Curioso dell'intelligenza artificiale che sta rivoluzionando le conversazioni? Ti sei mai chiesto come riesce ChatGPT a comprendere le tue domande e creare risposte coerenti? Immergiti nell'intricato funzionamento di questa tecnologia rivoluzionaria, dalla sua fondazione GPT al ruolo dell'elaborazione del linguaggio naturale e oltre. Esplora le sue prestazioni, i limiti e le possibilità future. Svela la scienza dietro il tuo interlocutore digitale, ChatGPT.
1. Su GPT e ChatGPT
1.1 Definizione dei modelli GPT
GPT, o Generative Pre-trained Transformers, è uno sviluppo significativo nell'intelligenza artificiale. Vengono utilizzati in numerose applicazioni di AI generativa, compreso ChatGPT. Costruiti sull'architettura transformer, i modelli GPT possono produrre testi e altri tipi di contenuti simili all'uomo, come immagini e musica. Inoltre, puoi usarlo per rispondere a domande, avere conversazioni con loro, gestire tutto ciò che è relativo al testo e altro ancora.
1.2 Introduzione a ChatGPT
ChatGPT è un derivato dei modelli GPT, sviluppato da OpenAI. Funziona in modo simile al suo modello fratello, InstructGPT, ma con un approccio conversazionale. L'unicità di questa differenza conferisce a ChatGPT una funzione interattiva, consentendogli di comunicare con gli utenti e di completare ulteriormente il question answering, l'identificazione degli errori, ecc.
1.3 Confronto tra ChatGPT e motori di ricerca
