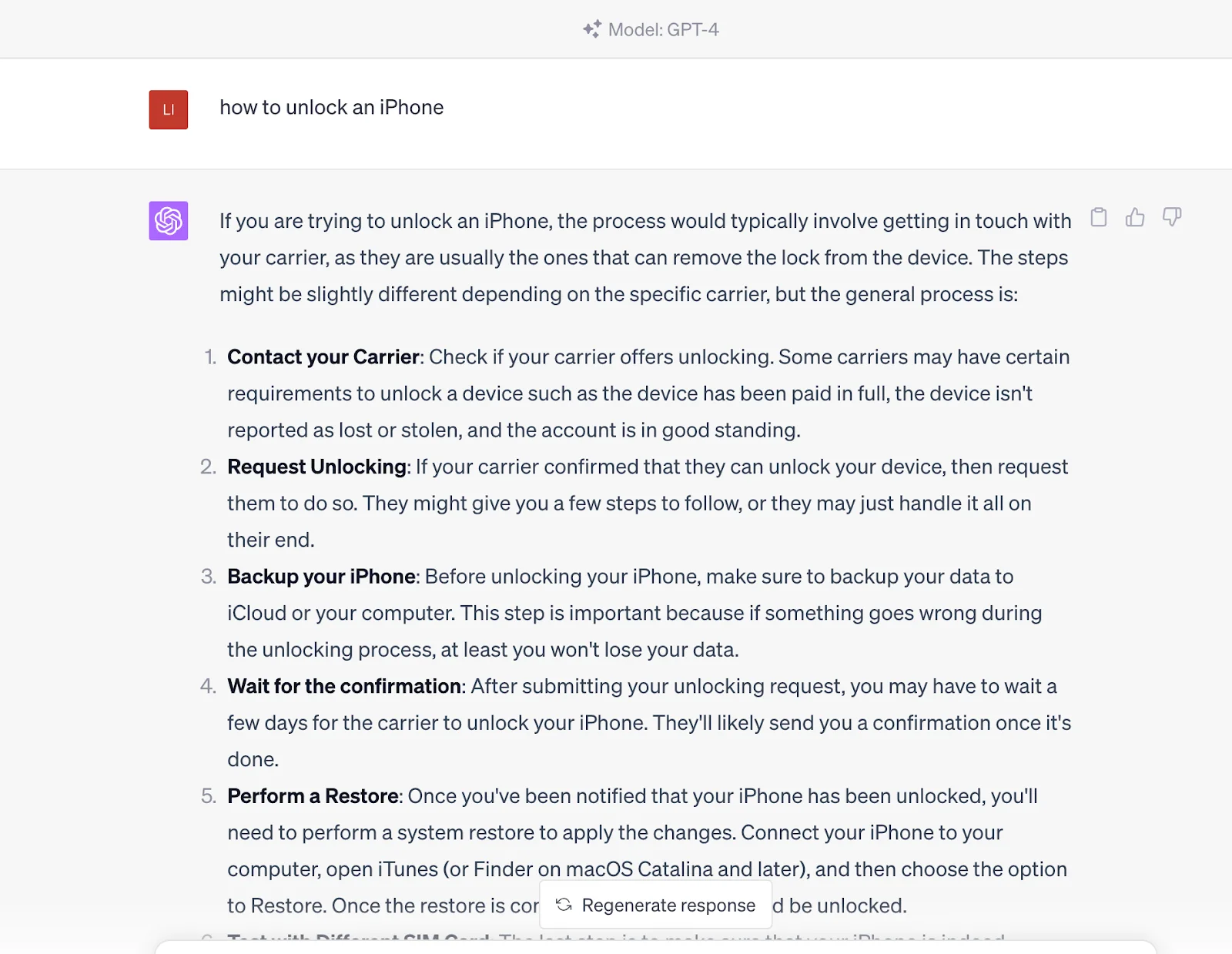
しかし、この質問をChatGPTに入力すると、直接回答がフィードバックされます。この回答は、検索エンジンが提供するリンクに含まれるコンテンツも含む、大規模なデータセットで訓練されたものです。
つまり、コンテンツソースへのリンクを単に検索エンジンから得るのではなく、知識のある実体とコミュニケーションができるのです。しかし、ChatGPTの情報は2021年時点のデータに基づいているため、現時点では検索エンジンに比べて時機を得た情報の面では劣っていることに注意が必要です。
2. ChatGPTの仕組み
ChatGPTの機能は、事前訓練(データ収集)と推論(ユーザープロンプトへの応答)の2つのフェーズに分けることができます。前述のとおり、ChatGPTはGoogleと似ています。広範囲の訓練の後、ChatGPTは質問を理解し、データベースから回答を生成することができるのです。唯一の違いは、プロンプトを送信したときにリンクではなく直接的な回答を生成することです。
ChatGPTは、人間らしいテキストを生成するためにディープラーニング・ニューラルネットワークを利用しています。人間の脳が予測を立て、以前の知識に基づいて結論を引き出すように、ChatGPTはテキストの単位であるトークンを表す膨大なデータ、つまりトレーニングデータセットで訓練されています。
従来のAIモデルが、各入力を特定の出力とペアで訓練する教師ありアプローチを用いるのに対し、ChatGPTは教師なし事前訓練アプローチを採用しています。ここでモデルは、特定のタスクを念頭に置くことなく、入力データの固有の構造とパターンを学習します。このことにより、言語の構文と意味論を理解し、意味のあるテキストを会話的に生成することが可能になります。この事前訓練こそが、ChatGPTの広範な知識と能力の背後にある変革的な力なのです。このモデルは、受信した入力を処理することにより、トランスフォーマー・ベースの言語モデリングに基づいて、幅広い応答を生成することができます。この方法論は、ChatGPTの限りない知識と会話能力の基盤を形成しています。
この訓練は、モデルを大量の人間作成コンテンツ-本、記事、インターネットコンテンツなど-に暴露することから始まります。このようにしてモデルは、これらのトークンからパターンと関係性を学習し、ディープラーニング・ニューラルネットワークを形成します。このネットワークは、人間の脳の働きを模倣する多層アルゴリズムのようなもので、モデルが文の系列内の単語間の関係性を理解し、ナビゲートできるようにします。
ChatGPTに顕著なのは、単に文の次の単語を予測するだけでなく、長いテキストを生成できる能力です。OpenAIは、ChatGPTが人間からのフィードバックによる強化学習(RLHF)を通じて、この点で訓練できることを明らかにしました。これにより、AIは全文、段落、さらに長いテキストストリングを生成して、意味のある対話型の応答を生成することができるのです。この訓練には、トレーナーがモデルによって生成されたさまざまな反応をランク付けして、良好な応答を構成するものをAIが理解できるようにする報酬モデルが含まれます。
