¿Curioseando sobre la IA que está revolucionando las conversaciones? ¿Alguna vez te has preguntado cómo ChatGPT logra entender tus preguntas y elaborar respuestas coherentes? Sumérgete en los intrincados engranajes de esta tecnología innovadora, desde su base GPT hasta el papel del Procesamiento del Lenguaje Natural y más allá. Explora su rendimiento, limitaciones y posibilidades futuras. Desentaña la ciencia detrás de tu compañero conversacional digital, ChatGPT.
1. Sobre GPT y ChatGPT
1.1 Definiendo los modelos GPT
GPT, o Generative Pre-trained Transformer, es un desarrollo significativo en inteligencia artificial. Se utilizan en numerosas aplicaciones de IA generativa, incluyendo ChatGPT. Construidos sobre la arquitectura transformer, los modelos GPT pueden producir texto similar al humano y otros tipos de contenido como imágenes y música. Además, puedes usarlos para responder preguntas, tener conversaciones con ellos, manejar todo lo relacionado con texto, y más.
1.2 Introducción a ChatGPT
ChatGPT es un derivado de los modelos GPT, desarrollado por OpenAI. Opera de forma similar a su modelo hermano, InstructGPT, pero con un enfoque conversacional. La singularidad de esta diferencia otorga a ChatGPT una función interactiva, permitiéndole comunicarse con los usuarios y además completar respuestas a preguntas, identificación de errores, etc.
1.3 Comparando ChatGPT con motores de búsqueda