I motori di ricerca come Google e i motori computazionali come Wolfram Alpha interagiscono anche con gli utenti tramite un campo di immissione testo a riga singola. Tuttavia, mentre il punto di forza di Google risiede nell'eseguire enormi ricerche di database per fornire una serie di corrispondenze e Wolfram Alpha è attrezzato per analizzare domande relative ai dati ed eseguire calcoli, il punto di forza di ChatGPT è la capacità di analizzare le query e fornire risposte complete basate su una vasta quantità di informazioni testuali accessibili digitalmente.
Ad esempio, cercando "come sbloccare un iPhone" su motori di ricerca come Google, otterrai articoli con soluzioni create da diversi siti web. Devi scorrere questi articoli per ottenere la soluzione.
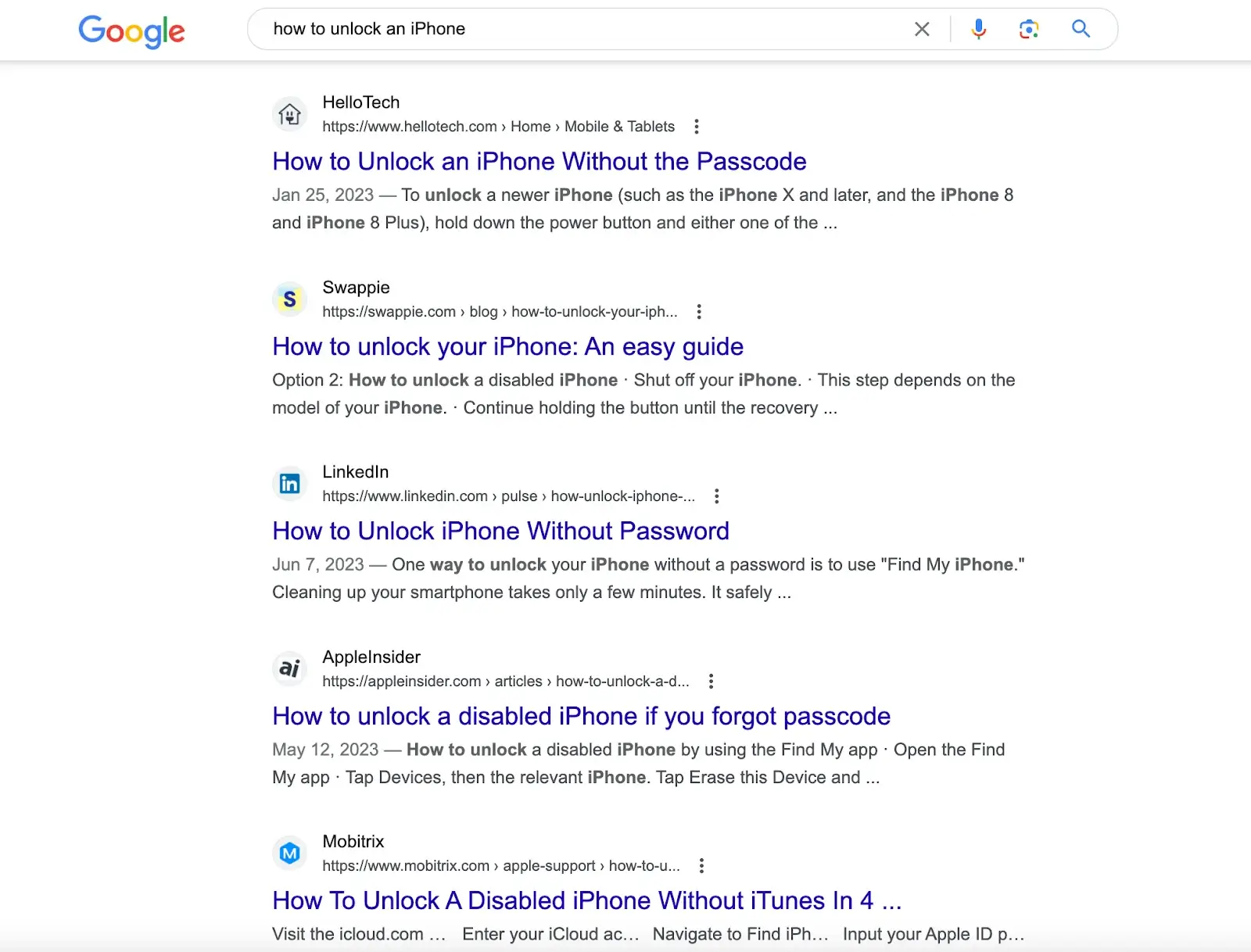
Ma se inserisci questa domanda in ChatGPT, ti darà direttamente la risposta. La risposta proviene dal suo set di dati pre-addestrato, che contiene anche il contenuto nei collegamenti forniti dai motori di ricerca.
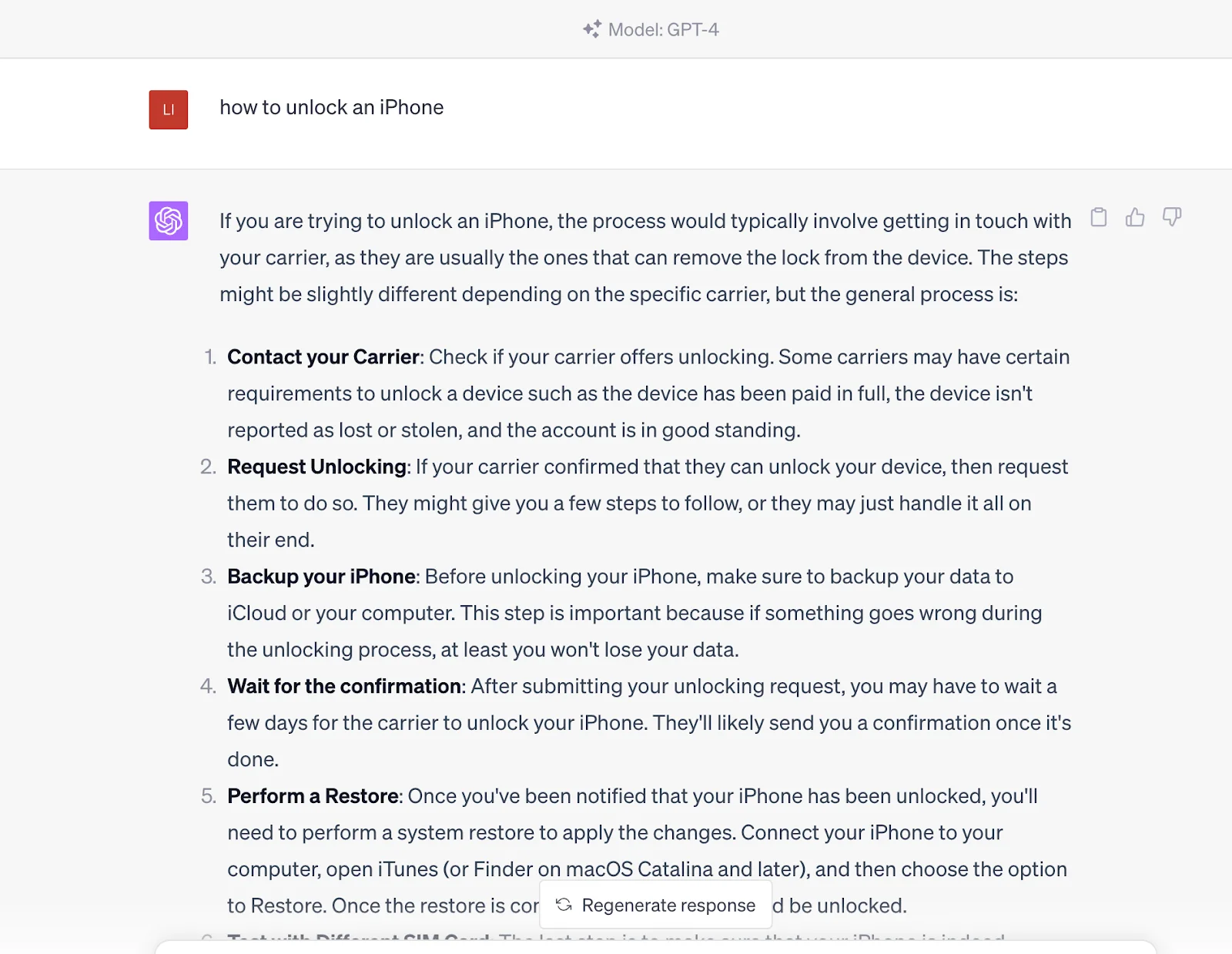
In altre parole, comunichi con un'entità competente che può generare risultati di query piuttosto che ottenere semplicemente quelle fonti di contenuto attraverso i motori di ricerca. Tuttavia, va notato che è attualmente inferiore ai motori di ricerca in termini di tempestività perché le informazioni di ChatGPT si basano sui dati addestrati a partire dal 2021.