ChatGPTの動作を支えるもう1つの強みは、その膨大なパラメータ数です。GPT-3は1,750億個、GPT-4の具体的な数は明らかにされていませんが、恐らくそれ以上の規模と考えられます。ユーザーが送信するすべてのプロンプトは、これらのパラメータによって処理される必要があり、その値と重みが出力に影響します。さらに、これらのパラメータにはランダム性が取り入れられているため、機械的で反復的な応答を避け、常に新鮮なものに保つことができます。たとえば、同じプロンプトを使っても、生成結果は異なる可能性があります。
3. 人間からのフィードバックによる強化学習(RLHF)
OpenAIによると、ChatGPTの訓練は主に人間からのフィードバックによる強化学習(RLHF)方法に基づいています。この方法には、望ましい応答を生成できるモデルを作成するための一連の特有のステップが含まれています。
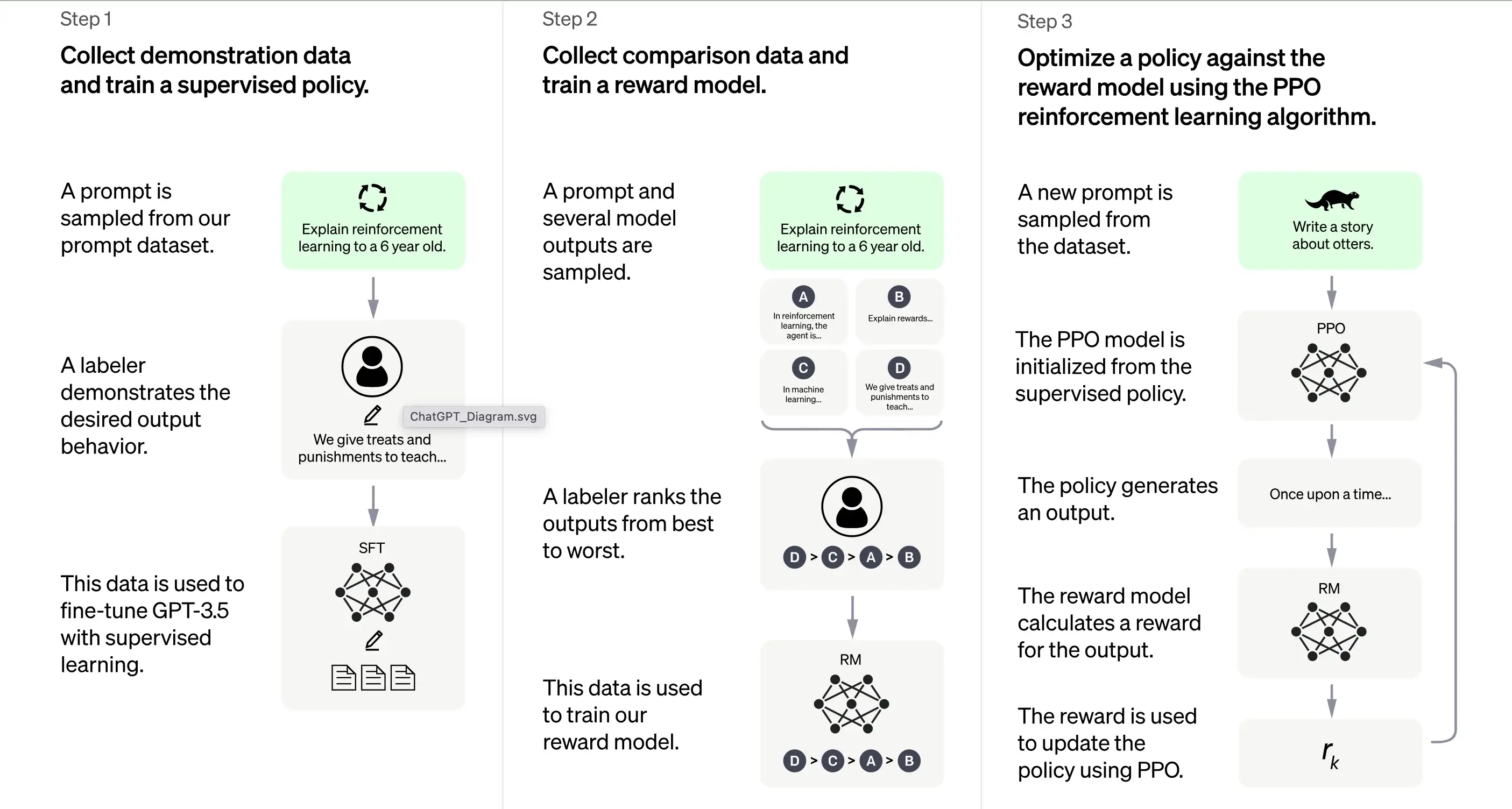
1. 初期訓練: 教師あり微調整(SFT)
ChatGPTの訓練の最初のステップは、教師あり微調整(SFT)です。このフェーズでは、人間のラベラーによって作成されたプロンプトとそれに対応する応答で構成される小さな、慎重に選別されたデータセットを使用します。この訓練は、ChatGPTに高品質の正しい出力を出力させることを目的としています。OpenAIによると、この段階の訓練モデルはGPT-3.5シリーズモデルに基づいています。
ChatGPTの訓練の最初のステップは、教師あり微調整(SFT)、つまり人間のラベラーからデモデータを収集する教師ありポリシーモデルです。ChatGPTは2つのソースのプロンプトを使用しています。1つは開発者による直接的なラベリング、もう1つはOpenAIのAPIリクエストです。その結果得られた小規模で高品質なデータセットは、事前訓練された言語モデルの微調整に使用されます。オリジナルのGPT-3モデルの微調整ではなく、ChatGPT開発者はtext-davinci-003などの事前訓練済みGPT-3.5シリーズモデルを選択しました。この決定は、純粋なテキストモデルではなく「コードモデル」上に、ChatGPTのような汎用チャットボットを作成するために行われました。
しかし、SFTモデルはまだユーザー志向でなく、不一致の問題がある可能性があります。この問題を克服するために、開発者は現在さまざまなSFTモデル出力をランク付けして報酬モデルを作成しています。
2. 報酬モデルの生成
このステップは、目的関数である報酬モデルを生成することを目的としています。このモデルはSFTモデルの出力をスコアリングします。スコアは、期待される出力に比例しています。期待値がより満たされるほど、スコアは高くなり、その逆も同様です。
ラベラーは、合意した特定の優先事項と一般的な基準に従って、SFTモデルの出力を手動でスコアリングします。最終的に、このプロセスは人間の嗜好を模倣できる自動システムの作成に役立ちます。
この方法の利点は、非常に効率的であることです。ラベラーはモデルを使ってコンテンツをゼロから生成するのではなく、出力をランク付けするだけでよいからです。
そのワークフローは概略以下のとおりです。