Motores de búsqueda como Google y motores computacionales como Wolfram Alpha también interactúan con los usuarios a través de un campo de entrada de texto de una línea. Sin embargo, mientras que la fortaleza de Google reside en ejecutar amplias búsquedas en bases de datos para proporcionar una serie de coincidencias y Wolfram Alpha está equipado para analizar preguntas relacionadas con datos y realizar cálculos, la fortaleza de ChatGPT es la capacidad de analizar consultas y entregar respuestas integrales basadas en una gran cantidad de información textual accesible digitalmente.
Por ejemplo, buscar "cómo desbloquear un iPhone" en motores de búsqueda como Google, obtendrás artículos con soluciones creadas por diferentes sitios web. Necesitas revisar estos artículos para obtener la solución.
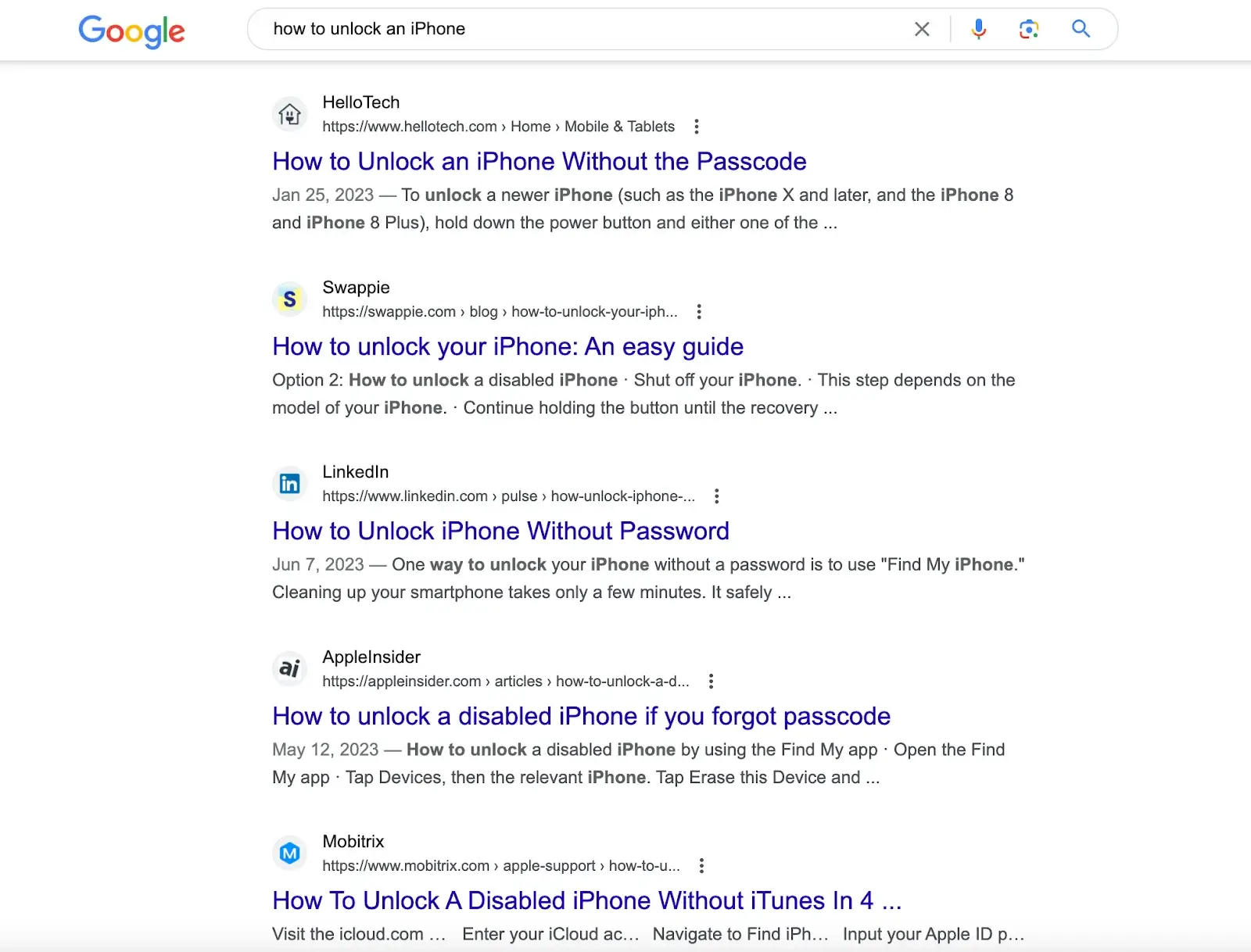
Pero si ingresas esta pregunta en ChatGPT, te dará directamente la respuesta. La respuesta proviene de su conjunto de datos de preentrenamiento, que también contiene el contenido en el enlace proporcionado por los motores de búsqueda.
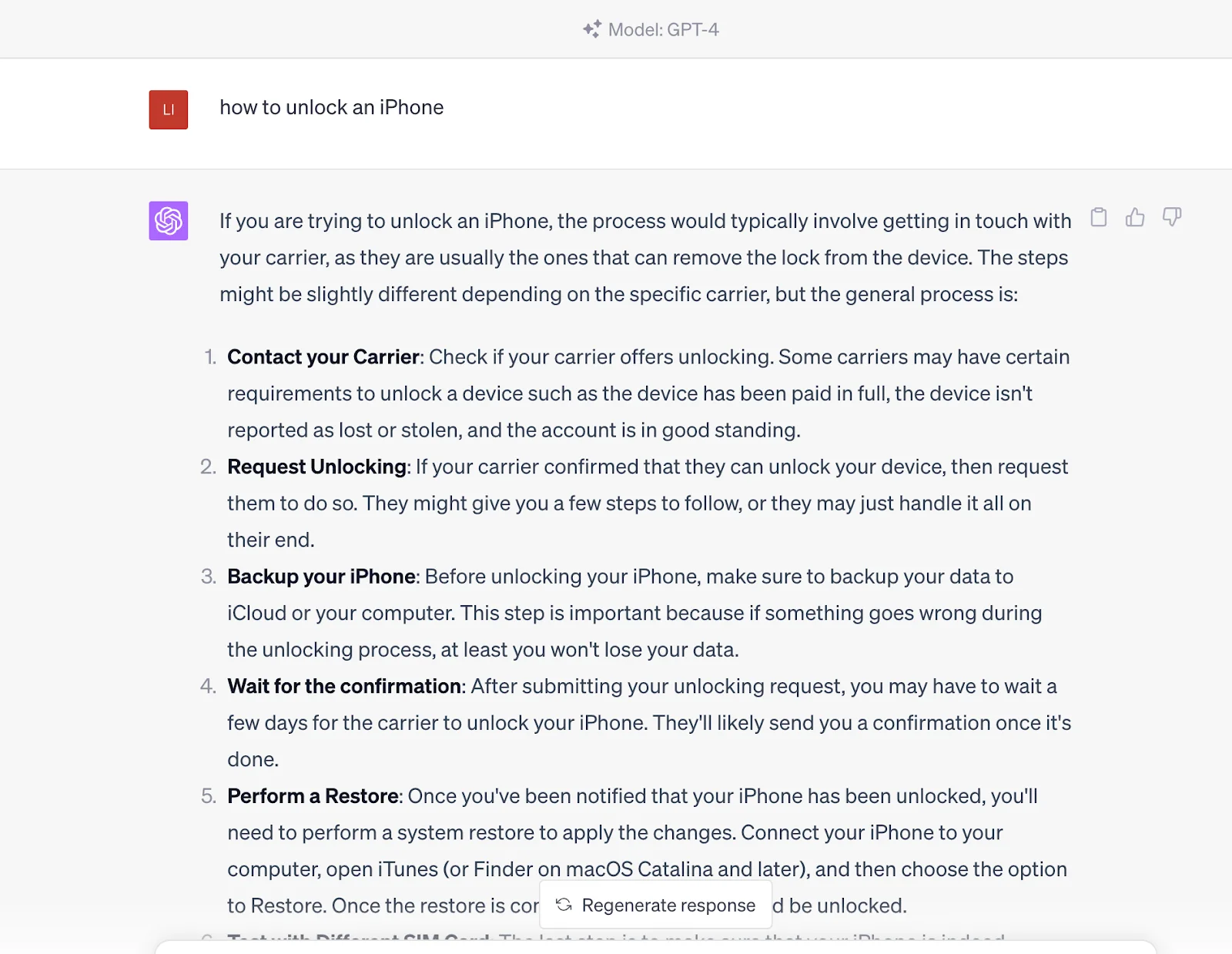
En otras palabras, te comunicas con una entidad conocedora que puede generar resultados de consulta en lugar de simplemente obtener esas fuentes de contenido a través de los motores de búsqueda. Sin embargo, cabe señalar que actualmente es inferior a los motores de búsqueda en términos de actualidad porque la información de ChatGPT se basa en los datos entrenados a partir de 2021.