2. Come funziona ChatGPT
Il funzionamento di ChatGPT è suddiviso in due fasi: pre-training o raccolta di dati e inferenza o risposta alle richieste dell'utente. Come abbiamo discusso prima, ChatGPT è simile a Google. Dopo un addestramento approfondito, ChatGPT può comprendere le domande e generare risposte dal suo database. L'unica differenza è che genererà risposte dirette, non link quando invii un prompt.
ChatGPT utilizza reti neurali di deep learning per generare testi simili all'uomo. Proprio come il cervello umano fa previsioni e trae conclusioni sulla base di conoscenze pregresse, ChatGPT viene addestrato su un'immensa quantità di dati, o token, sostanzialmente unità di testo che possono rappresentare singole parole o parti di parole complesse.
A differenza dei modelli AI tradizionali addestrati utilizzando un approccio supervisionato che abbina ogni input a un output specifico, ChatGPT utilizza un approccio di pre-training non supervisionato. Qui, il modello impara la struttura e i modelli intrinseci nei dati di input senza avere un compito particolare in mente, comprendendo quindi la sintassi e la semantica del linguaggio e consentendogli di generare testo significativo in modo discorsivo. Questo pre-training è il potere trasformativo alla base delle vaste conoscenze e capacità di ChatGPT. Il modello può sviluppare una vasta gamma di risposte in base all'input ricevuto elaborando colossali quantità di dati utilizzando il language modeling basato su transformer. Questa metodologia forma le fondamenta delle conoscenze e delle capacità conversazionali apparentemente illimitate di ChatGPT.
Questo training inizia esponendo il modello a una vasta quantità di contenuti scritti da esseri umani: da libri e articoli a contenuti Internet. Il modello impara così schemi e relazioni da questi token, formando una rete neurale deep-learning. Questa rete, simile a un algoritmo a più livelli che imita il funzionamento del cervello umano, consente al modello di generare testo contestualmente rilevante e simile all'uomo.
Ciò che è straordinario di ChatGPT è la sua capacità di generare lunghi testi invece di prevedere semplicemente la parola successiva in una frase. OpenAI ha rivelato la sua capacità di addestrare ChatGPT in questo senso attraverso l'apprendimento per rinforzo dal feedback umano (RLHF), consentendogli di generare intere frasi, paragrafi e persino stringhe di testo più lunghe per generare risposte coerenti. Questo training prevede un modello di ricompensa in cui l'allenatore classifica le diverse reazioni generate dal modello per aiutare l'IA a comprendere cosa costituisce una buona risposta.
Un'altra forza che supporta il funzionamento di ChatGPT è il suo enorme numero di parametri. GPT-3 è 175 miliardi e GPT-4 non ha rivelato il numero specifico, ma si può ipotizzare che potrebbe essere di più. Ogni prompt che l'utente invia deve essere elaborato da questi parametri e l'output sarà influenzato dal suo valore e peso. Inoltre, la casualità è stata incorporata in questi parametri per evitare risposte meccaniche e ripetitive e mantenere le cose fresche. Ad esempio, puoi utilizzare lo stesso prompt e generare risultati diversi.
Apprendimento per rinforzo dal feedback umano (RLHF)
Secondo OpenAI, l'allenamento di ChatGPT si basa in gran parte sul metodo Reinforcement Learning from Human Feedback (RLHF). Questo metodo prevede una serie di passaggi distinti per produrre un modello in grado di generare risposte desiderabili.