プロンプトのリストを選択し、SFTモデルは各プロンプトについて複数の出力(4~9の出力)を生成します。
ラベラーは出力をベストからワーストまでランク付けし、「ランク」をラベルとする新しいラベル付きデータセットを作成します。このデータセットは、SFTモデルで使用された選別データセットの約10倍の大きさです。
このデータセットは、その後報酬モデル(RM)の訓練に使用されます。このモデルは、SFTモデルの出力を入力として受け取り、優先順位付けしてランク付けます。
ここまでで、モデルが最初に教師あり微調整を使用して訓練され、次に報酬モデルで改善される方法について説明しました。これらのステップは、ChatGPTの訓練の基本的な構成要素を形成しています。しかし、このプロセスはそれ以降も継続します。システムは次に、近接ポリシー最適化と呼ばれる技法を用いた反復的改善の段階に入ります。
3. 反復的改善: 近接ポリシー最適化(PPO)
トレーニングの最終段階には、近接ポリシー最適化 (PPO) の適用が含まれます。 この手法では、報酬モデルを価値関数として使用して、アクションの期待収益を推定します。 次に、期待される収益と実際の収益の差を表す「アドバンテージ関数」を適用して、ポリシーを更新します。
PPO は、エージェントのアクションと受け取った報酬に基づいて現在のポリシーを学習し、更新する「ポリシーに基づく」アルゴリズムです。 この設計は、更新ごとにポリシーの変更の範囲を制限し、学習プロセスを中断する可能性のある大幅な変更をモデルが行うのを防ぐことで、安定した学習を確保するのに役立ちます。
PPO モデルは SFT モデルから始まり、報酬モデルから価値関数を初期化します。 この環境では、ランダムなプロンプトが表示され、応答が期待されます。 応答が与えられると、エピソードは報酬モデルによって決定される報酬で終了します。
継続的学習: 反復サイクル
最初のステップを一度だけ行うことを除き、報酬モデルの生成とPPO段階は繰り返し行われます。この反復アプローチにより、モデルは時間とともに継続的に改善されます。各サイクルで、モデルは比較データをより多く収集し、新しい報酬モデルを訓練して、新しいポリシーを確立します。その結果、モデルは人間の嗜好への整合性が時間とともに向上します。
4. トランスフォーマー・アーキテクチャ:ChatGPTの基盤
4.1 概要
ChatGPTの根幹を成すのは、トランスフォーマー・アーキテクチャと呼ばれるニューラルネットワークです。ニューラルネットワークは、本質的には人間の脳の働きを模倣するもので、情報を相互接続されたノードの層を通して処理します。オーケストラのメンバーのようなものと思ってください。音楽家はそれぞれ役割があり、メロディー(情報)を互いにやりとりし、調和して音楽(出力)を生み出します。
トランスフォーマー・アーキテクチャは、「自己注意メカニズム」と呼ばれるメカニズムを活用することで、単語の系列を処理するのに特化しています。自己注意メカニズムは、読者が新しい単語やフレーズの文脈を理解するために以前の文や段落を再度読むのと似ています。トランスフォーマーは、文脈と単語間の関係性を見極めるために、系列内のすべての単語を評価します。