2. ¿Cómo funciona ChatGPT?
El funcionamiento de ChatGPT se divide en dos fases: preentrenamiento, o recopilación de datos, e inferencia, o respuesta a indicaciones de usuario. Como discutimos antes, ChatGPT es similar a Google. Después de un extenso entrenamiento, ChatGPT puede entender preguntas y generar respuestas desde su base de datos. La única diferencia es que generará respuestas directas, no enlaces cuando envíes un mensaje.
ChatGPT emplea redes neuronales de aprendizaje profundo para generar texto similar al humano. Al igual que el cerebro humano hace predicciones y saca conclusiones basadas en conocimientos previos, ChatGPT se entrena con una inmensa cantidad de datos, o tokens, esencialmente unidades de texto que pueden representar palabras individuales o partes de palabras complejas.
A diferencia de los modelos de IA tradicionales entrenados mediante un enfoque supervisado que empareja cada entrada con una salida específica, ChatGPT utiliza un enfoque de preentrenamiento no supervisado. Aquí, el modelo aprende la estructura y los patrones inherentes en los datos de entrada sin tener una tarea particular en mente, comprendiendo así la sintaxis y semántica del lenguaje y permitiéndole generar texto significativo de manera conversacional. Este preentrenamiento es el poder transformador detrás del vasto conocimiento y capacidades de ChatGPT. El modelo puede desarrollar una amplia gama de respuestas basadas en la entrada recibida procesando cantidades colosales de datos mediante modelado de lenguaje basado en transformers. Esta metodología forma la base del conocimiento y habilidades conversacionales aparentemente ilimitados de ChatGPT.
Este entrenamiento comienza exponiendo al modelo a una gran cantidad de contenido escrito por humanos, desde libros y artículos hasta contenido de Internet. El modelo aprende así patrones y relaciones entre estos tokens, formando una red neuronal de aprendizaje profundo. Esta red, similar a un algoritmo de múltiples capas que imita el funcionamiento del cerebro humano, permite al modelo comprender y navegar las relaciones entre las palabras en una secuencia.
Lo que es notable acerca de ChatGPT es su habilidad para generar textos largos en lugar de simplemente predecir la siguiente palabra en una oración. OpenAI reveló su capacidad para entrenar a ChatGPT en este sentido a través del aprendizaje por refuerzo de la retroalimentación humana (RLHF), permitiéndole generar oraciones completas, párrafos e incluso cadenas de texto más largas para generar respuestas coherentes. Este entrenamiento involucra un modelo de recompensa en el que el entrenador clasifica las diferentes reacciones generadas por el modelo para ayudar a la IA a comprender qué constituye una buena respuesta.
Otra fortaleza que respalda el funcionamiento de ChatGPT es su enorme número de parámetros. GPT-3 tiene 175 mil millones y GPT-4 no reveló el número específico, pero se puede especular que puede ser más. Cada indicación que envía el usuario debe ser procesada por estos parámetros, y la salida se verá afectada por su valor y peso. Además, se ha incorporado aleatoriedad en estos parámetros para evitar respuestas mecánicas y repetitivas y mantener las cosas frescas. Por ejemplo, puedes usar la misma indicación y generar diferentes resultados.
3. Aprendizaje por refuerzo de la retroalimentación humana (RLHF)
Según OpenAI, el entrenamiento de ChatGPT se basa en gran medida en el método de aprendizaje por refuerzo de la retroalimentación humana (RLHF). Este método involucra una serie de pasos distintos para producir un modelo capaz de generar respuestas deseables.