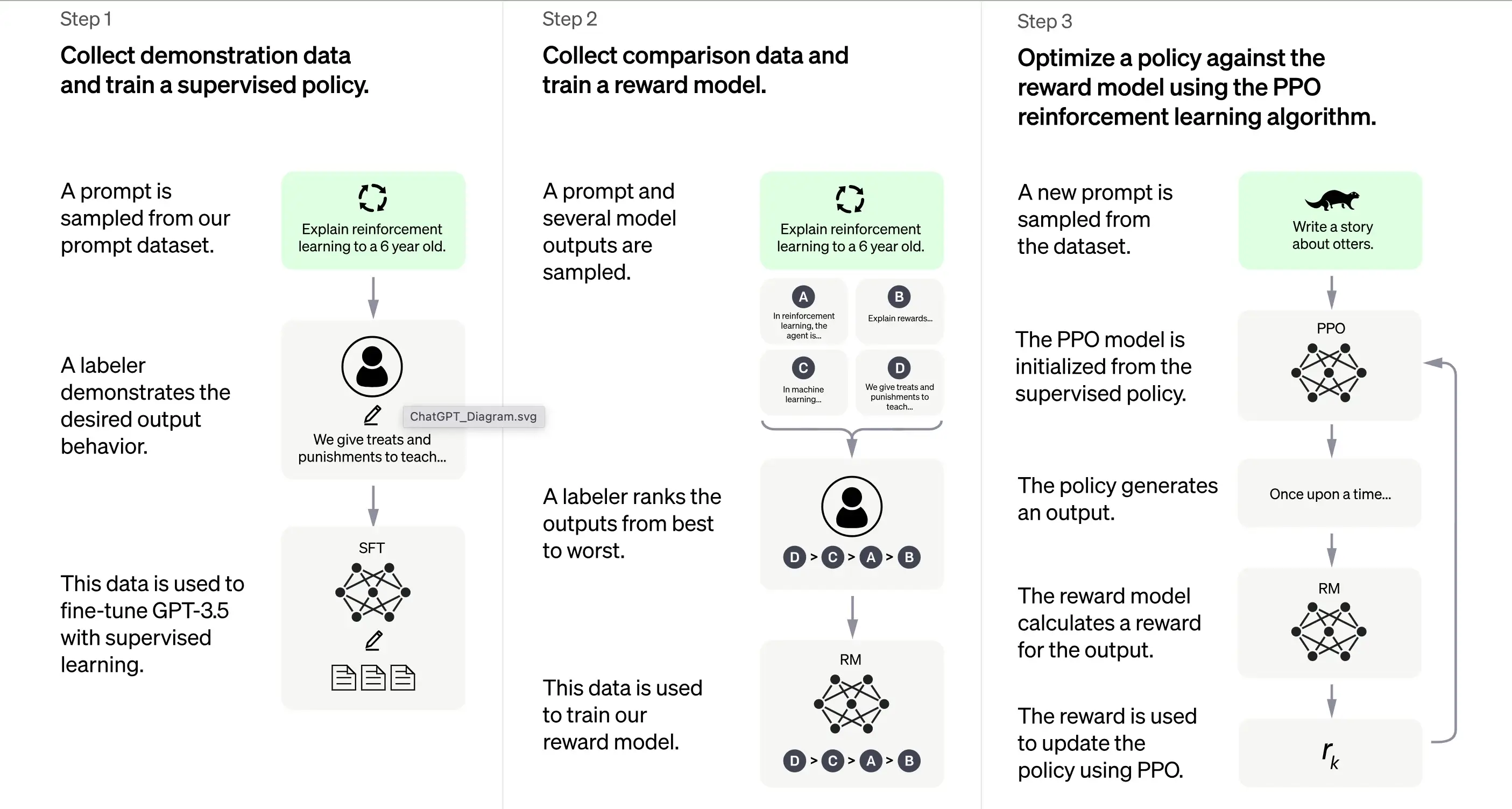
1. Addestramento iniziale: ottimizzazione supervisionata (SFT)
Il primo passo nell'addestramento di ChatGPT è la supervised fine-tuning (SFT). Questa fase prevede l'uso di un dataset piccolo e accuratamente curato composto da prompt e risposte corrispondenti prodotte da annotatori umani. L'addestramento mira a produrre un output corretto di alta qualità per ChatGPT. Secondo OpenAI, il modello di training in questa fase si basa sulla serie di modelli GPT-3.5.
l primo passo nell'addestramento di ChatGPT è la supervised fine-tuning (SFT), un modello di policy supervisionato addestrato raccogliendo dati dimostrativi da annotatori umani. ChatGPT utilizza due fonti di prompt: etichettatura diretta da parte degli sviluppatori o richieste API di OpenAI. Il risultante dataset piccolo e di alta qualità accuratamente curato viene utilizzato per ottimizzare un modello linguistico pre-addestrato. Invece di ottimizzare il modello GPT-3 originale, gli sviluppatori di ChatGPT hanno scelto un modello GPT-3.5 pre-addestrato, probabilmente text-davinci-003. Questa decisione è stata presa per creare un chatbot di uso generale come ChatGPT su un modello "code" piuttosto che un modello di solo testo.