4.2 トランスフォーマーのレイヤー
トランスフォーマー・アーキテクチャは、自己注意層とフィードフォワード層の2つの主要なサブレイヤーで構成される複数のレイヤーからなります。自己注意層は、系列内の各単語の関連性を計算し、フィードフォワード層は入力データに非線形変換を適用します。この構成を通じて、トランスフォーマーは系列内の単語間の関係性の理解とナビゲートの方法を学習します。
4.3 トランスフォーマーの訓練
訓練時には、トランスフォーマーに入力データ(文など)が提供され、その入力に基づいて結果を予測するように求められます。次に、モデルの予測が出力とどの程度一致しているかに基づいて、モデルが更新されます。このようにして、トランスフォーマーは系列内の単語間の文脈と関係性を理解する能力を磨きます。
これは、子どもに新しい単語を教えるのに似ています。新しい単語(入力)を提示し、意味について推測させ(予測)、間違っていれば訂正します(モデルの更新)。このことにより、言語習得プロセスを助けるのです。
4.4 使用時の課題
しかし、あらゆる強力なツールと同様に、トランスフォーマー・アーキテクチャにも課題があります。これらのモデルが有害あるいは偏見に満ちたコンテンツを生成する可能性は大きな懸念事項です。訓練データに内在する偏見を無意識のうちに学習し、継承することがあるからです。聞いたままを真似するインコのようなものだと考えると良いでしょう。政治的正しさや適切さに関係なく、聞いた言葉をまねするのです。
これらのモデルの開発者は、こうしたリスクを軽減するための「ガードレール」を取り入れることを目指しています。しかし、こうしたガードレールは、偏見に関する多様な視点や解釈が存在するため、新たな問題を引き起こす可能性があります。
ご存知のとおり、ChatGPTの強力な生成能力は、そのGPTモデルの膨大なデータソースによるところが大きいです。次に、ChatGPTを支えるデータについて説明します。
5. 多様なデータセットの役割
5.1 ChatGPT: 広範な事前訓練の産物
GPT-3(Generative Pre-trained Transformer 3)アーキテクチャの上に築かれたChatGPTは、WebText2という莫大なデータセットに支えられた強力な言語モデルです。その規模を理解するために、ウィキペディアのコンテンツの何千倍にも相当する45テラバイトのテキストデータで満たされた図書館を想像してください。
WebText2の膨大な規模により、ChatGPTは言葉とフレーズのパターンと関連性を想像を絶する規模で学習でき、意味のある文脈に関連した応答を生成できるのです。
5.2 ChatGPTの会話用の微調整
ChatGPTはGPT-3アーキテクチャから骨格を継承していますが、特定の会話アプリケーションのために微調整および最適化された独自のモデルです。これにより、ChatGPTと対話するユーザーにとって、よりエンゲージメントの高い、パーソナライズされたインタラクション体験が実現します。