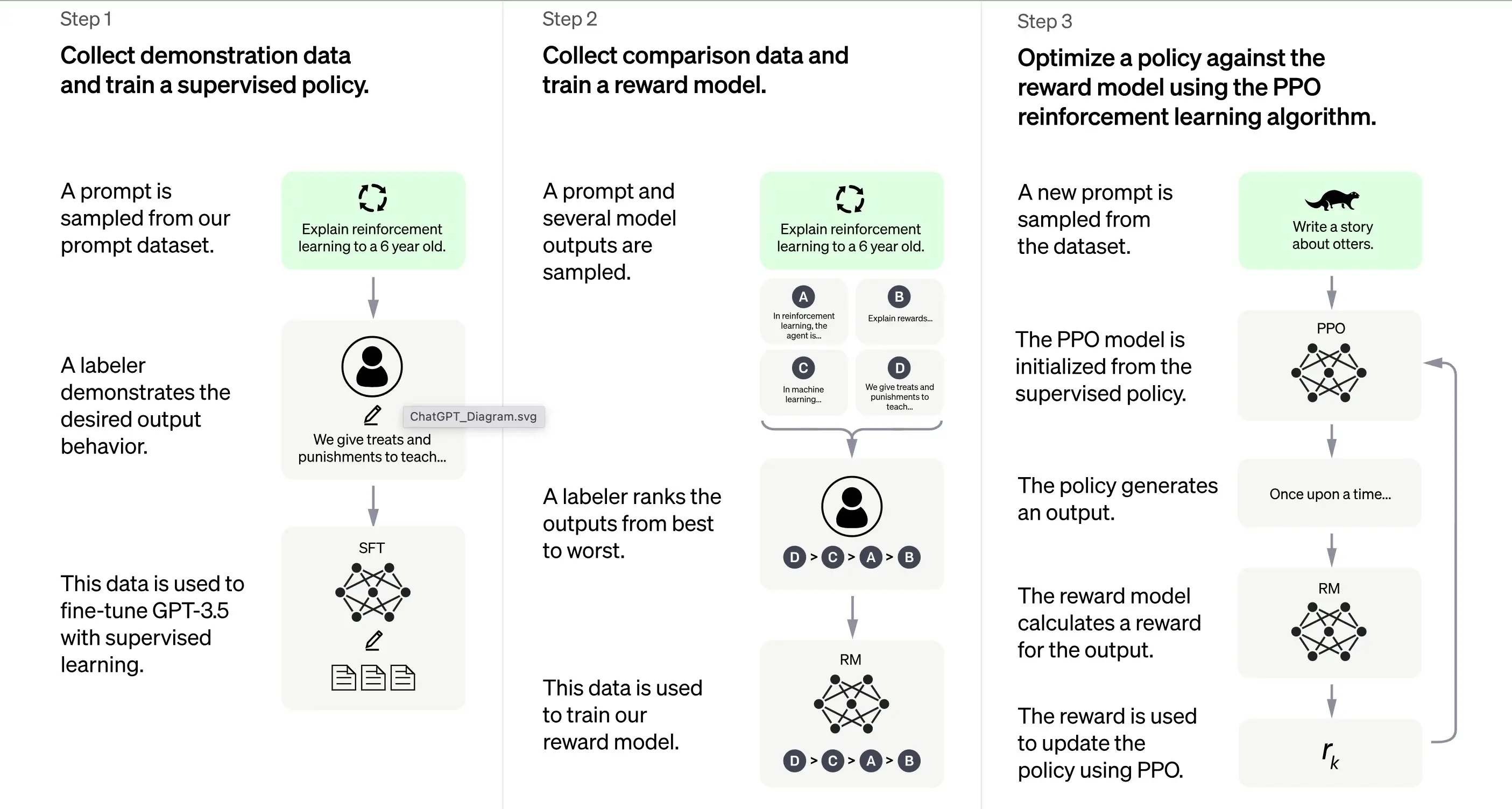
1. Entrenamiento inicial: ajuste fino supervisado (SFT)
El primer paso en el entrenamiento de ChatGPT es el ajuste fino supervisado (SFT). Esta fase involucra el uso de un conjunto de datos pequeño y cuidadosamente seleccionado compuesto por indicaciones y sus respuestas correspondientes producidas por calificadores humanos. El entrenamiento apunta a producir una salida correcta de alta calidad para ChatGPT. Según OpenAI, el modelo de entrenamiento en esta etapa se basa en la serie de modelos GPT-3.5.