Tuttavia, il modello SFT potrebbe ancora non essere attento all'utente e soffrire di disallineamento. Per superare questo problema, gli sviluppatori ora classificano diverse uscite del modello SFT per creare un modello di ricompensa.
Generazione del modello di ricompensa
Il passaggio è progettato per generare una funzione obiettivo, il modello di ricompensa. Questo modello assegna un punteggio alle uscite del modello SFT, con un punteggio proporzionale a quanto la classe si aspetta da quelle uscite. Maggiore è il rispetto delle aspettative, maggiore è il punteggio e viceversa.
Gli annotatori assegneranno manualmente un punteggio all'output del modello SFT in base a preferenze specifiche e criteri comuni che accettano di seguire. In definitiva, questo processo contribuisce a creare un sistema automatizzato in grado di imitare le preferenze umane.
Il suo flusso di lavoro è all'incirca il seguente:
Selezionare un elenco di prompt e il modello SFT genera output multipli (qualsiasi output tra 4 e 9) per ogni prompt.
L'annotatore classifica gli output da migliore a peggiore, creando un nuovo dataset etichettato con i "rank" come etichette. Questo dataset è circa dieci volte più grande del dataset curato utilizzato dal modello SFT.
Questo dataset addestrerà quindi il modello di ricompensa (RM). Il modello prende come input alcune uscite del modello SFT e le classifica in ordine di preferenza.
Finora, abbiamo discusso di come il modello viene inizialmente addestrato utilizzando la supervised fine-tuning e poi raffinato utilizzando un modello di ricompensa. Questi passaggi formano i blocchi di base per l'addestramento di ChatGPT. Tuttavia, il processo continua oltre. Il sistema entra quindi in una fase di miglioramento iterativo attraverso una tecnica chiamata ottimizzazione della policy prossimale.
3. Miglioramento iterativo: ottimizzazione prossimale della policy (PPO)
L'ultima fase di training prevede l'applicazione dell'ottimizzazione prossimale della policy (PPO). Questa tecnica utilizza il modello di ricompensa come funzione di valore per stimare il rendimento atteso di un'azione. Applica quindi una "funzione di vantaggio", che rappresenta la differenza tra i rendimenti previsti e quelli effettivi, per aggiornare i criteri.
PPO è un algoritmo "on-policy" che impara dall'attuale criterio e lo aggiorna in base alle azioni dell'agente e alle ricompense ricevute. Questa progettazione aiuta a garantire un apprendimento stabile limitando l'entità del cambiamento dei criteri durante ogni aggiornamento, impedendo al modello di apportare cambiamenti drastici che potrebbero interrompere il processo di apprendimento.
Il modello PPO inizia con il modello SFT e inizializza la funzione di valore dal modello di ricompensa. In questo ambiente, viene presentato un prompt casuale e ci si aspetta una risposta. Una volta fornita la risposta, l'episodio termina con la ricompensa, determinata dal modello di ricompensa.
Apprendimento continuo: il ciclo iterativo
Ad eccezione del fatto che il primo passo si verifica una sola volta, le fasi di generazione del modello di ricompensa e PPO vengono ripetute in cicli. Questo approccio iterativo consente il miglioramento continuo del modello nel tempo. Con ogni ciclo, il modello raccoglie più dati di confronto, addestra un nuovo modello di ricompensa e stabilisce una nuova politica. Di conseguenza, il modello migliora nel tempo allineandosi alle preferenze umane.
L'architettura Transformer: una base per ChatGPT
4.1 Panoramica
Il supporto di ChatGPT è un tipo di rete neurale chiamata architettura transformer. Una rete neurale, in sostanza, emula il funzionamento del cervello umano elaborando le informazioni attraverso più livelli di nodi interconnessi. Immagina un'orchestra sinfonica: ogni musicista ha un ruolo, passando melodie (informazioni) avanti e indietro, tutte armonizzando insieme per creare musica (un output).
L'architettura transformer si specializza nell'elaborazione di sequenze di parole sfruttando un meccanismo noto come "auto-attenzione". Il meccanismo di auto-attenzione è simile al modo in cui un lettore potrebbe rivisitare una frase o un paragrafo precedente per comprendere il contesto di una nuova parola o frase. Il trasformatore valuta tutte le parole in una sequenza per discernere il contesto e le relazioni tra loro.