ChatGPTの作成者であるOpenAIは、会話型AIモデルの訓練専用に設計されたPersona-Chatというユニークなデータセットを利用可能にしました。このデータセットは、それぞれが独自の性格、関心、背景をoutlineしている人間同士の対話16万を超える対話で構成されています。このデータベースに参加したかのように、ChatGPTは会話の文脈と個性に応じて反応を調整する方法を学習したのです。
5.3 多様なデータセット: 秘密のソース
Persona-Chatに加え、ChatGPTは他の複数の会話データセットで微調整されています:
Cornell Movie Dialogs Corpus: このデータセットには、映画の脚本でのキャラクター間の対話が20万を超える会話の形で収められています。まるでChatGPTが数百本の映画の脚本を学習し、さまざまなジャンルと文脈での言語的ニュアンスを吸収したかのようです。
Ubuntu Dialogue Corpus: ユーザーによる技術サポートの要求とUbuntuコミュニティのサポートチームによる対話のコンパイル。このデータは、ChatGPTが特定の用語と問題解決方法を学習できるように、技術サポート会話をシミュレートできます。そして、この会話を100万回。
まるでChatGPTが技術サポートの会話に100万回以上参加し、特定の専門用語と問題解決アプローチを学んだかのようです。
DailyDialog: このデータセットは、日常生活の会話から社会問題に関する議論まで、さまざまなトピックの人間の対話を含んでいます。このデータベースを使用することで、ChatGPTは日常的な人間の会話のトーン、ムード、テーマを理解するために、数え切れないほどの議論に参加したのです。
加えて、ChatGPTはインターネット上の本、ウェブサイト、その他のテキストソースからの膨大な非構造化データを活用しています。これにより、言語構造とパターンの理解が広がり、感情分析や対話管理など、特定のアプリケーションの微調整に活用できるのです。
5.4 ChatGPTの規模
アプローチはGPTシリーズと同様ですが、ChatGPTは独自のモデルで、アーキテクチャや訓練データが異なります。ChatGPTは15億パラメータで構成されており、GPT-3の途方もない175億パラメータと比べると小規模ですが、それでも印象的です。
要約すると、ChatGPTを微調整する訓練データは、主に会話型で、人間同士の対話を含むように選別されており、ChatGPTが自然でエンゲージメントの高い反応を生成できるようにしています。子供にコミュニケーションを教えるために、様々な会話に晒すことでパターンを見つけ理解させるようなものだと考えられます。
広範な事前訓練の後、ChatGPTは質問を理解し、データから回答を構築する必要があります。これには、自然言語処理と対話管理が関わってきます。次にその詳細を見ていきましょう。
6. 自然言語処理
自然言語処理(NLP)は、コンピュータが人間の言語を理解、解釈、生成できるようにすることに焦点を当てた人工知能のサブフィールドです。今日のデジタル時代において、これは非常に重要なテクノロジーであり、感情分析、チャットボット、音声認識、言語翻訳など、多くのアプリケーションの基盤となっています。