El primer paso en el entrenamiento de ChatGPT es el ajuste fino supervisado (SFT), un modelo de política supervisado entrenado recopilando datos de demostración de calificadores humanos. ChatGPT utiliza dos fuentes de indicaciones: etiquetado directo de desarrolladores o solicitudes de API de OpenAI. El resultado es un conjunto de datos pequeño, de alta calidad y cuidadosamente seleccionado que se utiliza para ajustar finamente un modelo de lenguaje preentrenado. En lugar de ajustar finamente el modelo GPT-3 original, los desarrolladores de ChatGPT eligieron un modelo GPT-3.5 preentrenado, probablemente text-davinci-003. Esta decisión se tomó para crear un chatbot de propósito general como ChatGPT en la parte superior de un "modelo de código" en lugar de un modelo de texto puro.
Sin embargo, el modelo SFT aún puede no ser atento al usuario y sufrir desalineación. Para superar este problema, los desarrolladores ahora clasifican las diferentes salidas del modelo SFT para crear un modelo de recompensa.
2. Generar el modelo de recompensa
El paso está diseñado para generar una función objetivo, el modelo de recompensa. Este modelo puntúa las salidas del modelo SFT, con una puntuación proporcional a cuánto espera la clase que esas salidas cumplan las expectativas. Cuanto más se cumplan las expectativas, mayor será la puntuación y viceversa.
Los calificadores puntuarán manualmente la salida del modelo SFT de acuerdo con preferencias específicas y criterios comunes que acuerdan seguir. En última instancia, este proceso ayuda a crear un sistema automatizado que puede imitar las preferencias humanas.
La ventaja de este método es que es extremadamente eficiente. Debido a que los calificadores solo necesitan clasificar la salida en lugar de usar el modelo para producir contenido desde cero.
Su flujo de trabajo es aproximadamente el siguiente:
Seleccione una lista de indicaciones y el modelo SFT genere múltiples salidas (cualquier salida entre 4 y 9) para cada indicación.
El calificador clasifica las salidas de mejor a peor, creando un nuevo conjunto de datos etiquetados con las "clasificaciones" como etiquetas. Este conjunto de datos es aproximadamente diez veces mayor que el conjunto de datos seleccionados utilizado por el modelo SFT.
Este conjunto de datos luego entrenará el Modelo de Recompensa (RM). El modelo toma como entrada algunas salidas del modelo SFT y las clasifica en orden de preferencia.
Hasta ahora, hemos discutido cómo se entrena inicialmente el modelo mediante ajuste fino supervisado y luego se refina mediante un modelo de recompensa. Estos pasos forman los bloques de construcción básicos para entrenar ChatGPT. Sin embargo, el proceso continúa más allá de ahí. El sistema luego ingresa a una fase de mejora iterativa a través de una técnica llamada Optimización de Política Proximal.
3. Mejora iterativa: Optimización de política proximal (PPO)
La etapa final de entrenamiento implica aplicar la Optimización de Política Proximal (PPO). Esta técnica utiliza el modelo de recompensa como una función de valor para estimar el retorno esperado de una acción. Luego aplica una "función de ventaja", que representa la diferencia entre el retorno esperado y el real, para actualizar la política.
PPO es un algoritmo "on-policy" que aprende y actualiza la política actual en función de las acciones del agente y las recompensas recibidas. Este diseño ayuda a garantizar un aprendizaje estable al limitar el alcance del cambio en la política durante cada actualización, evitando que el modelo realice cambios drásticos que podrían interrumpir el proceso de aprendizaje.
El modelo PPO comienza con el modelo SFT e inicializa la función de valor a partir del modelo de recompensa. En este entorno, se presenta una indicación aleatoria y se espera una respuesta. Una vez que se da la respuesta, el episodio termina con la recompensa, determinada por el modelo de recompensa.
Aprendizaje continuo: el ciclo iterativo
Excepto que el primer paso solo ocurre una vez, las etapas de generación del modelo de recompensa y PPO se repiten en ciclos. Este enfoque iterativo permite la mejora continua del modelo con el tiempo. Con cada ciclo, el modelo recopila más datos de comparación, entrena un nuevo modelo de recompensa y establece una nueva política. Como resultado, el modelo mejora con el tiempo para alinearse con las preferencias humanas.
4. La arquitectura Transformer: una base para ChatGPT
4.1 Una descripción general
La base de ChatGPT es un tipo de red neuronal llamada arquitectura transformer. Una red neuronal, en esencia, emula la forma en que funciona el cerebro humano procesando información a través de múltiples capas de nodos interconectados. Imagina una orquesta sinfónica: cada músico tiene un rol, pasando melodías (información) de ida y vuelta, todo armonizando para crear música (una salida).