4.2 Livelli del trasformatore
L'architettura transformer è composta da più livelli, ognuno composto da due sottolivelli principali: il livello di auto-attenzione e il livello feedforward. Lo strato di auto-attenzione calcola la rilevanza di ogni parola in una sequenza, mentre lo strato feedforward applica trasformazioni non lineari ai dati di input. Attraverso questa configurazione, il trasformatore impara a comprendere e navigare le relazioni tra le parole in una sequenza.
4.3 Addestramento del trasformatore
Durante l'addestramento, al trasformatore vengono forniti dati di input (una frase, ad esempio) e viene chiesto di prevedere un risultato sulla base di tale input. Il modello viene quindi aggiornato in base a quanto strettamente la sua previsione si allinea con l'output. In questo modo, il trasformatore affina la sua capacità di comprendere il contesto e le relazioni tra le parole in una sequenza.
È come insegnare a un bambino nuove parole: gli presenti nuove parole (input), fanno una supposizione sul significato (previsione) e li correggi se sbagliano (aggiornando il modello), aiutando così il loro processo di acquisizione del linguaggio.
4.4 Sfide nell'utilizzo
Tuttavia, come qualsiasi strumento potente, l'architettura transformer presenta le sue sfide. La potenzialità di questi modelli di generare contenuti dannosi o di pregiudizio è una preoccupazione significativa, poiché possono imparare e perpetuare inavvertitamente i pregiudizi presenti nei dati di training. Pensa a un pappagallo che mima tutto ciò che sente, indipendentemente dall'appropriatezza o dalla correttezza politica delle parole.
Gli sviluppatori di questi modelli si sforzano di incorporare "guard rail" per mitigare questi rischi. Tuttavia, queste guard rail potrebbero portare a nuovi problemi a causa di prospettive e interpretazioni diverse dei pregiudizi.
Come tutti sappiamo, la capacità generativa di ChatGPT beneficia delle vaste fonti di dati del suo modello GPT, quindi ora discuteremo i dati che forniscono supporto a ChatGPT.
5. Il ruolo di diversi set di dati
5.1 ChatGPT: un prodotto di un ampio pre-addestramento
ChatGPT, che poggia sulle spalle dell'architettura GPT-3 (Generative Pre-trained Transformer 3), è un robusto modello linguistico alimentato dal monumentale dataset WebText2. Per comprenderne la scala, immaginate una biblioteca piena di oltre 45 terabyte di dati di testo, equivalenti a migliaia di volte il contenuto di Wikipedia.
L'enorme scala di WebText2 consente a ChatGPT di apprendere modelli e associazioni tra parole e frasi su una scala impensabile, consentendogli di generare risposte coerenti e contestualmente rilevanti.
5.2 Ottimizzazione di ChatGPT per le conversazioni
Mentre ChatGPT eredita il suo nucleo dall'architettura GPT-3, è stato ottimizzato e ottimizzato per specifiche applicazioni conversazionali. Ciò si traduce in un'esperienza di interazione più coinvolgente e personalizzata per gli utenti che interagiscono con ChatGPT.
OpenAI, i creatori di ChatGPT, ha reso disponibile un set di dati unico chiamato Persona-Chat, progettato appositamente per l'addestramento di modelli AI conversazionali. Questo set di dati è composto da oltre 160.000 dialoghi tra partecipanti umani; a ciascuno è assegnata una distinta persona che delinea i loro interessi, la personalità e lo sfondo. È come se ChatGPT fosse un partecipante a migliaia di scenari di ruolo, imparando a modellare le sue risposte in base al contesto e alla persona della conversazione.
5.3 Una varietà di set di dati: il segreto
Oltre a Persona-Chat, ChatGPT viene ottimizzato utilizzando diversi altri set di dati conversazionali:
Cornell Movie Dialogs Corpus: questo set di dati ospita dialoghi tra personaggi in sceneggiature cinematografiche, con oltre 200.000 scambi conversazionali tra più di 10.000 coppie di personaggi. Pensate a ChatGPT che studia le sceneggiature di centinaia di film, assorbendo le sfumature linguistiche di diversi generi e contesti.
Ubuntu Dialogue Corpus: una raccolta di dialoghi multipasso tra utenti che cercano supporto tecnico e il team di supporto della comunità Ubuntu. Questi dati possono simulare conversazioni di supporto tecnico per aiutare ChatGPT ad apprendere terminologia specifica e metodi di risoluzione dei problemi. E questa conversazione un milione di volte.DailyDialog: This dataset comprises human dialogues on various topics, from daily life chats to discussions on social issues. Using this database, ChatGPT is like joining countless discussions to understand the tone, mood, and themes that make up everyday human conversation.