NLPテクノロジーは、タスクを自動化し、顧客サービスを強化し、顧客のフィードバックやソーシャルメディアの投稿などのデータソースから価値ある洞察を抽出することによって、ビジネスに大きな利益をもたらす可能性があります。
しかし、人間の言語は本質的に複雑であいまいであるため、コンピュータによる解釈は困難を伴います。この課題に対処するために、NLPアルゴリズムは膨大なデータで訓練されており、パターンの認識と言語の微妙なニュアンスの学習が可能になっています。これらのアルゴリズムは、洞察を正確に解釈および生成するために、大量のデータを統計的モデリング、機械学習、ディープラーニングなどの手法を用いて処理し、パターンを学習する必要があります。
ChatGPTは、NLPが実際に機能する実例です。ChatGPTは、ユーザーとの多ターンの会話に自然にエンゲージできるように設計されています。これには、アルゴリズムと機械学習の手法を用いて、会話の文脈を理解し、ユーザーとの複数の交換を通してそれを維持することが含まれます。
この会話の文脈を長期に渡って維持できる機能は、対話管理と呼ばれます。これにより、コンピュータプログラムは一連の個別の対話ではなく、会話のように人間とインタラクションできるのです。自然言語処理のこの側面は重要であり、ユーザーとの信頼感とエンゲージメントを構築し、プログラムを使用している組織にとっての結果を向上させます。
7. ChatGPTの性能評価
3 つの主要基準
ChatGPT の評価は、その有効性と信頼性を確保するための重要なステップです。 モデルは人間の対話に基づいてトレーニングされるため、その評価も主に人間の入力に依存し、品質評価者がモデルの出力を評価します。
モデルがトレーニング段階に参加した評価者の判断に過剰適合するのを防ぐために、評価ではトレーニング データには含まれない OpenAI のユーザー ベースからのプロンプトで構成されるテスト セットが使用されます。 これにより、現実世界のシナリオにおけるモデルのパフォーマンスを公平に評価できるようになります。
モデルの評価は、次の 3 つの主要な基準に基づいて実行されます。
基準 | 説明 |
|---|---|
有用性 | これは、ユーザーの指示に準拠し、ユーザーの意図を直観するモデルの能力を測定します。 |
真実性 | これは、事実をでっち上げる傾向を指す「幻覚」に対するモデルの傾向を評価します。このために、TruthfulQA データセットが使用されます。 |
無害性 | 品質評価者は、モデルの出力が適切であるかどうかを評価し、保護されたクラスを尊重し、軽蔑的なコンテンツを回避します。評価のこの側面では、RealToxicityPrompts および CrowS-Pairs データセットが使用されます。 |
ゼロショット性能
ChatGPT は、「ゼロショット」パフォーマンス、つまり、質問応答、読解、要約などの従来の NLP タスクで前例のないタスクを処理する能力でも評価されています。 興味深いことに、開発者は一部のタスクで GPT-3 と比較してパフォーマンスが低下していることに気づきました。 「調整税」として知られるこの現象は、モデルの RLHF ベースの調整手順が特定のタスクのパフォーマンスを低下させる可能性があることを示しています。