La arquitectura transformer se especializa en procesar secuencias de palabras aprovechando un mecanismo conocido como "autoatención". El mecanismo de autoatención es similar a la forma en que un lector podría revisar una oración o párrafo anterior para comprender el contexto de una palabra o frase nueva. El transformer evalúa todas las palabras en una secuencia para discernir el contexto y las relaciones entre ellas.
4.2 Capas del Transformer
La arquitectura transformer consiste en múltiples capas, cada una compuesta por dos subcapas principales: la capa de autoatención y la capa de avance. La capa de autoatención calcula la relevancia de cada palabra en una secuencia, mientras que la capa de avance aplica transformaciones no lineales a los datos de entrada. A través de esta configuración, el transformer aprende a comprender y navegar las relaciones entre las palabras en una secuencia.
4.3 Entrenando el Transformer
Durante el entrenamiento, al transformer se le proporcionan datos de entrada (una oración, por ejemplo) y se le pide que prediga un resultado en función de esa entrada. Luego, el modelo se actualiza de acuerdo con la proximidad de su predicción con la salida. De esta manera, el transformer refina su capacidad para comprender el contexto y las relaciones entre palabras en una secuencia.
Es como enseñarle nuevas palabras a un niño: le presentas nuevas palabras (entrada), hacen una suposición sobre el significado (predicción) y lo corriges si se equivocan (actualizando el modelo), ayudando así a su proceso de adquisición del lenguaje.
4.4 Desafíos al usarlo
Sin embargo, como cualquier herramienta poderosa, la arquitectura transformer conlleva desafíos. El potencial de que estos modelos generen contenido dañino o sesgado es una preocupación significativa, ya que pueden aprender e perpetuar inadvertidamente los sesgos presentes en los datos de entrenamiento. Piensa en un loro que imita lo que sea que escuche, independientemente de la idoneidad o corrección política de las palabras.
Los desarrolladores de estos modelos se esfuerzan por incorporar "rieles de seguridad" para mitigar estos riesgos. Aún así, estos rieles de seguridad podrían conducir a nuevos problemas debido a las diversas perspectivas e interpretaciones de los sesgos.
Como todos sabemos, el poder de generación de ChatGPT se beneficia de las grandes fuentes de datos de su modelo GPT, por lo que a continuación discutiremos los datos que brindan soporte a ChatGPT.
5. El papel de los diversos conjuntos de datos
5.1 ChatGPT: un producto de preentrenamiento extensivo
ChatGPT, que se apoya en la arquitectura GPT-3 (Generative Pre-trained Transformer 3), es un robusto modelo de lenguaje impulsado por el monumental conjunto de datos WebText2. Para entender la escala, imagina una biblioteca llena con más de 45 terabytes de datos de texto, equivalente a miles de veces el contenido de Wikipedia.
La escala colosal de WebText2 permite a ChatGPT aprender patrones y asociaciones entre palabras y frases a una escala inimaginable, permitiéndole generar respuestas coherentes y contextualmente relevantes.
5.2 Ajuste fino de ChatGPT para conversaciones
Si bien ChatGPT hereda su columna vertebral de la arquitectura GPT-3, ha sido ajustado y optimizado para aplicaciones conversacionales específicas. Esto resulta en una experiencia de interacción más atractiva y personalizada para los usuarios que interactúan con ChatGPT.
OpenAI, los creadores de ChatGPT, ha puesto a disposición un conjunto de datos único llamado Persona-Chat, diseñado específicamente para entrenar modelos de IA conversacionales. Este conjunto de datos consiste en más de 160,000 diálogos entre participantes humanos; a cada uno se le asigna una personalidad distintiva que describe sus intereses, personalidad y antecedentes. Es como si ChatGPT fuera un participante en miles de escenarios de juegos de roles, aprendiendo a adaptar sus respuestas al contexto y la personalidad de la conversación.
5.3 Una variedad de conjuntos de datos: la salsa secreta
Además de Persona-Chat, ChatGPT se ajusta finamente mediante el uso de varios otros conjuntos de datos conversacionales:
Cornell Movie Dialogs Corpus: Este conjunto de datos alberga diálogos entre personajes en guiones de películas, con más de 200,000 intercambios conversacionales entre más de 10,000 pares de personajes. Piensa en ChatGPT estudiando los guiones de cientos de películas, absorbiendo los matices lingüísticos de diferentes géneros y contextos.
Ubuntu Dialogue Corpus: Una recopilación de diálogos multifrase entre usuarios que buscan soporte técnico y el equipo de soporte de la comunidad Ubuntu. Estos datos pueden simular conversaciones de soporte técnico para ayudar a ChatGPT a aprender terminología específica y métodos de resolución de problemas. Imagina a ChatGPT sentándose en más de un millón de conversaciones de soporte técnico, aprendiendo la terminología específica y los enfoques de resolución de problemas.