È come se ChatGPT avesse assistito a oltre un milione di conversazioni di supporto tecnico, imparando la terminologia specifica e gli approcci di risoluzione dei problemi.
DailyDialog: questo set di dati comprende dialoghi umani su vari argomenti, dalle chiacchiere quotidiane alle discussioni su questioni sociali. Utilizzando questo database, ChatGPT è come unirsi a innumerevoli discussioni per comprendere il tono, l'umore e i temi che compongono la normale conversazione umana.
Inoltre, ChatGPT sfrutta una vasta quantità di dati non strutturati trovati su Internet, tra cui libri, siti web e altre fonti di testo. Ciò amplia la sua comprensione della struttura e dei modelli del linguaggio, che possono essere ottimizzati per applicazioni specifiche come l'analisi del sentiment o la gestione del dialogo.
5.4 La scala di ChatGPT
Anche se simile nell'approccio alla serie GPT, ChatGPT è un modello distinto con differenze nell'architettura e nei dati di training. ChatGPT comprende 1,5 miliardi di parametri, di dimensioni inferiori rispetto agli strabilianti 175 miliardi di parametri di GPT-3, ma nondimeno impressionante.
In sintesi, i dati di training per ottimizzare ChatGPT sono prevalentemente conversazionali, curati per includere dialoghi tra esseri umani, consentendo a ChatGPT di generare risposte naturali e coinvolgenti. Pensa al suo training non supervisionato come insegnare a un bambino a comunicare esponendolo a una miriade di conversazioni e lasciandolo trovare modelli e dargli un senso.
Dopo il pre-addestramento, ChatGPT deve anche essere in grado di comprendere le domande e costruire risposte dai dati. Ciò comporta la fase di inferenza, supportata dall'elaborazione del linguaggio naturale e dalla gestione del dialogo; scopriamolo.
6. L'elaborazione del linguaggio naturale:
L'elaborazione del linguaggio naturale (NLP) è un sottocampo dell'intelligenza artificiale che si concentra sul consentire ai computer di comprendere, interpretare e generare il linguaggio umano. È una tecnologia critica nell'era digitale di oggi, poiché è alla base di molte applicazioni come l'analisi del sentimento, i chatbot, il riconoscimento vocale e la traduzione linguistica.
Le tecnologie NLP possono giovare significativamente alle aziende automatizzando attività, migliorando il servizio clienti ed estraendo informazioni preziose da fonti di dati come feedback dei clienti e post sui social media.
Tuttavia, il linguaggio umano è intrinsecamente complesso e ambiguo, presentando difficoltà di interpretazione da parte del computer. Per affrontare questo problema, gli algoritmi NLP vengono addestrati su enormi quantità di dati, consentendo loro di riconoscere modelli e imparare le sfumature del linguaggio. Questi algoritmi devono anche essere costantemente raffinati e aggiornati per tenere il passo con l'uso del linguaggio in continua evoluzione e il suo contesto.
L'NLP suddivide gli input linguistici (ad es. frasi o paragrafi) in componenti più piccole e ne analizza significati e relazioni per generare approfondimenti o risposte. Impiega varie tecniche, tra cui modellazione statistica, machine learning e deep learning, per discernere modelli e imparare da grandi quantità di dati, interpretando e generando così il linguaggio con precisione.
ChatGPT è un esempio pratico di NLP in azione. È progettato per impegnarsi in conversazioni multipasso con gli utenti che sembrano naturali e coinvolgenti. Ciò comporta l'utilizzo di algoritmi e tecniche di machine learning per comprendere il contesto di una conversazione e mantenerlo su più scambi con l'utente.
Questa capacità di mantenere un contesto su una conversazione prolungata è nota come gestione del dialogo. Consente ai programmi per computer di interagire con le persone in modo che assomigli più a una conversazione che a una serie di interazioni una tantum. Questo aspetto dell'NLP è vitale poiché costruisce fiducia e coinvolgimento con gli utenti, portando a migliori risultati sia per l'utente che per l'organizzazione che utilizza il programma.
7. Valutazione delle prestazioni di ChatGPT
Tre criteri principali
La valutazione di ChatGPT è un passaggio cruciale per garantirne l'efficacia e l'affidabilità. Poiché il modello è addestrato sulla base di interazioni umane, la sua valutazione si basa anche prevalentemente su input umani, in cui valutatori della qualità valutano l'output del modello.
Per evitare che il modello si adatti eccessivamente al giudizio dei valutatori che hanno partecipato alla fase di formazione, la valutazione impiega un set di test composto da prompt provenienti dalla base utenti di OpenAI che non sono inclusi nei dati di training. Ciò consente una valutazione imparziale delle prestazioni del modello in scenari del mondo reale.