ただし、事前トレーニング ミックス技術を使用すると、これらのパフォーマンスの低下を大幅に軽減できます。 勾配降下法による PPO モデルのトレーニング中に、SFT モデルの勾配と PPO モデルの勾配を組み合わせることによって勾配の更新が計算されます。 このプロセスは、特定のタスクにおけるモデルのパフォーマンスを向上させるのに役立ちます。
8. ChatGPTの限界と改善点
ChatGPTは、顕著な能力にも関わらず、あらゆるAIモデルと同様に限界があります。
不正確または非論理的な回答
時にChatGPTは、正確さに欠け非論理的な回答を生成することがあります。これは主に、そのデータが完全に正しくないためです。前に議論したように、ChatGPTは訓練中に本やインターネットなど、様々なデータソースを受け取ります。交通信号の色は何色でしょうか。
データソースに黒、白、黄といった誤った回答が含まれている場合、ChatGPTも誤った回答を出力する可能性があります。
また、モデルがより慎重になるよう訓練されたとき、正しく処理できる質問に回答を拒否する可能性もあります。そして、教師あり訓練中は、人間のデモンストレーターではなく、モデルの知識が望ましい応答に影響を与えます。
入力の細かい調整に敏感
モデルは入力の細かい調整にも敏感です。これは、コマンドを調整したり、質問に再度回答するよう求めたりするだけで、非常に異なる回答を生成する可能性があることを意味します。例えば、モデルは以前知らないと主張した質問に正しく回答する場合があります。または、前の回答を変更する場合があります(YesからNoへ)。さらに、ChatGPTの訓練でのデータバイアスと既知の過剰最適化も一部の問題を引き起こしました。ChatGPTの出力に、冗長な文やフレーズ、OpenAIとの関係を再確認する記述が見られることがあります。
理想的には、ChatGPTはあいまいなクエリについて明確化を求めるべきです。しかし、現在のモデルはユーザーの意図を推測する傾向があります。不適切な要求を拒否するための取り組みが行われていますが、モデルは今なお有害な指示に応じたり、偏見を示したりする可能性があります。OpenAIは、特定の危険なコンテンツに警告やブロックを行う調整APIを採用していますが、誤検知や誤検知が存在する可能性があります。
これらの制限はあるものの、GPT-3からGPT-4への進歩は有望であり、モデルがより妥当で正確なテキストを生成する能力が向上したことを示しています。前を向けば、GPTモデルの各新バージョンで、これらの改善が続くと期待され、制限は減少すると考えられます。
結論
結論として、ChatGPTはGPTの最先端AIによって実現した製品であり、トランスフォーマー・アーキテクチャ、人間からのフィードバックに基づく強化学習、多様なデータセットの組み合わせによって動作します。自然言語処理は人間らしいテキストの理解と生成に用いられています。これにより、参加型のインタラクションが可能になります。非常に印象的ではあるものの、このシステムのパフォーマンスは完璧ではなく、継続的な改善評価が必要不可欠です。限界はあるものの、ChatGPTはAI技術の革新的なイノベーションであり、機械と人間のインタラクションの新たな境地を切り拓いています。