DailyDialog: Este conjunto de datos comprende diálogos humanos sobre diversos temas, desde chats de la vida diaria hasta discusiones sobre problemas sociales. Usando esta base de datos, ChatGPT es como unirse a innumerables discusiones para comprender el tono, el estado de ánimo y los temas que componen la conversación humana cotidiana.
Además, ChatGPT aprovecha una gran cantidad de datos no estructurados que se encuentran en Internet, incluidos libros, sitios web y otras fuentes de texto. Esto amplía su comprensión de la estructura y los patrones del lenguaje, que se puede ajustar para aplicaciones específicas como análisis de sentimientos o gestión de diálogos.
5.4 La escala de ChatGPT
Aunque similar en enfoque a la serie GPT, ChatGPT es un modelo distinto con diferencias en arquitectura y datos de entrenamiento. ChatGPT comprende 1.5 mil millones de parámetros, menor en escala que los impresionantes 175 mil millones de parámetros de GPT-3, pero no obstante impresionante.
En resumen, los datos de entrenamiento para el ajuste fino de ChatGPT son predominantemente conversacionales, seleccionados para incluir diálogos entre humanos, permitiendo a ChatGPT generar respuestas naturales y atractivas. Piensa en su entrenamiento no supervisado como enseñarle a un niño a comunicarse exponiéndolo a una miríada de conversaciones y dejándolo encontrar patrones y darle sentido a todo.
Después del preentrenamiento, ChatGPT también necesita poder comprender preguntas y construir respuestas a partir de los datos. Esto involucra la fase de inferencia, respaldada por el procesamiento del lenguaje natural y la gestión del diálogo; veámoslo.
6. Procesamiento de lenguaje natural
El procesamiento del lenguaje natural (NLP) es un subcampo de la inteligencia artificial que se enfoca en permitir que las computadoras comprendan, interpreten y generen lenguaje humano. Es una tecnología crítica en la era digital actual, ya que subyace a muchas aplicaciones como análisis de sentimientos, chatbots, reconocimiento de voz y traducción de idiomas.
Las tecnologías de NLP pueden beneficiar significativamente a las empresas al automatizar tareas, mejorar el servicio al cliente y extraer valiosos conocimientos de fuentes de datos como comentarios de clientes y publicaciones en redes sociales.
Sin embargo, el lenguaje humano es inherentemente complejo y ambiguo, lo que presenta dificultades de interpretación por computadora. Para abordar esto, los algoritmos de NLP se entrenan con vastas cantidades de datos, lo que les permite reconocer patrones y aprender los matices del lenguaje. Estos algoritmos también deben refinarse y actualizarse constantemente para mantenerse al día con el uso del lenguaje en constante evolución y su contexto.
El NLP descompone las entradas de lenguaje (por ejemplo, oraciones o párrafos) en componentes más pequeños y analiza sus significados y relaciones para generar ideas o respuestas. Emplea varias técnicas, incluido el modelado estadístico, el aprendizaje automático y el aprendizaje profundo, para discernir patrones y aprender de grandes cantidades de datos, interpretando y generando lenguaje con precisión.
ChatGPT es un ejemplo práctico de NLP en acción. Está diseñado para participar en conversaciones de múltiples turnos con los usuarios que se sienten naturales y atractivas. Esto implica utilizar algoritmos y técnicas de aprendizaje automático para comprender el contexto de una conversación y mantenerlo durante múltiples intercambios con el usuario.
Esta capacidad de mantener un contexto durante una conversación prolongada se conoce como gestión de diálogo. Permite que los programas informáticos interactúen con las personas de una manera que se siente más como una conversación que como una serie de interacciones aisladas. Este aspecto del NLP es vital, ya que genera confianza y compromiso con los usuarios, lo que lleva a mejores resultados tanto para el usuario como para la organización que utiliza el programa.
7. Evaluación del rendimiento de ChatGPT
Tres criterios principales
La evaluación de ChatGPT es un paso crucial para garantizar su efectividad y confiabilidad. Dado que el modelo se entrena en función de las interacciones humanas, su evaluación también depende predominantemente de la opinión humana, en la cual los calificadores de calidad evalúan las salidas del modelo.
Para evitar que el modelo se ajuste en exceso al juicio de los calificadores que participaron en la fase de entrenamiento, la evaluación emplea un conjunto de pruebas que comprende indicaciones de la base de usuarios de OpenAI que no están incluidas en los datos de entrenamiento. Esto permite una evaluación imparcial del rendimiento del modelo en escenarios del mundo real.