La valutazione del modello viene condotta su tre criteri principali:
Criterio | Spiegazione |
Utilità | Misura la capacità del modello di rispettare le istruzioni dell'utente e intuire le intenzioni dell'utente. |
Veridicità | Valuta la propensione del modello alle "allucinazioni", che si riferisce alla sua tendenza a inventare fatti. Per questo, viene utilizzato il set di dati TruthfulQA. |
Innocuità | I valutatori della qualità valutano se l'output del modello è appropriato, rispetta le classi protette ed evita contenuti denigratori. Questo aspetto della valutazione impiega i set di dati RealToxicityPrompts e CrowS-Pairs. |
Prestazioni zero-shot
ChatGPT viene anche valutato per le sue prestazioni "zero-shot", ovvero la sua capacità di gestire attività senza esempi precedenti su attività NLP tradizionali come question answering, reading comprehension e riepilogo. Curiosamente, gli sviluppatori hanno notato regressioni delle prestazioni rispetto a GPT-3 su alcuni compiti. Questo fenomeno, noto come "tassa di allineamento", mostra che la procedura di allineamento basata su RLHF del modello potrebbe ridurre le prestazioni su attività specifiche.
Tuttavia, una tecnica di miscelazione di pre-training può mitigare sostanzialmente queste regressioni delle prestazioni. Durante l'addestramento del modello PPO tramite discesa del gradiente, gli aggiornamenti del gradiente vengono calcolati combinando i gradienti dei modelli SFT e PPO. Questo processo contribuisce a migliorare le prestazioni del modello su attività specifiche.
8. Limiti e miglioramenti in ChatGPT
ChatGPT, come qualsiasi modello AI, ha limitazioni nonostante le sue notevoli capacità.
Risposte scorrette o insensate.
ChatGPT, a volte, può produrre risposte plausibili ma scorrette o insensate. Ciò è dovuto principalmente al fatto che i suoi dati non sono completamente corretti. Come abbiamo discusso prima, ChatGPT riceverà varie fonti di dati durante l'addestramento, inclusi libri e Internet. Quindi, quali sono i colori dei semafori?
Se ci sono risposte sbagliate nella sua fonte di dati, come nero, bianco e giallo, allora anche ChatGPT potrebbe fornire risposte sbagliate.
Inoltre, quando il modello viene addestrato per essere più cauto, potrebbe rifiutarsi di rispondere a domande che può gestire correttamente. E durante l'addestramento supervisionato, la conoscenza del modello, ma non quella del dimostratore umano, influenza la risposta desiderata.
Sensibile alla modifica dell'input
Il modello è anche sensibile alle modifiche dell'input. Ciò significa che può produrre una risposta molto diversa una volta modificato il comando o chiesto di rispondere nuovamente alla domanda. Ad esempio, il modello risponderà correttamente a query che in precedenza sosteneva di non conoscere. O cambia la risposta da quella precedente (Sì a No). Inoltre, il pregiudizio dei dati e la nota eccessiva ottimizzazione dell'addestramento di ChatGPT hanno anche causato alcuni problemi. Potresti trovare frasi e affermazioni lunghe o eccessivamente utilizzate nell'output di ChatGPT, come riaffermare il suo rapporto con OpenAI.
In uno scenario ideale, ChatGPT farebbe domande di chiarimento per query ambigue. Tuttavia, i modelli attuali tendono a indovinare le intenzioni degli utenti. Sebbene siano stati compiuti sforzi per rifiutare richieste inopportune, il modello potrebbe comunque rispondere a istruzioni dannose o mostrare comportamenti prevenuti. Per combattere questo, OpenAI utilizza l'API Moderation per avvisare o bloccare determinati contenuti non sicuri, ma potrebbero ancora esistere falsi negativi e positivi.
Nonostante questi limiti, i progressi da GPT-3 a GPT-4 sono promettenti, mostrando la migliorata capacità del modello di generare testi plausibili e accurati. Guardando al futuro, ci si aspetta che questi miglioramenti continueranno e che le limitazioni diminuiranno con ogni nuova iterazione del modello GPT.
Conclusion
In conclusione, ChatGPT, prodotto dell'IA avanzata di GPT, opera attraverso una combinazione di architettura transformer, apprendimento per rinforzo dal feedback umano e diversi set di dati. Sfrutta l'elaborazione del linguaggio naturale per comprendere e generare testo simile all'uomo, facilitando interazioni coinvolgenti. Sebbene impressionante, è importante notare che le prestazioni del sistema non sono impeccabili e richiedono continue valutazioni di miglioramento. Nonostante i suoi limiti, ChatGPT è un'innovazione notevole nella tecnologia AI, spingendo i confini dell'interazione uomo-macchina.