La evaluación del modelo se realiza en tres criterios principales:
Criterios | Explicación |
|---|---|
Utilidad | Esto mide la capacidad del modelo para cumplir con las instrucciones del usuario e intuir las intenciones del usuario. |
Veracidad | Esto evalúa la propensión del modelo a las "alucinaciones", que se refiere a su tendencia a inventar hechos. Para ello se utiliza el conjunto de datos de TruthfulQA. |
inocuidad | Los evaluadores de calidad evalúan si el resultado del modelo es apropiado, respeta las clases protegidas y evita el contenido despectivo. Este aspecto de la evaluación emplea los conjuntos de datos RealToxicityPrompts y CrowS-Pairs. |
Rendimiento de tiro cero
ChatGPT también se evalúa por su rendimiento de "tiro cero", es decir, su capacidad para manejar tareas sin ejemplos previos en tareas tradicionales de NLP como respuesta a preguntas, comprensión de lectura y resumen. Curiosamente, los desarrolladores notaron regresiones de rendimiento en comparación con GPT-3 en algunas tareas. Este fenómeno, conocido como un "impuesto de alineación", muestra que el procedimiento de alineación basado en RLHF del modelo puede reducir el rendimiento en tareas específicas.
Sin embargo, una técnica de mezcla de preentrenamiento puede mitigar sustancialmente estas regresiones de rendimiento. Durante el entrenamiento del modelo PPO a través del descenso de gradiente, las actualizaciones de gradiente se calculan combinando los gradientes de los modelos SFT y PPO. Este proceso ayuda a mejorar el rendimiento del modelo en tareas específicas.
8. Limitaciones y mejoras en ChatGPT
ChatGPT, como cualquier modelo de IA, tiene limitaciones a pesar de sus notables capacidades.
Respuestas incorrectas o sin sentido.
ChatGPT, en ocasiones, puede producir respuestas verosímiles pero incorrectas o sin sentido. Esto se debe principalmente a que sus datos no son completamente correctos. Como discutimos antes, ChatGPT recibirá varias fuentes de datos durante el entrenamiento, incluidos libros e Internet. Entonces, ¿cuáles son los colores de los semáforos?
Si hay respuestas incorrectas en su fuente de datos, como negro, blanco y amarillo, entonces ChatGPT también puede dar respuestas incorrectas.
Además, cuando se entrena al modelo para ser más cuidadoso, puede negarse a responder preguntas que puede manejar correctamente. Y durante el entrenamiento supervisado, el conocimiento del modelo, pero no el del demostrador humano, influye en la respuesta deseada.
Sensible a modificaciones de entrada
El modelo también es sensible a modificaciones de entrada. Esto significa que puede producir una respuesta muy diferente una vez que ajustas el comando o le pides que responda la pregunta nuevamente. Por ejemplo, el modelo responderá correctamente consultas que previamente afirmó no conocer. O cambie la respuesta de la anterior (Sí a No). Además, el sesgo de datos y la conocida sobrealimentación del entrenamiento de ChatGPT también causaron algunos problemas. Puedes encontrar frases y declaraciones prolongadas o sobreutilizadas en la salida de ChatGPT, como reafirmar su relación con OpenAI.
En un escenario ideal, ChatGPT debería hacer preguntas aclaratorias para consultas ambiguas. Sin embargo, los modelos actuales tienden a adivinar las intenciones del usuario en su lugar. Si bien se han realizado esfuerzos para rechazar solicitudes inapropiadas, el modelo aún puede responder a instrucciones dañinas o exhibir un comportamiento sesgado. Para combatir esto, OpenAI emplea la API de Moderación para advertir o bloquear cierto contenido inseguro, pero aún pueden existir falsos negativos y positivos.
A pesar de estas limitaciones, los avances de GPT-3 a GPT-4 son prometedores, mostrando la mejorada capacidad del modelo para generar texto plausible y preciso. Mientras miramos hacia el futuro, la expectativa es que estas mejoras continuarán y las limitaciones disminuirán con cada nueva iteración del modelo GPT.
Conclusión
En conclusión, ChatGPT, un producto del IA avanzada de GPT, funciona a través de una combinación de arquitectura transformer, aprendizaje por refuerzo de retroalimentación humana y diversos conjuntos de datos. Aprovecha el procesamiento de lenguaje natural para comprender y generar texto similar al humano, facilitando interacciones atractivas. Aunque impresionante, es importante tener en cuenta que el rendimiento del sistema no es perfecto y requiere evaluaciones de mejora continua. A pesar de sus limitaciones, ChatGPT es una innovación notable en tecnología de IA, empujando los límites de la interacción máquina-humano.